Understanding mindzie's Dual Dataset Architecture
Overview
When you upload data into mindzie Studio, the platform automatically creates two distinct datasets that work together to power your process mining analysis. Understanding the difference between these datasets and when to use each one is fundamental to working effectively with mindzie Studio.
This guide explains the dual dataset architecture, how the mindzie data pipeline transforms your data, and what happens automatically when you import data for the first time.
The Two Datasets
Original Dataset
The Original Dataset is the raw event log that you initially upload into mindzie Studio. This dataset contains your process data exactly as it was provided, whether uploaded via CSV file or ingested through mindzie Data Designer from source systems.
Characteristics:
- Contains the raw data in its original form
- Includes only the columns and attributes you imported (Case ID, Activity, Timestamp, Resource, and any additional attributes)
- Remains unchanged throughout your analysis
- Serves as the foundation for all subsequent data processing
When to use the Original Dataset:
- When you need to verify the source data
- For data quality checks and validation
- To understand what was originally provided before any transformations
Enriched Dataset
The Enriched Dataset is automatically created by mindzie Studio after the data pipeline executes. This is the enhanced version of your data that includes all the calculated attributes, performance metrics, conformance flags, and other enrichments added through the log enrichment engine.
Characteristics:
- Created automatically when data is imported
- Contains all original attributes plus new calculated attributes
- Updated whenever you run enrichment calculations
- Powers all analysis, investigations, and dashboards
When to use the Enriched Dataset:
- For all analysis and investigation work (this is the primary dataset for analysis)
- When creating dashboards and KPIs
- When working with performance metrics, conformance rules, or custom enrichments
- For day-to-day process mining activities
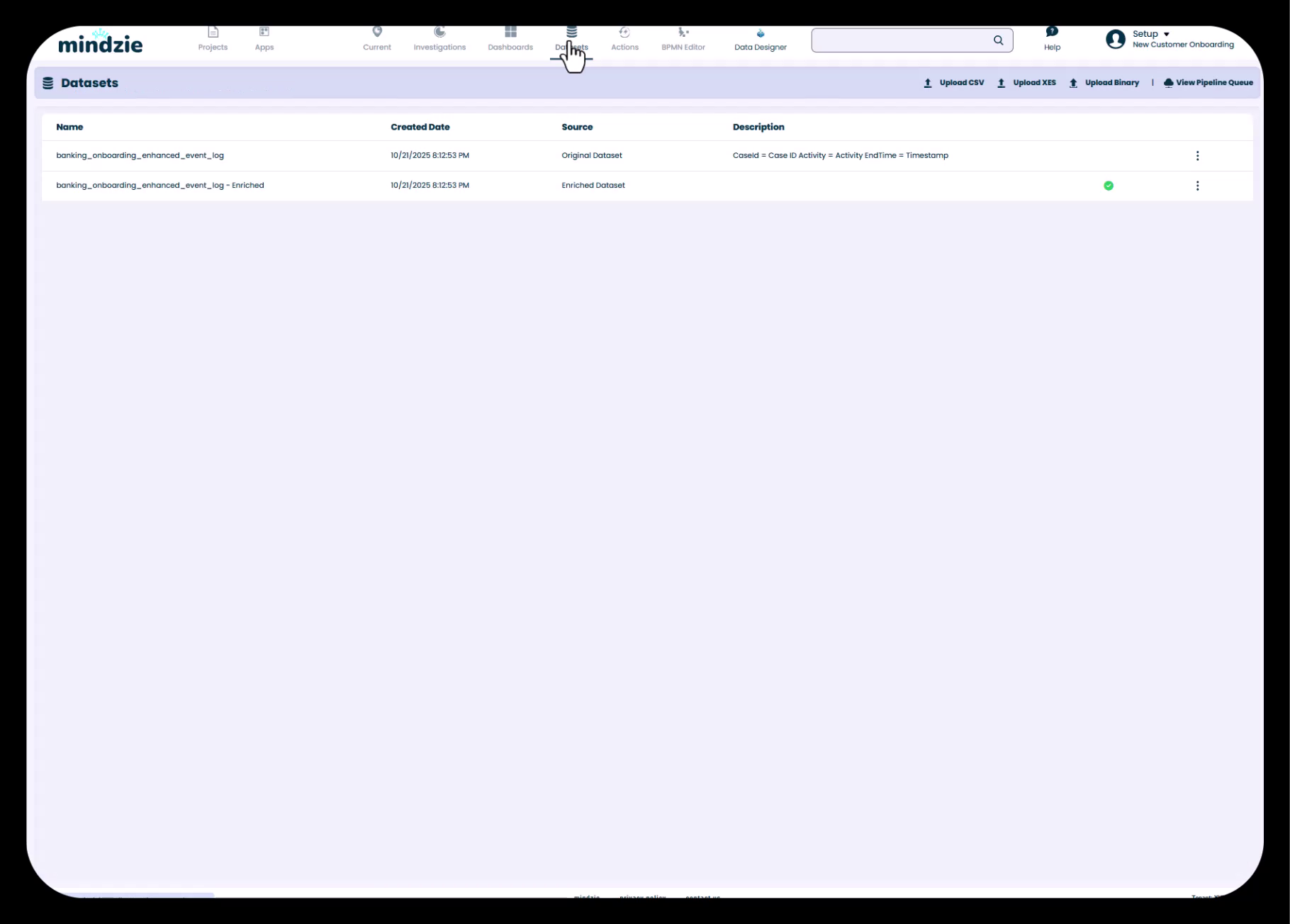 The Datasets view showing both the Original Dataset and the Enriched Dataset
The Datasets view showing both the Original Dataset and the Enriched Dataset
How the Data Pipeline Works
When you upload data to mindzie Studio, here's what happens automatically:
Step 1: Data Import and Validation
Your CSV file or data from mindzie Data Designer is loaded into mindzie Studio. The system:
- Validates the data format and structure
- Maps key columns (Case ID, Activity, Timestamp, Resource)
- Assigns column types and data types
- Creates the Original Dataset
Step 2: Automatic Pipeline Execution
Once you click "Save" after uploading your data, mindzie Studio automatically:
- Executes the data pipeline
- Creates the Enriched Dataset
- Adds foundational attributes that enhance your analysis capabilities
Step 3: Default Analysis Generation
To give you a quick start, mindzie Studio automatically generates helpful default analysis including:
- Process overview
- Long case durations
- Durations between main process steps
- Other key insights
These pre-built analyses help you start exploring your process immediately without having to create everything from scratch.
 Default investigation created automatically upon data import
Default investigation created automatically upon data import
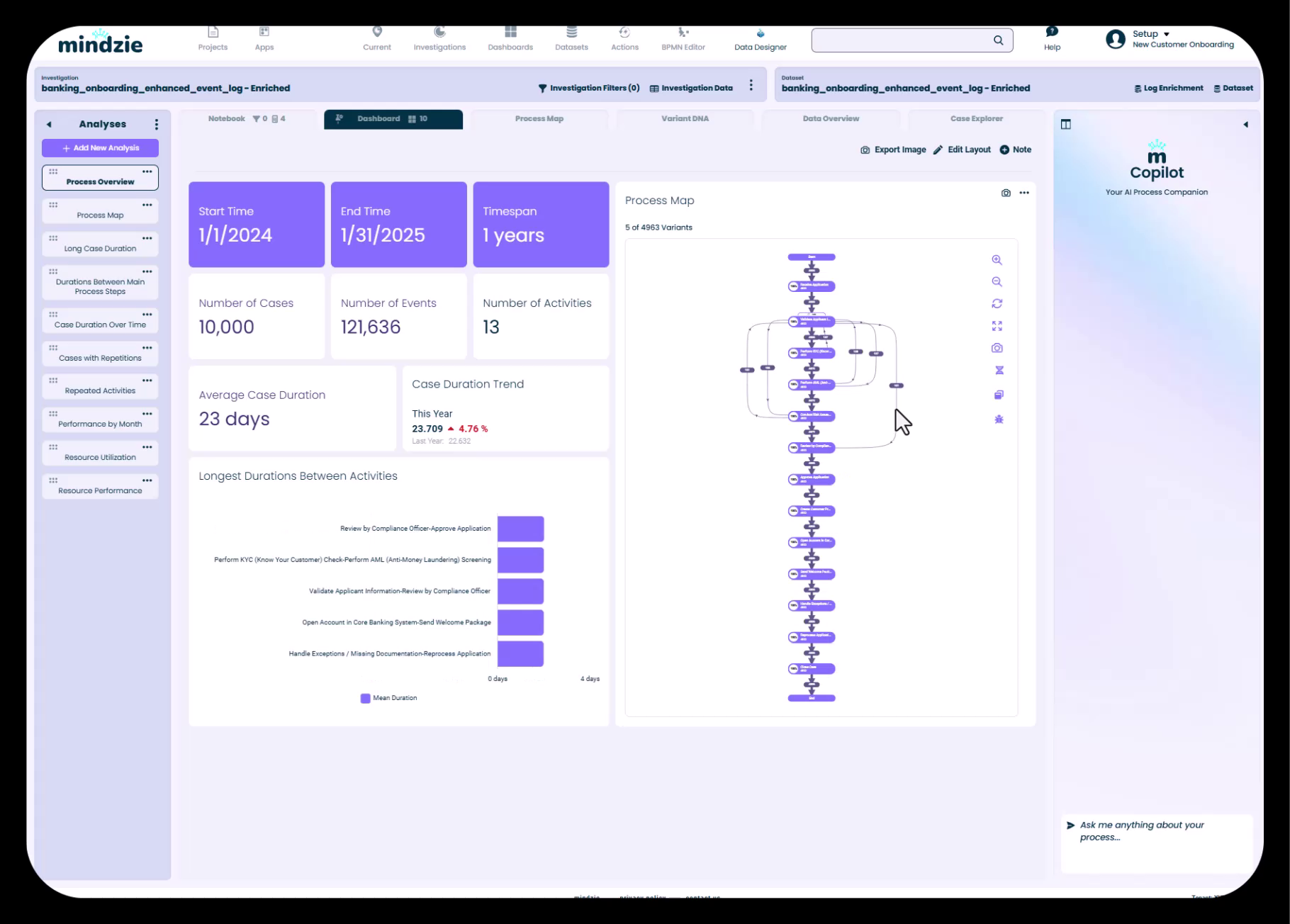 Default analysis showing 10,000 cases and 121,000 events with key process insights
Default analysis showing 10,000 cases and 121,000 events with key process insights
Understanding Dataset Size: The Example
In the demonstration, the banking onboarding dataset contains:
- 10,000 cases - Each case represents one customer onboarding journey
- 121,000 events - The total number of process steps across all cases
This means that on average, each customer onboarding case involves approximately 12 activities or process steps. This type of information becomes immediately visible once your data is loaded into mindzie Studio.
The Role of Log Enrichment
The power of the dual dataset architecture becomes clear when you start using the log enrichment engine. This is where the Enriched Dataset truly differentiates itself from the Original Dataset.
What Log Enrichment Does
Log enrichment allows you to enhance your data with:
Performance Metrics:
- Duration calculations between activity pairs
- Case duration from start to finish
- Performance bucketing (fast, normal, slow)
- Custom SLA compliance tracking
Conformance Rules:
- Flags for undesired activities
- Missing mandatory steps
- Wrong activity order
- Repeated activities and rework loops
Custom Attributes:
- Activity-based costing
- AI predictions
- Custom categorizations
- Mathematical transformations
- Time-based calculations
How Enrichments Update the Dataset
Each time you create new enrichments and calculate them:
- The data pipeline executes
- New attributes are added to the Enriched Dataset
- These new attributes become available for use in filters and calculators
- Your analysis becomes more powerful with each enrichment
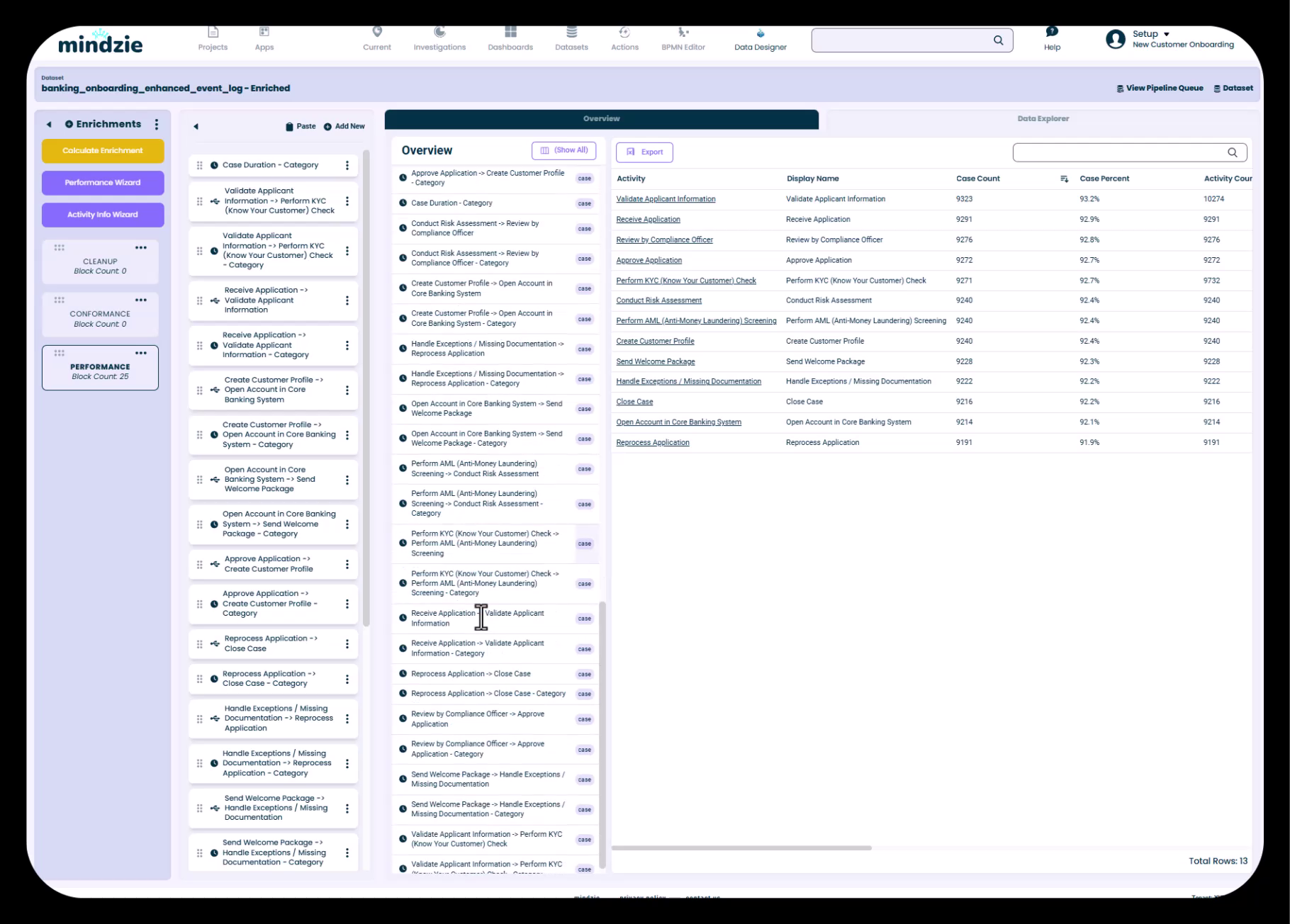 Data overview showing both original attributes and enriched attributes with icons indicating system-generated enhancements
Data overview showing both original attributes and enriched attributes with icons indicating system-generated enhancements
Automatic Attributes Added by mindzie
Even without any manual enrichments, mindzie Studio automatically adds several useful attributes to your Enriched Dataset, including:
- Time of Day - When activities occurred
- Case Start - When each case began
- Case Finish - When each case ended
- Case Duration - Total time from start to finish
- First Resource - Who initiated the case
- Activity Frequency - How often activities occur
- And many more...
These automatic enrichments give you immediate analytical capabilities without any configuration.
Choosing the Right Dataset for Analysis
When creating investigations and analysis notebooks in mindzie Studio, you need to select which dataset to analyze.
Best Practice: Always select the Enriched Dataset for your investigations and analysis work. This dataset contains all the enhanced attributes and calculated metrics that make your analysis powerful and insightful.
The Original Dataset should primarily be used for:
- Reference and validation purposes
- Data quality audits
- Understanding the source data structure
The Continuous Enhancement Cycle
The dual dataset architecture supports an iterative workflow:
- Upload - Import your data to create the Original Dataset
- Enrich - Add performance metrics, conformance rules, and custom attributes
- Calculate - Execute the pipeline to update the Enriched Dataset
- Analyze - Create investigations and analysis using the enriched attributes
- Repeat - Add more enrichments as needed to deepen your insights
Each cycle makes your Enriched Dataset more valuable and your analysis more sophisticated.
Key Takeaways
- Two datasets are created: Original (raw data) and Enriched (enhanced data)
- Automatic creation: The Enriched Dataset is created automatically when you upload data
- Use the Enriched Dataset: This is your primary dataset for all analysis and investigations
- Pipeline execution: The data pipeline transforms Original into Enriched
- Continuous enhancement: Each enrichment calculation adds new attributes to the Enriched Dataset
- Default analysis: mindzie Studio provides helpful starter analysis automatically
- Iterative process: You can continue adding enrichments to make your analysis more powerful