AI Causal Analysis (Alpha)
De calculator AI Causal Analysis gebruikt machine learning om te ontdekken welke case-attributen de sterkste drijvers zijn van een door jou gedefinieerde uitkomst. In plaats van alleen correlatie te tonen, isoleert hij de kenmerken die de grootste statistische invloed hebben op de vraag of een case voldoet aan de uitkomst die jij definieert - zodat je van "wat gebeurt er" kunt overgaan naar "waarom gebeurt het."
Alpha-functie: Deze calculator maakt deel uit van het mindzie Alpha-programma. Het vereist dat PreRelease is ingeschakeld voor je tenant. Zie Alpha Features voor meer informatie.
Overzicht
AI Causal Analysis beantwoordt vragen als:
- Waarom duren sommige cases langer dan 7 dagen om af te ronden?
- Welke attributen maken het waarschijnlijker dat een factuur te laat wordt betaald?
- Wat onderscheidt cases die de SLA schenden van cases die dat niet doen?
- Welke vestigingen, teams of productcategorieën beïnvloeden een bepaalde uitkomst het meest?
Je definieert de uitkomst (de cases die je wilt verklaren), wijst de calculator op een set invoerkolommen, en hij retourneert een gerangschikte lijst van de factoren die het meest verantwoordelijk zijn voor het feit dat die cases in de uitkomstgroep vallen.
Hoe het zich verhoudt tot Root Cause Analysis
AI Causal Analysis deelt een doel met de bestaande Root Cause Analysis-calculator, maar hanteert een veel rigoureuzere aanpak:
| Mogelijkheid | Root Cause Analysis | AI Causal Analysis |
|---|---|---|
| Vindt drijvers op basis van één attribuut | Ja | Ja |
| Vindt conjuncties van meerdere attributen (tot 3 attributen per regel) | Nee | Ja |
| Onderscheidt correlatie van causaliteit | Nee | Ja (causale graaf + propensity-correctie) |
| Rapporteert betrouwbaarheidsintervallen | Nee | Ja (95% Wilson CI op elke regel) |
| Controleert voor meervoudig testen | Nee | Ja (Benjamini-Hochberg FDR) |
| Verwerkt numerieke / datum / tijd-attributen | Nee (alleen strings) | Ja (outcome-aware binning) |
| Beschrijving in gewone taal per driver | Nee | Ja |
Gebruik Root Cause Analysis voor een snelle scan op één attribuut, en AI Causal Analysis voor elk serieus onderzoek - vooral wanneer iemand op basis van het resultaat gaat handelen.
Hoe de Calculator Toe te Voegen
- Open een notebook in mindzieStudio
- Klik op Add Calculator en selecteer AI Causal Analysis (Alpha)
- Configureer de uitkomst en invoerkolommen (zie hieronder)
- Klik op Create
Configuratie
Titel
De weergavenaam van de calculator. Standaard is dit AI Causal Analysis (Alpha) - wijzig deze in iets dat specifiek is voor de vraag die je beantwoordt, bijvoorbeeld Waarom zijn IC-opnames lang? of Drivers van Late Betaling.
Beschrijving
Optionele vrije tekst. Handig om de businessvraag, de gebruikte datumreeks of de stakeholder die de analyse heeft aangevraagd te documenteren.
Uitkomstdefinitie
De uitkomst is de groep cases die je wilt verklaren. De calculator vergelijkt deze cases met de rest van de dataset en identificeert welke invoerkolommen de twee groepen het best scheiden.
Er zijn drie modi beschikbaar voor het definiëren van de uitkomst:
Filter-modus
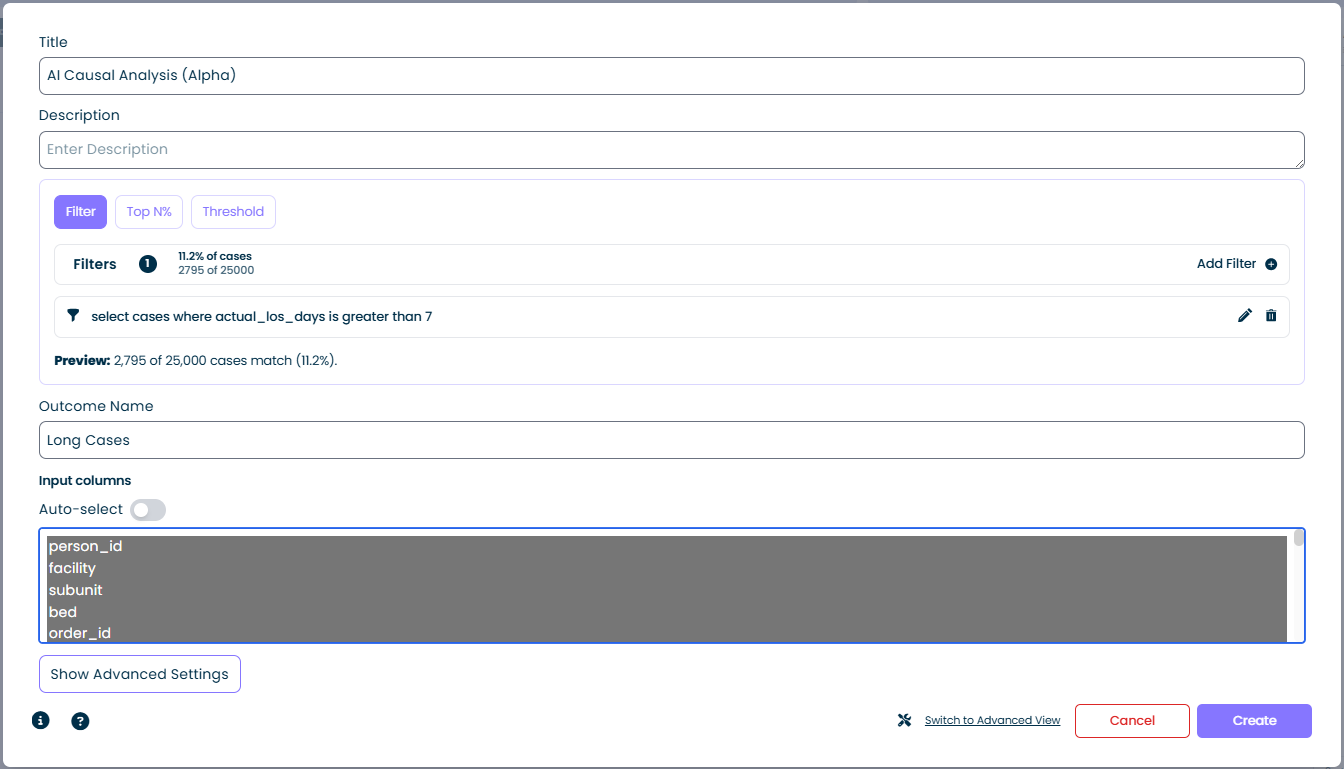
Selecteer het tabblad Filter en voeg één of meer filterexpressies toe. De calculator behandelt cases die aan het filter voldoen als de "uitkomst"-groep.
- Cases matching: weergegeven als percentage en absoluut aantal, bijvoorbeeld
11,2% van de cases / 2.795 van de 25.000 - Add Filter: opent de standaard filterbouwer - combineer een willekeurig aantal condities
- Preview: wordt live bijgewerkt terwijl je het filter bouwt, zodat je de selectie kunt valideren voordat je de calculator draait
Filter-modus is de meest flexibele optie. Elke conditie die je als een mindzie-filter kunt uitdrukken (duurgrenzen, attribuutovereenkomsten, aanwezigheid van activiteiten, enzovoort) kan een uitkomst worden. In de schermafbeelding hierboven definieert het filter select cases where actual_los_days is greater than 7 "Long Cases" als de uitkomst.
Top N%-modus
Selecteer het tabblad Top N% om de hoogste (of laagste) waarden van een numeriek attribuut als uitkomst te gebruiken. Dit is nuttig wanneer je "de ergste cases" of "de topperformers" wilt verklaren zonder een harde drempel te hoeven kiezen. Voorbeeld: de top 10% van cases op doorlooptijd.
Drempel-modus
Selecteer het tabblad Threshold om de uitkomst te definiëren met één numerieke grenswaarde op een attribuut. Elke case boven (of onder) de waarde wordt onderdeel van de uitkomstgroep. Voorbeeld: cases waarin invoice_amount hoger is dan 50.000.
Outcome Name
Een korte label die de uitkomstgroep in de resultaten identificeert, bijvoorbeeld Long Cases, Late Payments of SLA Breach. Deze naam verschijnt overal in de analyse-uitvoer waar naar de uitkomstgroep wordt verwezen.
Invoerkolommen
De kolommen die het model mag gebruiken bij het zoeken naar drijvers van de uitkomst.
- Kolomlijst: elk case-attribuut in de dataset wordt getoond. Selecteer er één of meer om ze op te nemen in de analyse. Geselecteerde kolommen worden gemarkeerd.
- Auto-select-schakelaar: indien ingeschakeld kiest mindzie automatisch een zinvolle standaardset invoerkolommen op basis van het dataset-schema. Schakel dit uit wanneer je volledige handmatige controle wilt - bijvoorbeeld om een kolom uit te sluiten die triviaal gecorreleerd is met de uitkomst (zoals een ID die het antwoord lekt).
Tips voor het kiezen van invoerkolommen:
- Sluit kolommen uit die afgeleid zijn van de uitkomst. Als
discharge_dategebruikt wordt omactual_los_dayste berekenen, zal deze de resultaten domineren zonder extra inzicht toe te voegen. - Sluit identifiers met hoge kardinaliteit (
person_id,order_id) uit, tenzij je specifiek per-entiteit effecten wilt zien. - Neem contextuele attributen (vestiging, productcategorie, prioriteit, regio) op - daar vind je gewoonlijk de interessante drijvers.
Show Advanced Settings
Opent extra afstemmingsopties voor het zoekproces. De standaardwaarden werken goed voor de meeste analyses - overschrijf ze alleen als je een specifieke reden hebt.
| Instelling | Standaard | Doel |
|---|---|---|
| Beam width | 50 | Hoeveel kandidaatregels bij elke zoekdiepte worden behouden. Hoger = uitvoeriger, langzamer. |
| Max rule depth | 3 | Maximaal toegestane regellengte. 3 betekent regels van de vorm A AND B AND C. |
| Min cases per rule | 30 | Regels die minder dan dit aantal cases zouden beïnvloeden, worden verworpen als te klein om actionable te zijn. |
| Min lift | 1.2 | Het uitkomstpercentage binnen de regel moet de baseline met minstens deze factor overtreffen (1,2 = minstens 20% hoger dan baseline). |
| FDR alpha | 0.05 | Benjamini-Hochberg significantiedrempel voor het beheersen van valse ontdekkingen in de regelzoektocht. |
| Max drivers returned | 20 | Bovengrens op het aantal regels dat in de volledige tabelweergave wordt getoond. |
| Redundancy Jaccard | 0.9 | Regels waarvan de case-sets voor meer dan deze fractie overlappen, worden als duplicaten beschouwd en gefilterd. |
| Sampling threshold | 2.000.000 cases | Datasets boven deze grootte worden deterministisch gesampled met Floyd's combinatie-algoritme. De output rapporteert WasSampled = true en de werkelijke steekproefgrootte. |
Switch to Advanced View
Schakelt de editor naar geavanceerde modus voor fijnmazige controle over elke modelparameter. De begeleide weergave die hier wordt getoond is voldoende voor de overgrote meerderheid van de use cases.
Typische Workflow
- Formuleer de vraag - bepaal welke uitkomst je wilt verklaren. "Wat maakt cases traag?" wordt een Filter-uitkomst van
case_duration > 7 dagen. - Definieer de uitkomst - gebruik Filter-, Top N%- of Drempel-modus. Controleer of het Preview-percentage redelijk lijkt (te weinig cases geeft onstabiele resultaten; te veel betekent dat de uitkomst niet echt onderscheidend is).
- Benoem de uitkomst - kies een beknopt label dat goed leest in resultaten en rapporten.
- Selecteer invoerkolommen - begin met Auto-select en snoei daarna kolommen die het antwoord lekken of ruis toevoegen.
- Create - draai de calculator. Het resultaat toont de gerangschikte drijvers van de uitkomst.
- Interpreteer - bekijk de belangrijkste drijvers, verfijn de uitkomst of invoerset indien nodig en draai opnieuw.
Voorbeeld
Een operations-team van een ziekenhuis wil begrijpen waarom sommige klinische opnames langer duren dan 7 dagen.
| Instelling | Waarde |
|---|---|
| Titel | AI Causal Analysis (Alpha) |
| Filter-modus | select cases where actual_los_days is greater than 7 |
| Preview | 2.795 van 25.000 cases voldoen (11,2%) |
| Outcome Name | Long Cases |
| Invoerkolommen | facility, subunit, bed, order_id, ... (auto-selected) |
Na het draaien rapporteert de calculator welke combinaties van vestiging, sub-unit en zorgattributen langdurige cases het sterkst onderscheiden van cases met normale duur. Dit wijst het team op specifieke eenheden en workflows om te onderzoeken, in plaats van dat ze elk attribuut handmatig moeten exploreren.
De Resultaten Interpreteren
Voor elke topdriver produceert de calculator een beschrijvende alinea in gewone taal en een evidence-badge die de sterkte van de bevinding beschrijft:
| Badge | Betekenis | Hoe te handelen |
|---|---|---|
| Causal | Zowel het causal-graph-signaal als het voor confounders gecorrigeerde effect zijn positief. | Sterkste actionable bewijs - veilig om prioriteit te geven voor interventie. |
| Likely Causal | De causale graaf verbindt de regel met de uitkomst, maar het effect verzwakt zodra we corrigeren voor confounders. | Veelbelovend - onderzoek verder voordat je handelt. |
| Associated | Het effect overleeft correctie, maar de graaf plaatst de regel niet op een direct pad naar de uitkomst. | Reële associatie, maar waarschijnlijk indirect - kan een proxy zijn voor de echte driver. |
| Correlational | Er is een associatie, maar we kunnen geen causaal verband bevestigen. | Alleen diagnostisch signaal - handel er niet op basis van op zich. |
Voorbeeldbeschrijving voor een Causal regel:
Channel = Online is een waarschijnlijke driver van Non-First Contact Resolution. Cases die aan deze regel voldoen laten een uitkomstpercentage van 46,1% zien tegenover de baseline van 29,0% (1,59x, 95% CI 1,51x - 1,68x, p < 0,001). Het bestrijkt 2.518 cases, goed voor 34,7% van alle Non-First Contact Resolution-voorvallen. Het effect overleefde correctie voor andere topdrivers en ligt op een direct pad naar de uitkomst in de geleerde causale graaf.
De Full Table-weergave voegt de complete gerangschikte lijst toe met dekking, lift, betrouwbaarheidsinterval, gecorrigeerd effect, p-waarde en badge voor elke regel die de zoektocht en het significantiefilter overleefde.
Hoe het Algoritme Werkt
AI Causal Analysis draait een pijplijn van vijf stadia. Elke fase heeft een specifieke taak en is zo ontworpen dat het geheel in seconden klaar is, zelfs op datasets van miljoenen cases.
1. Voorbereiding en binning
- De calculator neemt de cases in je uitkomstgroep en labelt deze
1; alle andere krijgen label0. Dit is het baseline-percentage dat je in de output ziet. - Categorische attributen (strings, booleans, integers met lage kardinaliteit) worden direct gebruikt. Elke unieke waarde wordt een kandidaat-literal (bv.
facility = Memorial). - Numerieke en datum/tijd-attributen worden gebinned met een MDL-optimale, outcome-aware binner. In plaats van gelijke breedte of gelijke frequentie te kiezen, kiest de binner snijpunten die uitkomst- van niet-uitkomstcases het beste scheiden en gebruikt vervolgens het Minimum Description Length-principe om het aantal bins automatisch te bepalen. Dit zet een numerieke kolom als
actual_los_daysom in een kleine set betekenisvolle buckets (bv.<= 3 dagen,4 - 7 dagen,> 7 dagen).
2. Bitmap-indexering
Elke literal wordt opgeslagen als een bitset - één bit per case, 1 als de case aan de literal voldoet. Het combineren van literals met AND wordt een snelle bitwise-intersectie:
facility = Memorial AND priority = Highwordt berekend alsbitset_A & bitset_B.- Dekking, uitkomstaantal en lift voor een kandidaatregel kunnen in microseconden worden geëvalueerd, ongeacht de regeldiepte.
Literals die minder dan Min cases per rule dekken, worden verwijderd voordat het zoeken begint.
3. Beam-search subgroup discovery
De calculator doorloopt de ruimte van regels breadth-first:
- Diepte 1: evalueer elke enkele literal. Scoor elke met een kwaliteitsmaat (lift en Weighted Relative Accuracy) en behoud de top
Beam width(standaard 50). - Diepte 2: breid elke behouden regel uit met elke andere compatibele literal om conjuncties als
A AND Bte vormen. Scoor allemaal en behoud opnieuw de topBeam width. - Diepte 3: herhaal nog een keer. Stop bij
Max rule depth.
Regels die onder Min lift of Min cases per rule vallen, worden op elk niveau gesnoeid.
Na het zoeken verwijdert een Jaccard-redundantiefilter bijna-duplicaatregels: als twee regels in essentie dezelfde cases dekken (overlap boven Redundancy Jaccard, standaard 0,9), wordt alleen de beste behouden.
4. Statistische significantie
Voor elke overgebleven regel berekent de calculator:
- De risk ratio (uitkomstpercentage binnen de regel gedeeld door baseline-percentage) en het bijbehorende 95% Wilson-betrouwbaarheidsinterval, dat zich goed gedraagt voor kleine en extreme kansen waar de normale benadering faalt.
- Een p-waarde onder de nulhypothese dat de regel geen effect heeft.
- Een Benjamini-Hochberg FDR-correctie over alle geteste regels.
FDR alpha(standaard 0,05) bepaalt de verwachte false-discovery rate. Regels die FDR niet overleven worden niet gerapporteerd, wat voorkomt dat het zoeken je overspoelt met onechte bevindingen.
5. Causale afweging
Significantie alleen vertelt je nog steeds alleen dat er een associatie is. Twee extra signalen bepalen of een regel een Causal-badge krijgt:
- Causal-graph signal - een lichte Bayesiaanse structurele score, geleerd op basis van de attributen en de uitkomst. Hij vraagt: ligt deze regel op een direct pad naar de uitkomst in de geleerde graaf, of alleen op een indirect pad via een confounder?
- Propensity-score adjustment - een ridge-geregulariseerde logistische regressie modelleert de kans dat elke case aan de regel voldoet, gegeven alle andere topdrivers. Het effect van de regel wordt vervolgens opnieuw geschat na weging op basis van die propensity. Als het effect naar nul krimpt, was de regel slechts een proxy voor andere drivers; als het aanhoudt, heeft het onafhankelijke verklarende kracht.
De adjudicator combineert beide signalen tot de vier hierboven gedefinieerde evidence-badges.
6. Narratieve generatie
De laatste stap stelt de alinea in gewone taal samen die in de kaartweergave wordt getoond. Hij weeft de regeldefinitie, de uitkomstpercentages binnen de regel en de baseline, de risk ratio en het betrouwbaarheidsinterval, de p-waarde, de dekking en de evidence-badge samen tot een zinstructuur die natuurlijk leest voor een niet-statistische lezer.
Prestaties
Gemeten op een ontwikkelmachine:
| Dataset | Tijd |
|---|---|
| 100.000 cases x 4 kolommen | minder dan 1 seconde |
| 200.000 cases x 20 kolommen | minder dan 2 seconden |
| 1.000.000 cases x 50 kolommen | ongeveer 3 seconden |
Datasets boven de sampling-drempel (standaard 2.000.000 cases) worden deterministisch gesampled met Floyd's combinatie-algoritme. Wanneer dit gebeurt markeert de output WasSampled = true en rapporteert de werkelijke steekproefgrootte, zodat het resultaat reproduceerbaar is en de sampling zichtbaar.
Bekende Beperkingen (v1)
- Alleen binaire uitkomsten. Multi-class uitkomsten (snel / gemiddeld / traag, bijvoorbeeld) worden in deze release niet ondersteund. Definieer tweezijdige splitsingen als aparte analyses.
- Nog geen verklaringen per case. v1 beantwoordt "wat drijft deze uitkomst in de dataset?" Een toekomstige release voegt "waarom ging deze specifieke case fout?"-panelen toe.
- Geen analyse van temporele drift. Als de drivers tussen kwartalen veranderen, splitst v1 ze niet over tijd. Draai de calculator apart op elk tijdsegment wanneer dat van belang is.
- Numerieke binning is outcome-aware. Als je vaste, door mensen gekozen bins wilt, voor-bucket de kolom dan met een enrichment voordat je de calculator draait.
Toepassingsscenario's
Performance Drivers
Identificeer de attributen die het sterkst geassocieerd zijn met cases die de SLA schenden, het budget overschrijden of langer duren dan verwacht. Werkt goed met een Filter-uitkomst die is opgebouwd op een duur- of KPI-enrichment.
Uitkomstanalyse
Vergelijk geslaagde cases met mislukte of geannuleerde. Gebruik een Filter-uitkomst op een status- of uitkomstattribuut om te zien welke upstream-attributen elke uitkomst voorspellen.
Risico en Compliance
Richt de calculator op cases die gemarkeerd zijn door een conformance- of controle-enrichment om te leren welke contextuele factoren correleren met compliance-fouten.
Top-Performer Analyse
Gebruik de Top N%-modus om te verklaren wat je beste cases, teams of klanten anders maakt dan de rest. Voer de inzichten terug naar procesontwerp of training.
Tips
- Begin eenvoudig. Een goedgekozen Filter met twee of drie condities plus auto-selected invoer geeft doorgaans de helderste resultaten.
- Let op het preview-percentage. Als de uitkomstgroep minder dan ~2% of meer dan ~50% van de dataset is, wordt de analyse moeilijker te interpreteren. Pas het filter aan totdat de groep een zinvolle minderheid is.
- Itereer op invoerkolommen. Verwijder kolommen waarvan de aanwezigheid resultaten domineert zonder inzicht (IDs, tijdstempels die de uitkomst lekken) en draai opnieuw.
- Benoem uitkomsten specifiek.
Long Casesis beter danOutcome 1wanneer je resultaten deelt met stakeholders of opneemt in rapporten. - Combineer met de Decision Tree-calculator voor een tweede blik op dezelfde vraag. Decision Tree toont de vertakkingsstructuur; AI Causal Analysis rangschikt de totale feature-impact.
Gerelateerde Calculators
- Decision Tree - complementaire weergave die laat zien hoe attributen cases in uitkomstgroepen splitsen
- Root Cause Analysis - deterministische statistische oorzaakanalyse voor KPI-afwijkingen
- Case Outcome By Category - vergelijk uitkomstpercentages over een gekozen categorisch attribuut
Gerelateerde Functies
- AI Studio (Alpha) - de bredere predictive analytics-werkomgeving, inclusief Feature Impact en Root Cause
- Alpha Features Overzicht - volledige lijst van functies in het mindzie Alpha-programma
Feedback Geven
AI Causal Analysis is een Alpha-functie en jouw input geeft direct vorm aan hoe het evolueert:
- Email: support@mindzie.com
- Onderwerp: Vermeld
Alpha Feedback: AI Causal Analysis - Inhoud: de uitkomstdefinitie die je gebruikte, de invoerkolommen, wat je verwachtte en wat je kreeg