適合性分析
概要
適合性分析では、あなたのプロセスがどうあるべきかを定義し、実際のケースがそのプロセスにどの程度従っているかを自動でチェックできます。これは、「私のケースは想定通りに実行されていますか?」という質問に答えます。
これを行うには、プロセスのバリアントを順に見ていき、正しいものを承認し、正しくないものを拒否します。拒否したバリアントには、期待されるプロセスから逸脱している理由を文書化できます。説明の作成にはオプションでAI支援が利用可能です。mindzieは承認されたバリアントからプロセスモデルを作成し、他のすべてのバリアントに対してスコアリングを実施します。
結果として得られるのは、文書化されたプロセスであり:
- 良いバリアントはプロセスが「どうあるべきか」を定義する(リファレンスモデル)
- 悪いバリアントは「どこで何が問題になるか」を説明する(逸脱カタログ)
- その他のすべてはこのモデルに基づいて自動分類される
はじめに
- 上部メニューのConformanceに移動
- 右上のドロップダウンからデータセットを選択
- バリアントのトリアージを上から順に(頻度が高いものから)行う:
- チェックマークをクリックしてバリアントを良品としてマーク(ワンクリックで完了)
- ×ボタンをクリックしてバリアントを不良品としてマークすると、ノート欄が自動展開
- 不良品のバリアントに対しては逸脱理由を文書化:理由を入力するか、キラキラボタンをクリックしてAIに生成させる
- Build & Check Conformanceをクリックしてプロセスモデルを構築し、適合検証を実行
- 結果を確認:各バリアントは適合度スコアが付き、「Fits」か「Fails」に分類される
- 必要に応じてThresholdスライダーで適合チェックの厳しさを調整
- Save Modelをクリックして適合モデルと逸脱ノートを保存し、エンリッチメントで利用可能にする
仕組み
ステップ1:バリアントのトリアージ
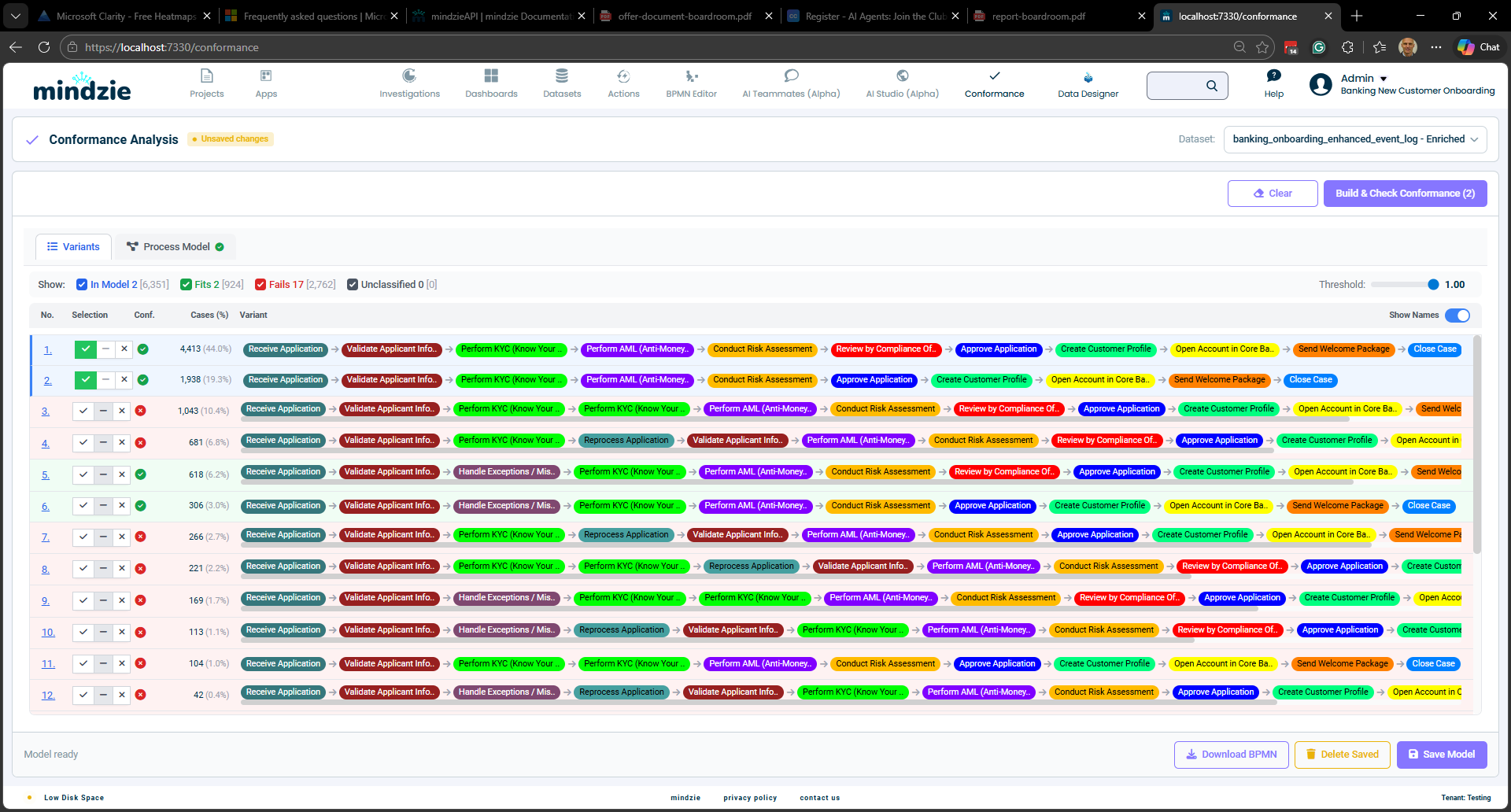
Variantsタブには、データセット内の全てのプロセスバリアントが頻度順(多い順)に表示されます。各行は一意の活動シーケンスを表し、色付きの活動ラベルでプロセスフローが示されています。
上から順にリストを見ながら、各バリアントに対して3つのボタンのいずれかをクリックします。
- Good(チェックマーク)— このバリアントは正しいプロセス実行を表します。ワンクリックで完了、追加入力不要。
- Bad(×ボタン)— このバリアントは既知の異常です。×をクリックすると、そのバリアントの下にノート行が自動展開され、逸脱理由を記録可能。
- Unclassified(ダッシュ)— 適合性に基づいてシステムに自動判定させます。デフォルト状態。
自動分類されたバリアントも、選択ボタンから手動でオーバーライド可能です。
逸脱理由の文書化
バリアントをBadにマークすると、その直下にインラインのノート行が表示されます。そこには:
- テキストエリアがあり、このバリアントが期待されるプロセスから逸脱している理由を入力可能
- キラキラボタン(あなたのテナントでAIが設定されている場合)をクリックすると、逸脱説明が自動生成されます
AIは承認済みの良いバリアントを参照し、不良バリアントと比較して何が異なるか(不足している活動、余計なステップ、順序ミス、繰り返し)を特定します。生成された説明はテキストエリアに挿入され、内容の承認や編集が可能です。
ノートは任意入力です。理由なしにバリアントをBadにマークしても構いませんが、逸脱の記録は報告や教育、継続的改善に役立つ貴重なカタログが作成されます。
ノートを閉じるだけにしたい場合は、ノート行右側の折りたたみ矢印をクリックしてください。保存済みのメモがあるバリアントは折りたたんでも小さなノートアイコンが表示されます。
ステップ2:プロセスモデルの構築
Build & Check Conformanceをクリックすると、mindzieは以下の2つの処理を行います。
プロセス発見 — mindzieは承認された良いバリアントを分析し、有効な全実行パスを含む構造化されたプロセスモデルを生成します。モデルは以下を特定します:
- 活動の順序
- プロセスが分岐する決定点(XORゲートウェイ)
- 活動が同時並行で進む並行パス(ANDゲートウェイ)
- スキップ可能なオプション活動
- 活動の繰り返し(ループ)
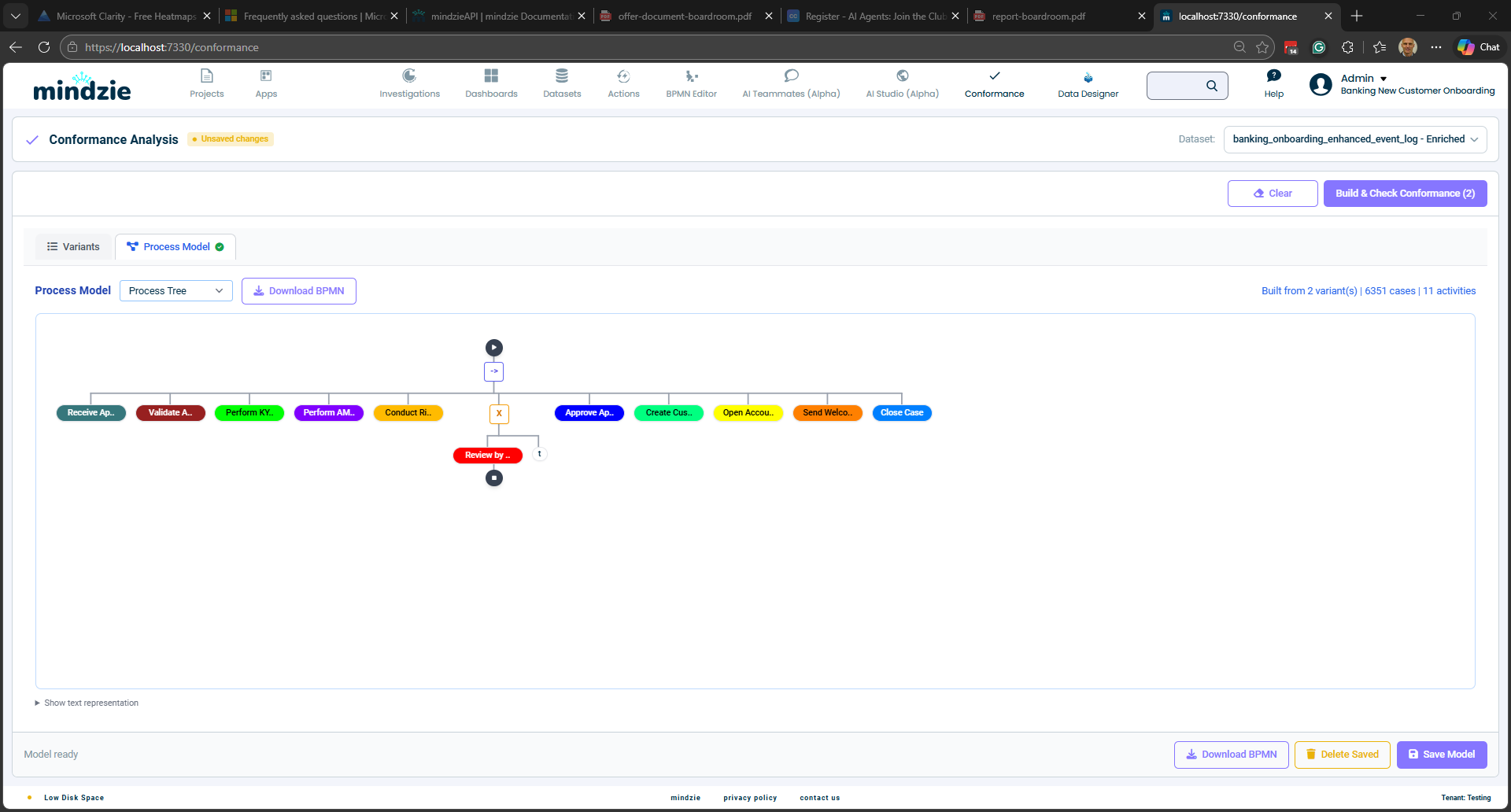
発見されたモデルは2つのフォーマットで表示されます。
プロセスツリー — プロセスの構造を階層的に表示。シーケンス、選択、並行、ループといった演算子と活動ノードを示す。
BPMNダイアグラム — 開始/終了イベント、活動ボックス、ゲートウェイダイヤモンドを用いた標準的なビジネスプロセスモデル&表記図。
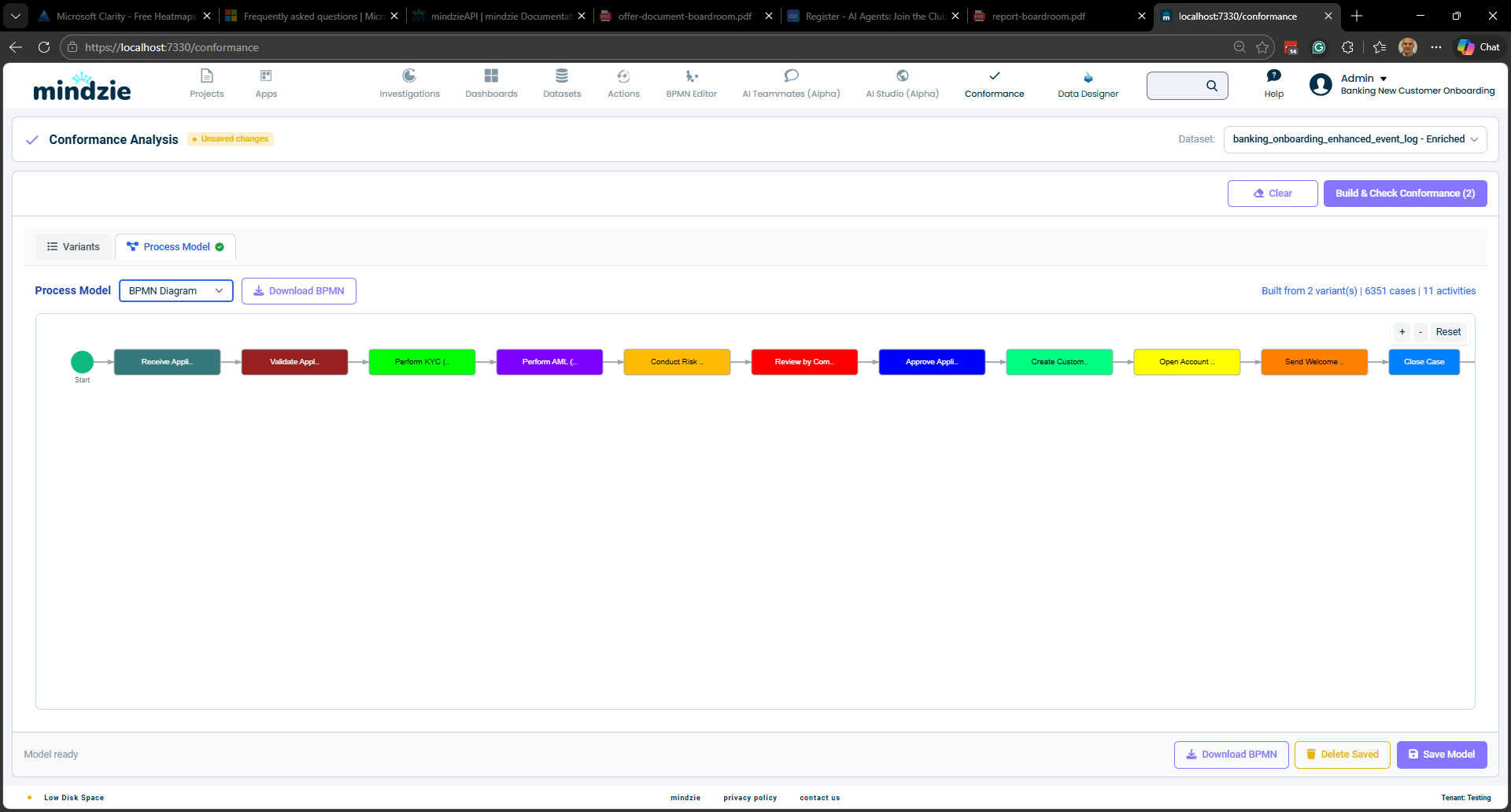
これらの表示はProcess Modelドロップダウンで切り替え可能です。また、Download BPMNボタンでBPMNファイルをXML形式でダウンロードできます。
ステップ3:適合性のチェック
モデル構築後、mindzieはモデルをペトリネット(プロセスの数学的モデル)に変換し、トークンリプレイを用いて各バリアントをチェックします。
トークンリプレイは、各ケースの実行をペトリネット上でシミュレートします:
- プロセスの開始位置にトークンを配置
- ケース内の各活動に対して、対応するモデル内の遷移をトークンが通過できるか試行
- 通常通り遷移が発火すれば、そのステップは適合している
- 遷移が発火しない場合(順序違反や予期しない活動)には適合違反が記録される
- すべての活動後、トークンがプロセスの終端に到達したか確認
このシミュレーションで以下の4つの指標が得られます:
| 指標 | 意味 |
|---|---|
| 消費トークン(Consumed tokens) | 再生中に使用されたトークンの総数(実行された活動) |
| 生成トークン(Produced tokens) | 再生中に生成されたトークンの総数(発火した遷移) |
| 不足トークン(Missing tokens) | モデル状態が適切でないため補填されたトークン |
| 残留トークン(Remaining tokens) | 再生後に残ってはいけないはずのトークン |
適合度スコア
適合度スコアは0.0から1.0の間で、バリアントがモデルにどれだけ適合しているかを数値化します:
Fitness = 0.5 x (1 - missing/consumed) + 0.5 x (1 - remaining/produced)
- 1.0 = 完全な適合。バリアントはモデルに完全に従う。
- 0.8 = 良好な適合。軽微な逸脱あり。
- 0.5 = 低い適合。大きな逸脱を含む。
- 0.0 = 適合なし。モデルと全く異なっている。
逸脱が適合度を下げる仕組み
不足トークンはモデルが想定しない活動がケースで発生したときに生じます:
- 活動が順序通りに実施されていない
- 活動がスキップされ、その次の活動が起動できない
残留トークンは期待されるプロセスが完了しなかった場合に生じます:
- ケースが最終状態に達する前に終了
- 並行プロセスの一方の分岐が完了しない
非マッピング活動は、ケースにモデルに存在しない活動が含まれている場合に発生:
- 良いバリアントに存在しない余分なステップがある
- 非マッピング活動はトレース長に応じて適合度を減少させる
バリアントが完全に適合していると見なされるためには、 不足トークン・残留トークン・非マッピング活動すべてがゼロである必要があります。
Threshold(閾値)
Thresholdスライダー(0.0~1.0)は適合チェックの厳しさを制御します:
- 1.0(最も厳しい):モデルに完全に一致するバリアントのみが「Fits」判定
- 0.95(推奨):軽微な逸脱を含むバリアントも合格
- 0.8:中程度の逸脱を含むバリアントも合格
- 0.5:大きな逸脱があるバリアントのみ不合格
分類への影響
適合性チェック後、システムは各バリアントを以下のように分類します:
| フィルター | 色 | 意味 |
|---|---|---|
| In Model | 青 | 明示的に良品として選択したバリアント |
| Fits | 緑 | 未選択だが適合度閾値を満たすバリアント |
| Fails | 赤 | 未選択で閾値を満たさないバリアント |
| Unclassified | 灰 | 未チェックのバリアント |
上部のフィルターチェックボックスで各カテゴリを表示・非表示切替可能。
閾値1.0で未選択バリアントが合格することは?
はい。未選択でも、プロセスモデル内で完全に有効なパス(すべての活動がモデルに存在し、遷移が正しく発火し、最終状態に到達)を辿るバリアントは、適合度1.0を獲得し「Fits」と分類されます。これは意図的な挙動で、モデルは選択したバリアントの正確なパターンだけでなく、すべての有効なパスを表現しています。
例えば、2つの異なる分岐を含む2つのバリアント(Aの後B、あるいはAの後C)を選択すると、モデルは選択ゲートウェイを作成します。そのため、それらのパスに完全に従う他のバリアントも1.0のスコアになります。
新規バリアントの自動分類
適合モデルを保存しエンリッチメントとして適用すると、後から到着した新規ケースは自動分類されます:
- 以前に良品として選択されたバリアントと一致するケースはGood
- 以前に不良品として選択されたバリアントと一致するケースはAnomaly
- 新たに見たことのないバリアントは保存済みモデルでトークンリプレイ実行により自動分類
- 適合度が閾値以上なら:Good(出所:AutoConformance)
- 閾値未満なら:Anomaly(出所:AutoConformance)
これにより、適合ルールは長期間にわたって新しいデータ受信時も手動再分類なしに機能し続けます。
モデルの保存と利用
モデルの保存
Save Modelをクリックすると適合モデルが保存されます。以下が保存対象:
- バリアントの選択状態(良品/不良品/オーバーライド)
- 不良品バリアントの逸脱ノート
- 発見されたプロセスモデル(BPMN、ペトリネット)
- 適合度閾値設定
保存されたモデルはデータセットのエンリッチメントオペレーターとして登録され、データセット更新時に自動実行されます。
エンリッチメント出力
適合モデルがエンリッチメントとして動作すると、ケースデータに以下の5つの列が追加されます:
| 列名 | 型 | 値の例 |
|---|---|---|
| Is Variant Anomaly | ブール値 | Yes / No |
| Variant Classification | テキスト | "Good" or "Anomaly" |
| Variant Fitness Score | パーセント | 0%~100% |
| Classification Source | テキスト | "Explicit", "UserOverride", "AutoConformance" |
| Deviation Reason | テキスト | 逸脱理由(記録したノートの内容) |
Deviation Reason列はBadにマークした際に記入またはAI生成したノートから自動挿入されます。明示的に拒否し理由を記録したバリアントはそのメモが正確に表示され、AutoConformanceによる自動分類の異常はノートがなければ空欄です。
これらの列はフィルターや計算式、ダッシュボードに利用でき、プロセス適合性の分析に役立ちます。特にDeviation Reason列は、よくある逸脱原因の把握や改善策の検討に有用です。
BPMNのダウンロード
Download BPMNボタンからプロセスモデルを標準BPMN 2.0 XMLファイルとしてエクスポート可能。任意のBPMN対応ツールで開き、さらなる解析や資料作成に活用できます。
ワークフロー例
適合性分析設定の典型的なワークフロー例:
- データセットを読み込みConformanceページに移動
- バリアントリストの上から着手(頻度順なので重要パスが先に表示される)
- 各バリアントをトリアージ:
- 正しいパスはチェックマーククリック(ワンクリックで完了)
- 既知の異常には×クリック、ノート欄に理由を記入
- 判断が難しいバリアントは未分類のままモデル任せに
- AI支援で逸脱説明を作成— キラキラボタンをクリックし、不良バリアントと承認済み良品の比較説明を生成
- Build & Check Conformanceをクリックしてモデル生成と全バリアント分類を実行
- Process Modelタブに切り替えて発見されたBPMN図を確認
- 閾値を調整し、逸脱の許容度に合わせる
- 結果を確認:フィルター活用でFailバリアントに絞り、逸脱理由を把握
- Save Modelでモデル・ノートを保存し、将来データの自動分類を有効化
- エンリッチメント列を使いダッシュボードを作成し、適合性の経時的推移に対応
AI支援による逸脱説明
テナントにAI設定がある場合、Badにマークしたノート欄の横にキラキラボタンが表示されます。クリックすると次の文脈をAIに送信:
- あなたがGoodにマークした全バリアント(予想されるプロセスパス)
- Badにマークした特定バリアント(逸脱)
AIは両者を比較し、1~2文の解説を生成:
- 余計な活動 — 良品に存在しないステップ
- 不足する活動 — 良品にあり不良バリアントに欠けているステップ
- 誤った順序 — 別の順序で実行されているステップ
- 繰り返しの活動 — 期待より多く繰り返されるステップ
生成文はテキストエリアに挿入され、そのまま受け入れるか修正したり完全に置換可能。AI利用は任意で、設定されていないテナントではキラキラボタンが表示されず、手入力も可能です。
ヒント
- 少数の良品バリアントから開始:選択しすぎると過度に許容的なモデルになるため、コアのハッピーパスを代表する1~3件がおすすめ
- 上から順に作業:頻度順に並んでいるため、まず主要パスを分類することで効率よくカバー可能
- 逸脱はすぐに記録:Badにマークした時に理由を書くだけで数秒。しかし継続的な文書化により貴重な資料が蓄積される。AI活用も検討を
- プロセスツリー表示を活用し、特に分岐点やオプショナル活動の構造を理解
- 閾値はまず0.95に設定:1.0は非常に厳しく微細な違いも不適合に判定されるため、まず0.95で様子見し調整推奨
- Classification Source列を確認:明示選択、オーバーライド、自動分類のいずれかで分類の出所を把握し、監査や分析に活用
- 逸脱理由列はダッシュボードで有効活用:最も頻出する逸脱原因レポートの作成や対策優先度決定に役立つ
- 他のエンリッチメントと組み合わせて利活用:例として「Is Variant Anomaly」列を異常ケースの根本原因分析や適合傾向のトレンド分析に利用可