Begrip van mindzie's Dual Dataset Architectuur
Overzicht
Wanneer je data uploadt in mindzie Studio, creëert het platform automatisch twee verschillende datasets die samenwerken om je procesmining-analyse aan te sturen. Het begrijpen van het verschil tussen deze datasets en wanneer je welke moet gebruiken is essentieel om effectief te kunnen werken met mindzie Studio.
Deze gids legt de dual dataset architectuur uit, hoe de mindzie data pipeline je data transformeert, en wat er automatisch gebeurt wanneer je data voor het eerst importeert.
De Twee Datasets
Originele Dataset
De Originele Dataset is de ruwe eventlog die je aanvankelijk uploadt in mindzie Studio. Deze dataset bevat je procesdata precies zoals die is aangeleverd, of deze nu via een CSV-bestand is geüpload of via mindzie Data Designer is ingelezen vanuit bronsystemen.
Kenmerken:
- Bevat de ruwe data in de originele vorm
- Bevat alleen de kolommen en attributen die je hebt geïmporteerd (Case ID, Activiteit, Tijdstempel, Resource en eventuele extra attributen)
- Verandert niet gedurende je analyse
- Dient als basis voor alle daaropvolgende dataverwerking
Wanneer de Originele Dataset te gebruiken:
- Wanneer je de brondata wilt verifiëren
- Voor datakwaliteitscontroles en validatie
- Om te begrijpen wat er oorspronkelijk is aangeleverd voordat enige transformaties zijn toegepast
Verrijkte Dataset
De Verrijkte Dataset wordt automatisch aangemaakt door mindzie Studio nadat de data pipeline is uitgevoerd. Dit is de verbeterde versie van je data, die alle berekende attributen, prestatiedimensies, conformiteitsindicatoren en andere verrijkingen bevat die zijn toegevoegd via de logverrijkingsengine.
Kenmerken:
- Automatisch aangemaakt bij het importeren van data
- Bevat alle originele attributen plus nieuwe berekende attributen
- Wordt bijgewerkt telkens wanneer je verrijkingsberekeningen uitvoert
- Stuurt alle analyses, onderzoeken en dashboards aan
Wanneer de Verrijkte Dataset te gebruiken:
- Voor alle analyse- en onderzoekswerk (dit is de primaire dataset voor analyse)
- Bij het maken van dashboards en KPI’s
- Wanneer je werkt met prestatie-indicatoren, conformiteitsregels of aangepaste verrijkingen
- Voor de dagelijkse procesmining-activiteiten
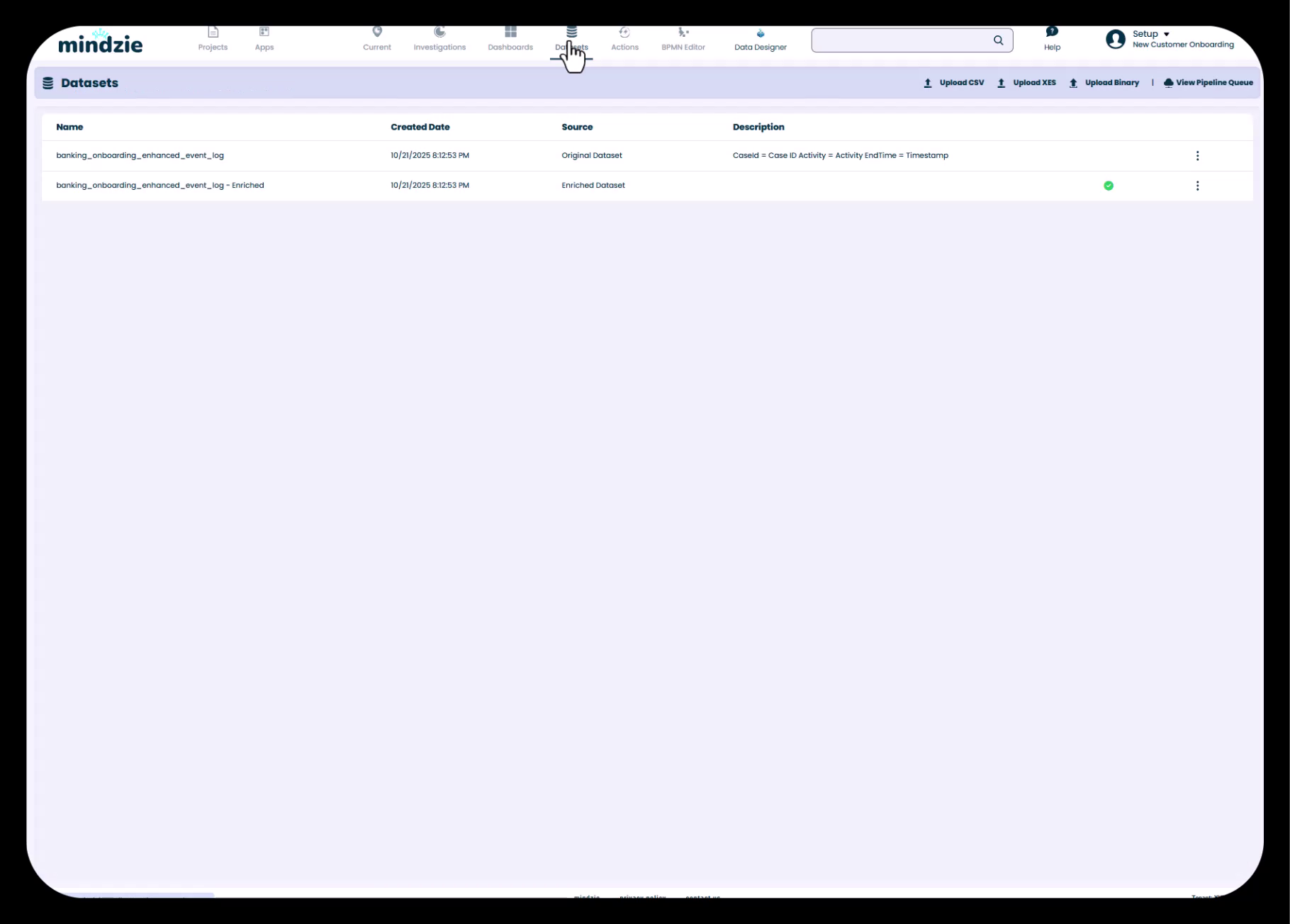 De Weergave van Datasets toont zowel de Originele Dataset als de Verrijkte Dataset
De Weergave van Datasets toont zowel de Originele Dataset als de Verrijkte Dataset
Hoe de Data Pipeline Werkt
Wanneer je data uploadt naar mindzie Studio, gebeurt er automatisch het volgende:
Stap 1: Data-import en Validatie
Je CSV-bestand of data uit mindzie Data Designer wordt geladen in mindzie Studio. Het systeem:
- Valideert het dataformaat en de structuur
- Koppelt sleutelkolommen (Case ID, Activiteit, Tijdstempel, Resource)
- Wijst kolomtypes en datatypes toe
- Creëert de Originele Dataset
Stap 2: Automatische Pipeline-uitvoering
Zodra je op "Opslaan" klikt na het uploaden van je data, voert mindzie Studio automatisch uit:
- De data pipeline
- Creëert de Verrijkte Dataset
- Voegt fundamentele attributen toe die je analysecapaciteiten verbeteren
Stap 3: Standaard Analyse Genereren
Om je snel op weg te helpen, genereert mindzie Studio automatisch nuttige standaardanalyses, waaronder:
- Procesoverzicht
- Lange case-duur
- Tijdsduur tussen hoofdprocesstappen
- Andere belangrijke inzichten
Deze vooraf gebouwde analyses helpen je direct je proces te verkennen zonder dat je alles vanaf nul hoeft te maken.
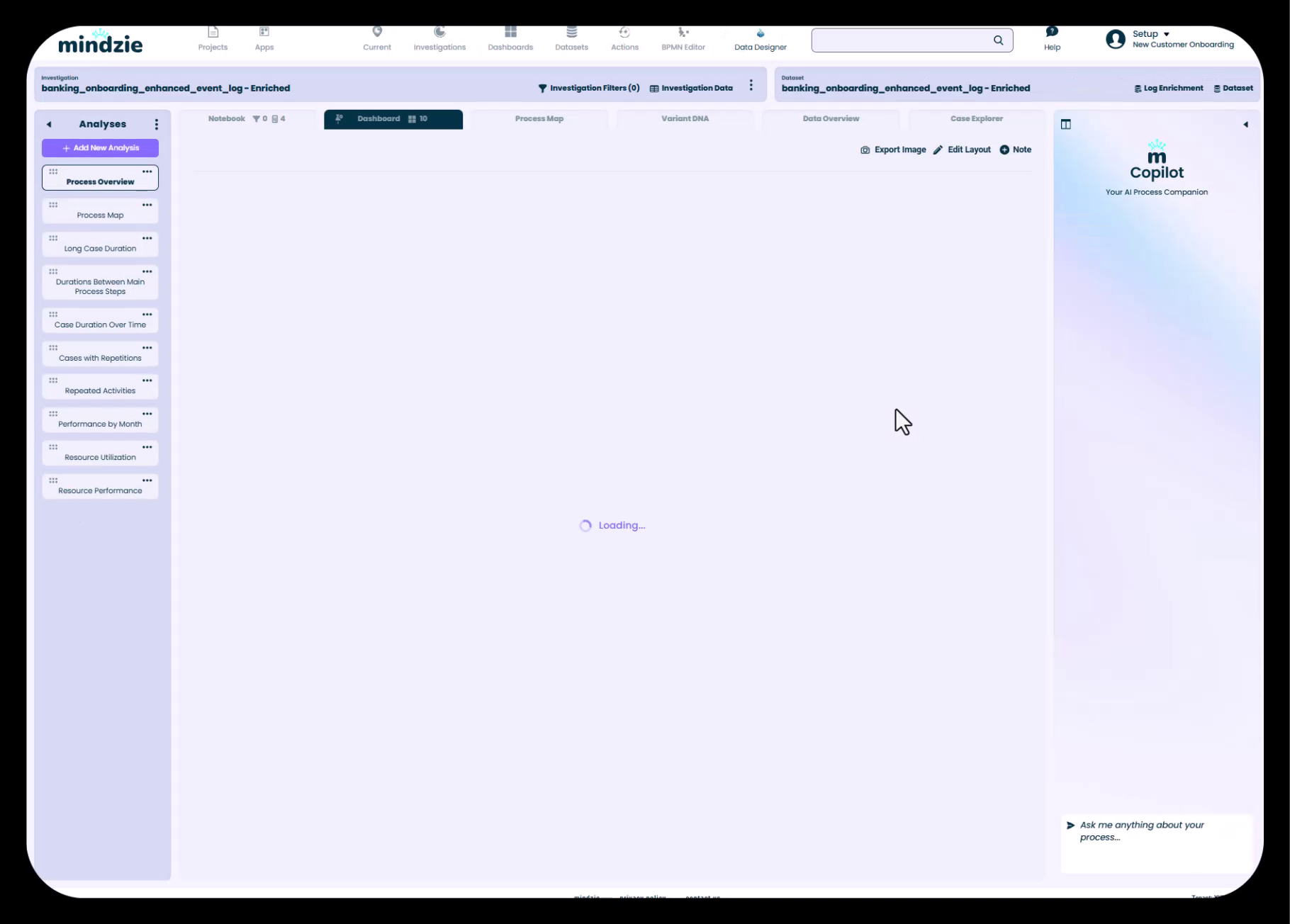 Standaard onderzoek automatisch gemaakt bij data-import
Standaard onderzoek automatisch gemaakt bij data-import
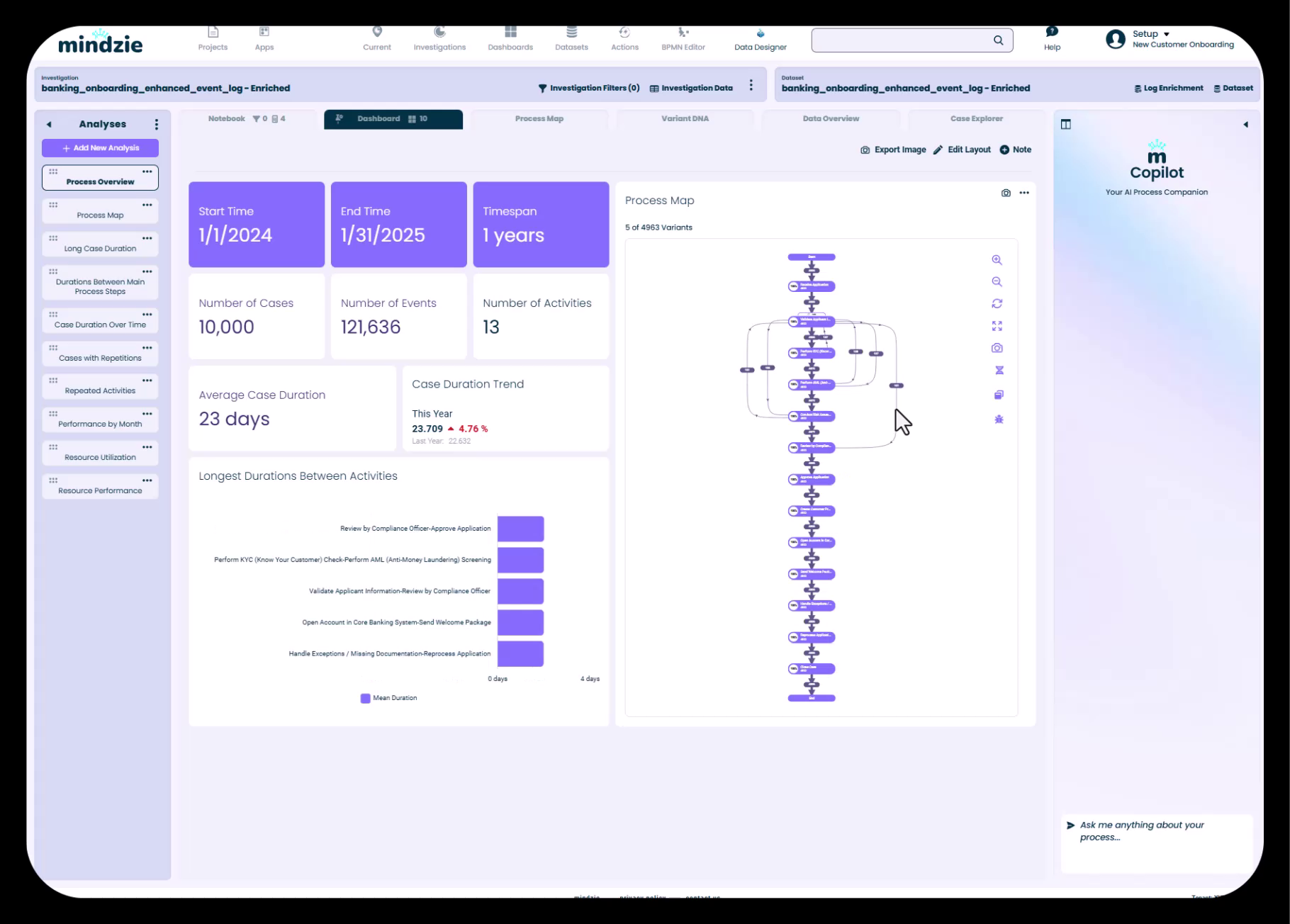 Standaard analyse toont 10.000 cases en 121.000 events met belangrijke procesinzichten
Standaard analyse toont 10.000 cases en 121.000 events met belangrijke procesinzichten
Begrijpen van Dataset Grootte: Het Voorbeeld
In de demo bevat de banking onboarding dataset:
- 10.000 cases - Elke case vertegenwoordigt één klant onboarding traject
- 121.000 events - Het totale aantal processtappen over alle cases
Dit betekent dat elk klant onboarding case gemiddeld ongeveer 12 activiteiten of processtappen omvat. Dit soort informatie wordt meteen zichtbaar zodra je data geladen is in mindzie Studio.
De Rol van Logverrijking
De kracht van de dual dataset architectuur wordt duidelijk als je begint met het gebruiken van de logverrijkingsengine. Hierin onderscheidt de Verrijkte Dataset zich echt van de Originele Dataset.
Wat Logverrijking Doet
Logverrijking stelt je in staat je data te verrijken met:
Prestatiemaatstaven:
- Duur-berekeningen tussen activiteitenparen
- Case duur van begin tot eind
- Prestatie-indeling (snel, normaal, langzaam)
- Aangepaste SLA-naleving
Conformiteitsregels:
- Indicatoren voor ongewenste activiteiten
- Ontbrekende verplichte stappen
- Verkeerde volgorde van activiteiten
- Herhaalde activiteiten en herbewerkingslussen
Aangepaste Attributen:
- Activiteitskosten
- AI-voorspellingen
- Aangepaste categorieën
- Wiskundige transformaties
- Tijdgebaseerde berekeningen
Hoe Verrijkingen de Dataset Bijwerken
Elke keer dat je nieuwe verrijkingen maakt en berekent:
- De data pipeline wordt uitgevoerd
- Nieuwe attributen worden toegevoegd aan de Verrijkte Dataset
- Deze nieuwe attributen worden beschikbaar voor filteren en berekeningen
- Je analyse wordt krachtiger met elke verrijking
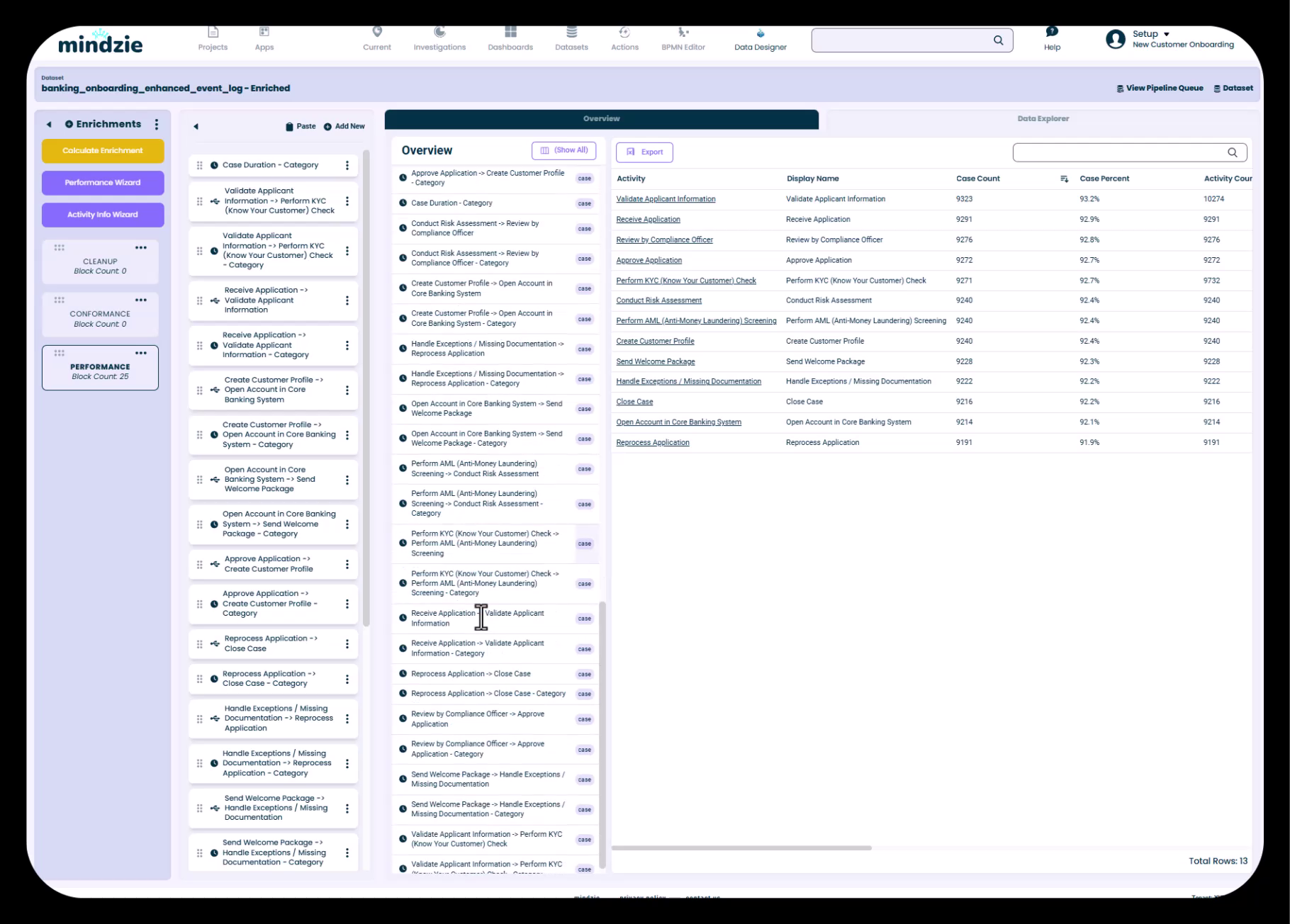 Data overzicht toont zowel originele attributen als verrijkte attributen met iconen die systeemgegenereerde verbeteringen aangeven
Data overzicht toont zowel originele attributen als verrijkte attributen met iconen die systeemgegenereerde verbeteringen aangeven
Automatisch Toegevoegde Attributen door mindzie
Zelfs zonder handmatige verrijkingen voegt mindzie Studio automatisch verschillende nuttige attributen toe aan je Verrijkte Dataset, zoals:
- Tijd van de dag - Wanneer activiteiten plaatsvonden
- Case Start - Wanneer elke case begon
- Case Finish - Wanneer elke case eindigde
- Case Duur - Totale tijd van start tot finish
- Eerste Resource - Wie de case initieerde
- Activiteitsfrequentie - Hoe vaak activiteiten voorkomen
- En nog veel meer...
Deze automatische verrijkingen geven je direct analytische mogelijkheden zonder enige configuratie.
De Juiste Dataset Kiezen voor Analyse
Bij het maken van onderzoeken en analysenotebooks in mindzie Studio moet je kiezen met welke dataset je werkt.
Beste Praktijk: Selecteer altijd de Verrijkte Dataset voor je onderzoeken en analysewerk. Deze dataset bevat alle verrijkte attributen en berekende maten die je analyse krachtig en inzichtelijk maken.
De Originele Dataset gebruik je voornamelijk voor:
- Referentie- en validatiedoeleinden
- Datakwaliteitsaudits
- Begrijpen van de brondatastructuur
De Continue Verbetercyclus
De dual dataset architectuur ondersteunt een iteratieve workflow:
- Uploaden - Importeer je data om de Originele Dataset te creëren
- Verrijken - Voeg prestatiestatistieken, conformiteitsregels en aangepaste attributen toe
- Berekenen - Voer de pipeline uit om de Verrijkte Dataset bij te werken
- Analyseren - Maak onderzoeken en analyses met de verrijkte attributen
- Herhalen - Voeg meer verrijkingen toe om je inzichten te verdiepen
Elke cyclus maakt je Verrijkte Dataset waardevoller en je analyse geavanceerder.
Belangrijkste Punten
- Twee datasets worden gemaakt: Origineel (ruwe data) en Verrijkt (verbeterde data)
- Automatische creatie: De Verrijkte Dataset wordt automatisch aangemaakt bij het uploaden van data
- Gebruik de Verrijkte Dataset: Dit is je primaire dataset voor alle analyses en onderzoeken
- Pipeline uitvoering: De data pipeline transformeert Origineel naar Verrijkt
- Continue verrijking: Elke verrijkingsberekening voegt nieuwe attributen toe aan de Verrijkte Dataset
- Standaardanalyse: mindzie Studio levert automatisch nuttige startanalyses
- Iteratief proces: Je kunt doorlopend verrijkingen toevoegen om je analyse krachtiger te maken