Genereer Synthetische Data
De Genereer Synthetische Data functie creëert volledig nieuwe, gefabriceerde datasets die de statistische eigenschappen van je originele data behouden zonder dat er daadwerkelijke waarden uit je bron aanwezig zijn. Dit is nuttig voor:
- Demo's - Maak realistisch ogende data om je process mining mogelijkheden te demonstreren
- Testen - Genereer testdatasets met bekende eigenschappen
- Delen - Deel datapatronen extern zonder gevoelige informatie prijs te geven
- Training - Maak trainingsdatasets voor machine learning modellen
Belangrijk: Dit is GEEN anonimisatie. Synthetische data is volledig gefabriceerd - er bestaan geen originele datawaarden in de output. De synthetische dataset is veilig om extern te delen.
Hoe Toegang te Krijgen
- Navigeer naar de Datasets pagina
- Klik op het menu met drie puntjes bij een dataset
- Selecteer Genereer Synthetische Data
Configuratieopties
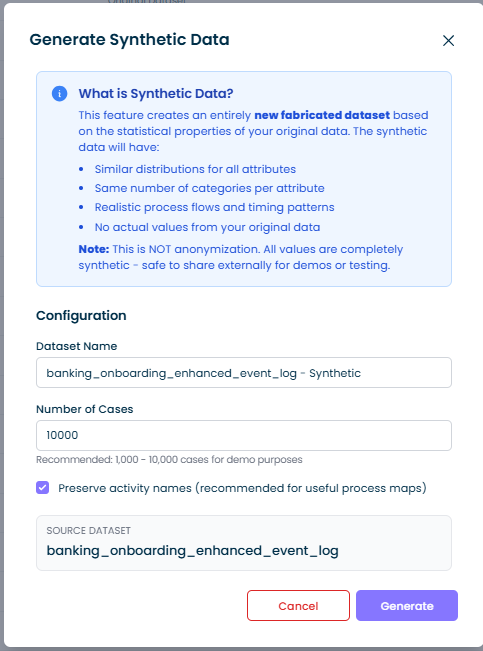
Dataset Naam
De naam voor je synthetische dataset. Standaard is dit je bron dataset naam met " - Synthetic" erachter geplakt.
Aantal Cases
Geef op hoeveel cases je wilt genereren in de synthetische dataset:
- Minimum: 100 cases
- Maximum: 100.000 cases
- Aanbevolen: 1.000 - 10.000 cases voor demo doeleinden
Grotere datasets kosten meer tijd om te genereren en resulteren in grotere downloads.
Activiteitenamen Behouden
Wanneer ingeschakeld (aanbevolen), behoudt de synthetische dataset je originele activiteitenamen zoals "Order Indienen", "Aanvraag Beoordelen", etc. Dit levert nuttige proceskaarten op die je daadwerkelijke processtroom weerspiegelen.
Wanneer uitgeschakeld, worden activiteitenamen vervangen door algemene labels zoals "Activity_1", "Activity_2", etc. Gebruik deze optie als zelfs je activiteitenamen gevoelige informatie bevatten.
Wat Wordt Gegeneerd
De synthetische datagenerator analyseert je brondataset en creëert nieuwe data met:
| Element | Hoe Het Wordt Gegeneerd |
|---|---|
| Case IDs | Nieuwe sequentiële IDs: Case_1, Case_2, etc. |
| Activiteitenamen | Behouden uit de bron (of geanonimiseerd als optie uitstaat) |
| Tijdstempels | Realistische datums met vergelijkbare duurpatronen tussen activiteiten |
| Tekst Attributen | Vervangen door generieke waarden zoals Customer_1, Region_2, etc. met behoud van de verdeling (als 60% van de cases "Hoog Prioriteit" waren, zal ongeveer 60% van de synthetische cases Priority_1 hebben) |
| Numerieke Attributen | Gegeneerd met vergelijkbare statistische eigenschappen (gemiddelde, spreiding, min/max bereik) |
| Processtroom | Activiteitsvolgordes bemonsterd uit je daadwerkelijke procesvarianten |
Wat NIET Wordt Opgenomen
Berekende kolommen worden uitgesloten uit de synthetische output omdat deze opnieuw berekend worden bij het importeren in mindzieStudio.
Output
Wanneer je op Genereer klikt, zal mindzieStudio:
- Je brondata analyseren om statistische patronen te extraheren
- Het opgegeven aantal synthetische cases genereren
- Automatisch het resultaat downloaden als CSV-bestand
De bestandsnaam van de download is gelijk aan je Dataset Naam met de extensie .csv.
Voorbeeld
Brondata:
CaseId,Activity,Timestamp,Customer,Amount
C001,Submit,2024-01-01 09:00,Acme Corp,1500.00
C001,Review,2024-01-01 11:00,Acme Corp,1500.00
C002,Submit,2024-01-02 10:00,Beta Inc,2300.00
Synthetische output (met Activiteitenamen Behouden ingeschakeld):
CaseId,Activity,Timestamp,Customer,Amount
Case_1,Submit,2020-03-15 14:23,Customer_1,1842.37
Case_1,Review,2020-03-15 16:45,Customer_1,1842.37
Case_2,Submit,2020-07-22 09:12,Customer_2,1523.89
Let op:
- Activiteitenamen zijn behouden
- Klantnamen zijn vervangen door generieke
Customer_1,Customer_2 - Bedragen zijn vergelijkbaar in bereik maar gefabriceerd
- Tijdstempels zijn realistisch maar volledig nieuw
Toepassingsgevallen
Demo Datasets Maken
Genereer synthetische data uit je productieproces om veilige demo datasets te creëren die echte procespatronen tonen zonder bedrijfsgevoelige data te onthullen.
Delen met Externe Consultants
Wanneer je samenwerkt met externe process mining consultants of leveranciers, deel synthetische datasets die je proceskenmerken behouden zonder gevoelige informatie prijs te geven.
Prestatie Testen
Genereer grote synthetische datasets (50.000+ cases) om te testen hoe je notebooks en dashboards presteren met grotere hoeveelheden data.
Training en Educatie
Maak synthetische datasets om nieuwe teamleden te trainen in process mining concepten met realistische maar veilige data.