AI Causal Analysis (Alpha)
AI Causal Analysis hesaplayıcısı, hangi vaka niteliklerinin hedef bir sonucu en güçlü şekilde yönlendirdiğini keşfetmek için makine öğrenimini kullanır. Sadece korelasyon göstermek yerine, tanımladığınız sonuca bir vakanın uyup uymamasında en büyük istatistiksel etkiye sahip özellikleri izole eder - böylece "ne oluyor"dan "neden oluyor"a geçebilirsiniz.
Alfa Özelliği: Bu hesaplayıcı mindzie Alfa Programı'nın bir parçasıdır. Kiracınız için PreRelease özelliğinin etkinleştirilmesini gerektirir. Daha fazla bilgi için Alfa Özellikler sayfasına bakınız.
Genel Bakış
AI Causal Analysis aşağıdaki gibi sorulara yanıt verir:
- Neden bazı vakaların tamamlanması 7 günden fazla sürüyor?
- Hangi nitelikler bir faturanın geç ödenmesini daha olası kılar?
- SLA'yı ihlal eden vakaları ihlal etmeyenlerden ayıran nedir?
- Hangi tesisler, ekipler veya ürün kategorileri belirli bir sonucu en çok etkiler?
Sonucu (açıklamak istediğiniz vakaları) tanımlarsınız, hesaplayıcıyı bir dizi girdi sütununa yönlendirirsiniz ve bu vakaların sonuç grubuna girmesinden en sorumlu faktörlerin sıralı bir listesini döndürür.
Root Cause Analysis ile karşılaştırma
AI Causal Analysis, mevcut Root Cause Analysis hesaplayıcısı ile aynı amacı paylaşır ancak çok daha titiz bir yaklaşım izler:
| Yetenek | Root Cause Analysis | AI Causal Analysis |
|---|---|---|
| Tek nitelikli sürücüleri bulur | Evet | Evet |
| Çok nitelikli birleşimleri bulur (kural başına en fazla 3 nitelik) | Hayır | Evet |
| Korelasyonu nedensellikten ayırt eder | Hayır | Evet (nedensel grafik + propensity ayarlaması) |
| Güven aralıklarını raporlar | Hayır | Evet (her kuralda %95 Wilson CI) |
| Çoklu test için düzeltme yapar | Hayır | Evet (Benjamini-Hochberg FDR) |
| Sayısal / tarih / zaman niteliklerini işler | Hayır (yalnızca metinler) | Evet (sonuca duyarlı gruplama) |
| Sürücü başına sade dilde anlatım | Hayır | Evet |
Hızlı tek nitelikli tarama için Root Cause Analysis'ı, ciddi herhangi bir soruşturma için - özellikle birisi sonuca göre harekete geçecekse - AI Causal Analysis'ı kullanın.
Hesaplayıcıyı Nasıl Eklersiniz
- mindzieStudio'da bir defter açın
- Add Calculator'a tıklayın ve AI Causal Analysis (Alpha) seçeneğini seçin
- Sonuç ve girdi sütunlarını yapılandırın (aşağıya bakınız)
- Create'e tıklayın
Yapılandırma
Başlık
Hesaplayıcının görünen adı. Varsayılan olarak AI Causal Analysis (Alpha) gelir - yanıtladığınız soruya özel bir şeyle değiştirin, örneğin Neden YBÜ yatışları uzun sürüyor? veya Geç Ödemenin Sürücüleri.
Açıklama
İsteğe bağlı serbest metin notlar. İş sorusunu, analizin çalıştırıldığı tarih aralığını veya talep eden paydaşı belgelemek için yararlıdır.
Sonuç Tanımı
Sonuç, açıklamak istediğiniz vakalar grubudur. Hesaplayıcı bu vakaları veri setinin geri kalanıyla karşılaştırır ve hangi girdi sütunlarının iki grubu en iyi şekilde ayırdığını belirler.
Sonucu tanımlamak için üç mod mevcuttur:
Filter Mode
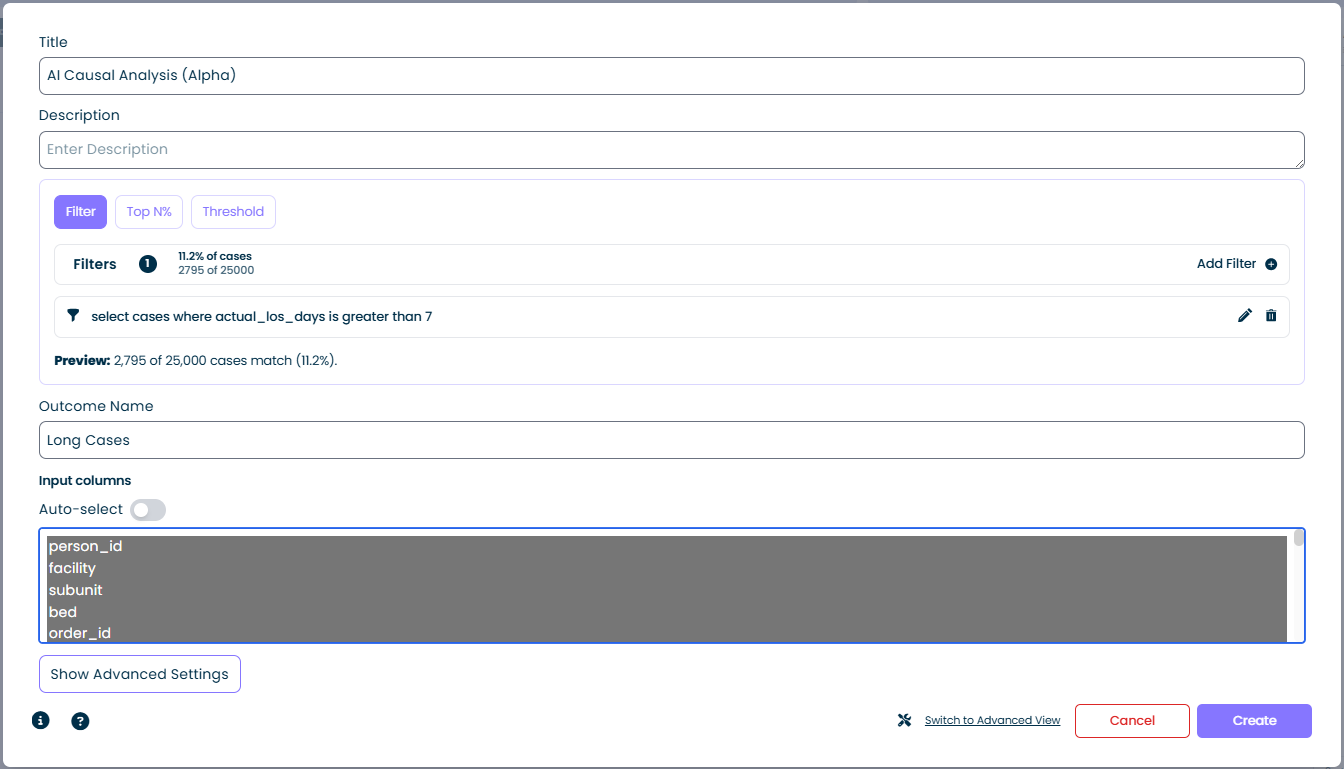
Filter sekmesini seçin ve bir veya daha fazla filtre ifadesi ekleyin. Hesaplayıcı filtreyle eşleşen vakaları "sonuç" grubu olarak ele alır.
- Cases matching: yüzde ve ham sayı olarak gösterilir, örneğin
Vakaların %11,2'si / 25.000 vakadan 2.795'i - Add Filter: standart filtre oluşturucuyu açar - herhangi bir sayıda koşulu birleştirin
- Preview: filtreyi oluştururken canlı olarak güncellenir, böylece hesaplayıcıyı çalıştırmadan önce seçimi doğrulayabilirsiniz
Filter modu en esnek seçenektir. mindzie filtresi olarak ifade edebileceğiniz herhangi bir koşul (süre eşikleri, nitelik eşleşmeleri, aktivite varlığı vb.) sonuç olabilir. Yukarıdaki ekran görüntüsünde, select cases where actual_los_days is greater than 7 filtresi sonuç olarak "Uzun Vakalar"ı tanımlar.
Top N% Mode
Sayısal bir niteliğin en yüksek (veya en düşük) değerlerini sonuç olarak kullanmak için Top N% sekmesini seçin. Zor bir eşik seçmek zorunda kalmadan "en kötü vakaları" veya "en iyi performans gösterenleri" açıklamak istediğinizde yararlıdır. Örnek: döngü süresine göre vakaların en üst %10'u.
Threshold Mode
Sonucu bir nitelik üzerinde tek bir sayısal kesme değeriyle tanımlamak için Threshold sekmesini seçin. Değerin üstünde (veya altında) olan herhangi bir vaka sonuç grubunun bir parçası olur. Örnek: invoice_amount değerinin 50.000'i aştığı vakalar.
Sonuç Adı
Sonuçlarda sonuç grubunu tanımlayan kısa bir etiket, örneğin Uzun Vakalar, Geç Ödemeler veya SLA İhlali. Bu ad, sonuç grubuna atıfta bulunulan analiz çıktısı boyunca görünür.
Girdi Sütunları
Modelin sonucun sürücülerini ararken kullanmasına izin verilen sütunlar.
- Sütun listesi: veri setindeki her vaka niteliği gösterilir. Analize dahil etmek için bir veya daha fazlasını seçin. Seçildiğinde sütunlar vurgulanır.
- Auto-select anahtarı: etkinleştirildiğinde mindzie, veri seti şemasına dayalı olarak otomatik şekilde makul bir varsayılan girdi sütunları setini seçer. Tam manuel kontrol istediğinizde bunu kapatın - örneğin, sonuçla önemsiz ölçüde ilişkili bir sütunu (örneğin cevabı sızdıran bir kimlik) hariç tutmak için.
Girdi sütunlarını seçme ipuçları:
- Sonucun alt akışında olan sütunları hariç tutun.
discharge_dateactual_los_daysdeğerini hesaplamak için kullanılıyorsa, içgörü katmadan sonuçları domine edecektir. - Belirli bir varlığa özgü etkileri istemediğiniz sürece yüksek kardinaliteli tanımlayıcıları (
person_id,order_id) hariç tutun. - Bağlamsal nitelikleri (tesis, ürün kategorisi, öncelik, bölge) dahil edin - ilginç sürücüler genellikle buradadır.
Gelişmiş Ayarları Göster
Arama için ek ayarlama seçenekleri açar. Varsayılanlar çoğu analiz için iyi çalışır - yalnızca belirli bir nedeniniz olduğunda bunları geçersiz kılın.
| Ayar | Varsayılan | Amaç |
|---|---|---|
| Beam width | 50 | Her arama derinliğinde kaç aday kuralın tutulacağı. Daha yüksek = daha kapsamlı, daha yavaş. |
| Max rule depth | 3 | İzin verilen en uzun kural. 3, A AND B AND C formundaki kurallar anlamına gelir. |
| Min cases per rule | 30 | Bundan daha az vakayı etkileyen kurallar, harekete geçirilemeyecek kadar küçük kabul edilerek atılır. |
| Min lift | 1.2 | Kural içi sonuç oranı, temel oranı en az bu faktör kadar aşmalıdır (1.2 = temelden en az %20 daha yüksek). |
| FDR alpha | 0.05 | Kural araması genelinde yanlış keşifleri kontrol etmek için Benjamini-Hochberg anlamlılık eşiği. |
| Max drivers returned | 20 | Tam tablo görünümünde gösterilen kural sayısının üst sınırı. |
| Redundancy Jaccard | 0.9 | Vaka kümeleri bu oranın üzerinde örtüşen kurallar yinelenen olarak kabul edilir ve filtrelenir. |
| Sampling threshold | 2.000.000 vaka | Bu boyutun üzerindeki veri setleri Floyd'un kombinasyon algoritması kullanılarak deterministik olarak örneklenir. Çıktı WasSampled = true ve gerçek örnek boyutunu raporlar. |
Gelişmiş Görünüme Geç
Her model parametresi üzerinde ince ayar kontrolü için düzenleyiciyi gelişmiş moda geçirir. Burada gösterilen rehberli görünüm, kullanım durumlarının büyük çoğunluğu için yeterlidir.
Tipik İş Akışı
- Soruyu çerçeveleyin - hangi sonucu açıklamak istediğinize karar verin. "Vakaları yavaşlatan nedir?" sorusu,
case_duration > 7 günFilter sonucuna dönüşür. - Sonucu tanımlayın - Filter, Top N% veya Threshold modunu kullanın. Preview yüzdesinin makul göründüğünü doğrulayın (çok az vaka kararsız sonuçlar üretir; çok fazla vaka ise sonucun gerçekten ayırt edici olmadığı anlamına gelir).
- Sonucu adlandırın - sonuçlarda ve raporlarda iyi okunacak kısa ve öz bir etiket seçin.
- Girdi sütunlarını seçin - Auto-select ile başlayın, ardından cevabı sızdıran veya gürültü ekleyen sütunları budayın.
- Create - hesaplayıcıyı çalıştırın. Sonuç, sonucun sıralı sürücülerini ortaya çıkarır.
- Yorumlayın - en önemli sürücüleri inceleyin, gerekirse sonucu veya girdi setini iyileştirin ve yeniden çalıştırın.
Örnek
Bir hastane operasyon ekibi, bazı yatarak tedavi sürelerinin neden 7 günden uzun sürdüğünü anlamak istiyor.
| Ayar | Değer |
|---|---|
| Başlık | AI Causal Analysis (Alpha) |
| Filter modu | select cases where actual_los_days is greater than 7 |
| Preview | 25.000 vakadan 2.795'i eşleşiyor (%11,2) |
| Sonuç Adı | Uzun Vakalar |
| Girdi sütunları | facility, subunit, bed, order_id, ... (otomatik seçildi) |
Çalıştırıldıktan sonra, hesaplayıcı tesisin, alt birimin ve bakım niteliklerinin hangi kombinasyonlarının uzun süreli vakaları normal süreli vakalardan en güçlü şekilde ayırt ettiğini raporlar. Bu, ekibi her niteliği manuel olarak araştırmak zorunda bırakmak yerine, araştırılacak belirli birimlere ve iş akışlarına yönlendirir.
Sonuçları Yorumlama
Her önemli sürücü için hesaplayıcı, sade dilde bir anlatım paragrafı ve bulgunun gücünü tanımlayan bir kanıt rozeti üretir:
| Rozet | Anlam | Nasıl hareket edilir |
|---|---|---|
| Causal | Hem nedensel grafik sinyali hem de karıştırıcı ayarlamalı etki pozitiftir. | En güçlü uygulanabilir kanıt - müdahale için önceliklendirilmesi güvenlidir. |
| Likely Causal | Nedensel grafik kuralı sonuca bağlar, ancak karıştırıcılar için ayarlama yapıldığında etki zayıflar. | Umut verici - harekete geçmeden önce daha fazla araştırın. |
| Associated | Etki ayarlamadan sonra hayatta kalır, ancak grafik kuralı sonuca doğrudan bir yol üzerinde konumlandırmaz. | Gerçek bir ilişki, ancak muhtemelen dolaylı - gerçek sürücünün bir vekili olabilir. |
| Correlational | Bir ilişki vardır ancak nedensel bir ilişkiyi doğrulayamayız. | Yalnızca tanısal sinyal - tek başına harekete geçmeyin. |
Bir Causal kuralı için örnek anlatım:
Channel = Online, Non-First Contact Resolution'ın olası bir sürücüsüdür. Bu kuralla eşleşen vakalar, %29,0 temel oranına karşı %46,1 sonuç oranı gösterir (1,59x, %95 CI 1,51x - 1,68x, p < 0,001). Toplam 2.518 vakayı kapsar ve tüm Non-First Contact Resolution oluşumlarının %34,7'sini oluşturur. Etki, diğer üst sürücüler için ayarlamadan sonra hayatta kalmış ve öğrenilen nedensel grafikte sonuca doğrudan bir yol üzerinde yer almaktadır.
Full Table görünümü, kapsam, lift, güven aralığı, ayarlanmış etki, p-değeri ve aramadan ve anlamlılık filtresinden hayatta kalan her kural için rozet içeren tam sıralı listeyi ekler.
Algoritma Nasıl Çalışır
AI Causal Analysis beş aşamalı bir boru hattı çalıştırır. Her aşamanın belirli bir görevi vardır ve bütünün milyonlarca vakalık veri setlerinde bile saniyeler içinde tamamlanması için tasarlanmıştır.
1. Hazırlık ve gruplama
- Hesaplayıcı, sonuç grubunuzdaki vakaları alır ve onları
1olarak etiketler; diğer hepsi0olarak etiketlenir. Bu, çıktıda gördüğünüz temel orandır (baseline rate). - Kategorik nitelikler (metinler, boolean'lar, düşük kardinaliteli tam sayılar) doğrudan kullanılır. Her farklı değer bir aday literal olur (örn.
facility = Memorial). - Sayısal ve tarih/zaman nitelikleri, MDL-optimal, sonuca duyarlı bir gruplayıcı ile gruplanır. Eşit genişlikte veya eşit sıklıkta gruplar seçmek yerine, gruplayıcı sonuç vakalarını sonuç olmayanlardan en iyi şekilde ayıran kesme noktalarını seçer, ardından Minimum Tanım Uzunluğu (Minimum Description Length) ilkesini kullanarak grup sayısını otomatik olarak seçer. Bu,
actual_los_daysgibi sayısal bir sütunu küçük bir anlamlı kovalar setine (örn.<= 3 gün,4 - 7 gün,> 7 gün) dönüştürür.
2. Bitmap indeksleme
Her literal bir bitset olarak saklanır - vaka başına bir bit, vaka literale eşleşiyorsa 1. Literalleri AND ile birleştirmek hızlı bir bitwise kesişimi haline gelir:
facility = Memorial AND priority = High,bitset_A & bitset_Bolarak hesaplanır.- Bir aday kuralın kapsamı, sonuç sayısı ve lift'i, kural derinliğinden bağımsız olarak mikrosaniyeler içinde değerlendirilebilir.
Min cases per rule'dan daha azını kapsayan literaller, arama başlamadan önce atılır.
3. Beam search alt grup keşfi
Hesaplayıcı kural alanını genişliğine göre dolaşır:
- Derinlik 1: her tek literali değerlendirin. Her birini bir kalite ölçüsü (lift ve Ağırlıklı Göreceli Doğruluk - Weighted Relative Accuracy) kullanarak puanlayın ve en iyi
Beam width'ini (varsayılan 50) tutun. - Derinlik 2: tutulan her kuralı,
A AND Bgibi birleşimler oluşturmak için her uyumlu diğer literalle genişletin. Hepsini puanlayın ve tekrar en iyiBeam width'ini tutun. - Derinlik 3: bir kez daha tekrar edin.
Max rule depth'te durun.
Min lift veya Min cases per rule'un altına düşen kurallar her seviyede budanır.
Aramadan sonra, bir Jaccard artıklık filtresi neredeyse yinelenen kuralları kaldırır: iki kural esasen aynı vakaları kapsıyorsa (örtüşme Redundancy Jaccard'ın üzerinde, varsayılan 0,9), yalnızca daha iyisi tutulur.
4. İstatistiksel anlamlılık
Hayatta kalan her kural için hesaplayıcı şunları hesaplar:
- Risk oranı (kural içi sonuç oranının temel orana bölünmesi) ve onun %95 Wilson güven aralığı, normal yaklaşımın başarısız olduğu küçük ve aşırı olasılıklar için iyi davranışlıdır.
- Kuralın hiçbir etkisi olmadığı sıfır hipotezi altında bir p-değeri.
- Test edilen tüm kurallar genelinde bir Benjamini-Hochberg FDR düzeltmesi.
FDR alpha(varsayılan 0,05) beklenen yanlış keşif oranını ayarlar. FDR'den hayatta kalmayan kurallar raporlanmaz, bu da aramanın sizi sahte bulgularda boğmasını engelleyen şeydir.
5. Nedensel karar verme
Tek başına anlamlılık size hala sadece bir ilişki olduğunu söyler. Bir kuralın Causal rozeti alıp almayacağına iki ekstra sinyal karar verir:
- Nedensel grafik sinyali - niteliklerden ve sonuçtan öğrenilen hafif bir Bayes yapısal skoru. Şunu sorar: bu kural öğrenilen grafikte sonuca doğrudan bir yol üzerinde mi, yoksa bir karıştırıcı aracılığıyla sadece dolaylı bir yol üzerinde mi?
- Propensity skor ayarlaması - ridge düzenli bir lojistik regresyon, diğer tüm üst sürücüler verildiğinde her vakanın kurala eşleşme olasılığını modeller. Kuralın etkisi daha sonra bu eğilim ile ağırlıklandırıldıktan sonra yeniden tahmin edilir. Etki sıfıra çökerse, kural yalnızca diğer sürücüler için bir vekildi; devam ederse, bağımsız açıklama gücüne sahiptir.
Karar verici, her iki sinyali yukarıda tanımlanan dört kanıt rozetinde birleştirir.
6. Anlatım oluşturma
Son adım, kart görünümünde gösterilen sade dildeki paragrafı oluşturur. Kural tanımını, kural içi ve temel sonuç oranlarını, risk oranını ve güven aralığını, p-değerini, kapsamı ve kanıt rozetini, istatistiksel olmayan bir okuyucu için doğal okunacak şekilde ayarlanmış bir cümle yapısına örer.
Performans
Geliştirme makinesinde ölçülmüştür:
| Veri Seti | Süre |
|---|---|
| 100.000 vaka x 4 sütun | 1 saniyeden az |
| 200.000 vaka x 20 sütun | 2 saniyeden az |
| 1.000.000 vaka x 50 sütun | yaklaşık 3 saniye |
Örnekleme eşiğinin üzerindeki veri setleri (varsayılan 2.000.000 vaka), Floyd'un kombinasyon algoritması kullanılarak deterministik olarak örneklenir. Bu gerçekleştiğinde çıktı WasSampled = true olarak işaretlenir ve sonucun yeniden üretilebilir olması ve örneklemenin görünür olması için gerçek örnek boyutu raporlanır.
Bilinen Sınırlamalar (v1)
- Yalnızca ikili sonuçlar. Çok sınıflı sonuçlar (örneğin hızlı / orta / yavaş) bu sürümde desteklenmez. İki yönlü bölmeleri ayrı analizler olarak tanımlayın.
- Henüz vaka başına açıklama yok. v1, "bu sonucu veri seti genelinde ne yönlendiriyor?" sorusunu yanıtlar. Gelecekteki bir sürüm "bu belirli vaka neden yanlış gitti?" panellerini ekleyecektir.
- Zamansal kayma analizi yok. Sürücüler çeyrekler arasında değişirse, v1 bunları zaman içinde bölmeyecektir. Bu önemli olduğunda hesaplayıcıyı her zaman dilimi üzerinde ayrı ayrı çalıştırın.
- Sayısal gruplama sonuca duyarlıdır. Sabit, insan tarafından seçilen gruplar istiyorsanız, hesaplayıcıyı çalıştırmadan önce sütunu bir zenginleştirme ile önceden kovalayın.
Kullanım Senaryoları
Performans Sürücüleri
SLA'yı ihlal eden, bütçeyi aşan veya beklenen süresini aşan vakalarla en çok ilişkili nitelikleri belirleyin. Süre veya KPI zenginleştirmesi üzerine kurulu bir Filter sonucu ile iyi çalışır.
Sonuç Analizi
Başarılı vakaları başarısız veya iptal edilenlerle karşılaştırın. Bir durum veya sonuç niteliği üzerinde bir Filter sonucu kullanarak hangi yukarı akış niteliklerinin her sonucu öngördüğünü görün.
Risk ve Uyum
Bir uygunluk veya kontrol zenginleştirmesi tarafından işaretlenen vakalara hesaplayıcıyı yönlendirerek hangi bağlamsal faktörlerin uyum başarısızlıklarıyla ilişkili olduğunu öğrenin.
En İyi Performans Gösterenlerin Analizi
En iyi vakalarınızı, ekiplerinizi veya müşterilerinizi diğerlerinden neyin farklı kıldığını açıklamak için Top N% modunu kullanın. İçgörüleri süreç tasarımına veya eğitime geri besleyin.
İpuçları
- Basit başlayın. İki veya üç koşullu iyi seçilmiş bir Filter ve otomatik seçilen girdiler genellikle en net sonuçları üretir.
- Preview yüzdesini izleyin. Sonuç grubu veri setinin ~%2'sinden az veya ~%50'sinden fazla ise, analizi yorumlamak zorlaşır. Grup anlamlı bir azınlık olana kadar filtreyi ayarlayın.
- Girdi sütunlarında yineleyin. Sonuçları içgörü olmaksızın domine eden sütunları (sonucu sızdıran kimlikler, zaman damgaları) kaldırın, ardından yeniden çalıştırın.
- Sonuçları özel olarak adlandırın. Sonuçları paydaşlarla paylaştığınızda veya raporlara derlediğinizde
Uzun Vakalar,Outcome 1'den daha iyidir. - Decision Tree hesaplayıcısı ile eşleştirin aynı soru üzerinde ikinci bir görüş için. Decision Tree dallanma yapısını gösterir; AI Causal Analysis genel özellik etkisini sıralar.
İlgili Hesaplayıcılar
- Decision Tree - vakaları sonuç gruplarına ayıran niteliklerin nasıl olduğunu gösteren tamamlayıcı görünüm
- Root Cause Analysis - KPI sapmaları için deterministik istatistiksel temel neden keşfi
- Case Outcome By Category - sonuç oranlarını seçilen bir kategorik nitelik boyunca karşılaştırır
İlgili Özellikler
- AI Studio (Alpha) - Feature Impact ve Root Cause dahil olmak üzere daha geniş kestirimsel analiz çalışma alanı
- Alfa Özellikleri Genel Bakış - mindzie Alfa Programındaki özelliklerin tam listesi
Geri Bildirim Sağlama
AI Causal Analysis bir Alfa özelliğidir ve geri bildiriminiz nasıl evrileceğini doğrudan şekillendirir:
- E-posta: support@mindzie.com
- Konu:
Alpha Feedback: AI Causal Analysisifadesini dahil edin - İçerik: kullandığınız sonuç tanımı, girdi sütunları, neyi beklediğiniz ve ne aldığınız