データソースのアップロードと設定
概要
このガイドでは、CSVデータをmindzie Studioにアップロードし、プロセスマイニング分析のための主要な列を設定する手順を説明します。データ列を適切にマッピングすることは、mindzieがビジネスプロセスを効果的に分析するために不可欠です。
前提条件
データをアップロードする前に、以下を確認してください:
- プロセスイベントログデータを含むCSVファイル
- 最低限、次の列がデータに含まれていること:
- Case ID:各プロセスインスタンスの一意識別子
- Activity:各プロセスステップやアクティビティの名称
- Timestamp:各アクティビティが発生した日時
- Resource(推奨):アクティビティを実行した人物またはシステム
データインポート方法の選択
mindzieでは、プロジェクトにデータをインポートする主要な方法を2つ提供しています:
CSVアップロード
推奨用途:
- 一回限りのデータ分析
- テストや概念実証プロジェクト
- 小規模データセット
- 手動でのデータ更新が必要な場合
mindzie Data Designer
推奨用途:
- 継続的な監視と定期的な更新
- データベースやデータウェアハウスに直接接続
- 複雑なETL変換
- 本番環境での自動データ更新
本ガイドは、mindzie Studioをすぐに始めるための最速の方法であるCSVアップロードに焦点を当てています。
ステップバイステップ:CSVファイルのアップロード
ステップ1:Datasetsエリアに移動
mindzie Studioのプロジェクトに初めて入ると、自動的にDatasetsセクションに移動します。もし既にいない場合は:
- 上部ナビゲーションバーのDatasetsタブをクリック
- 「Welcome to mindzieStudio」画面が表示され、いくつかのオプションが見えます
ステップ2:Upload CSVを選択
Datasets画面で、画面右上のUpload CSVボタンをクリックします。ファイルブラウザダイアログが開きます。
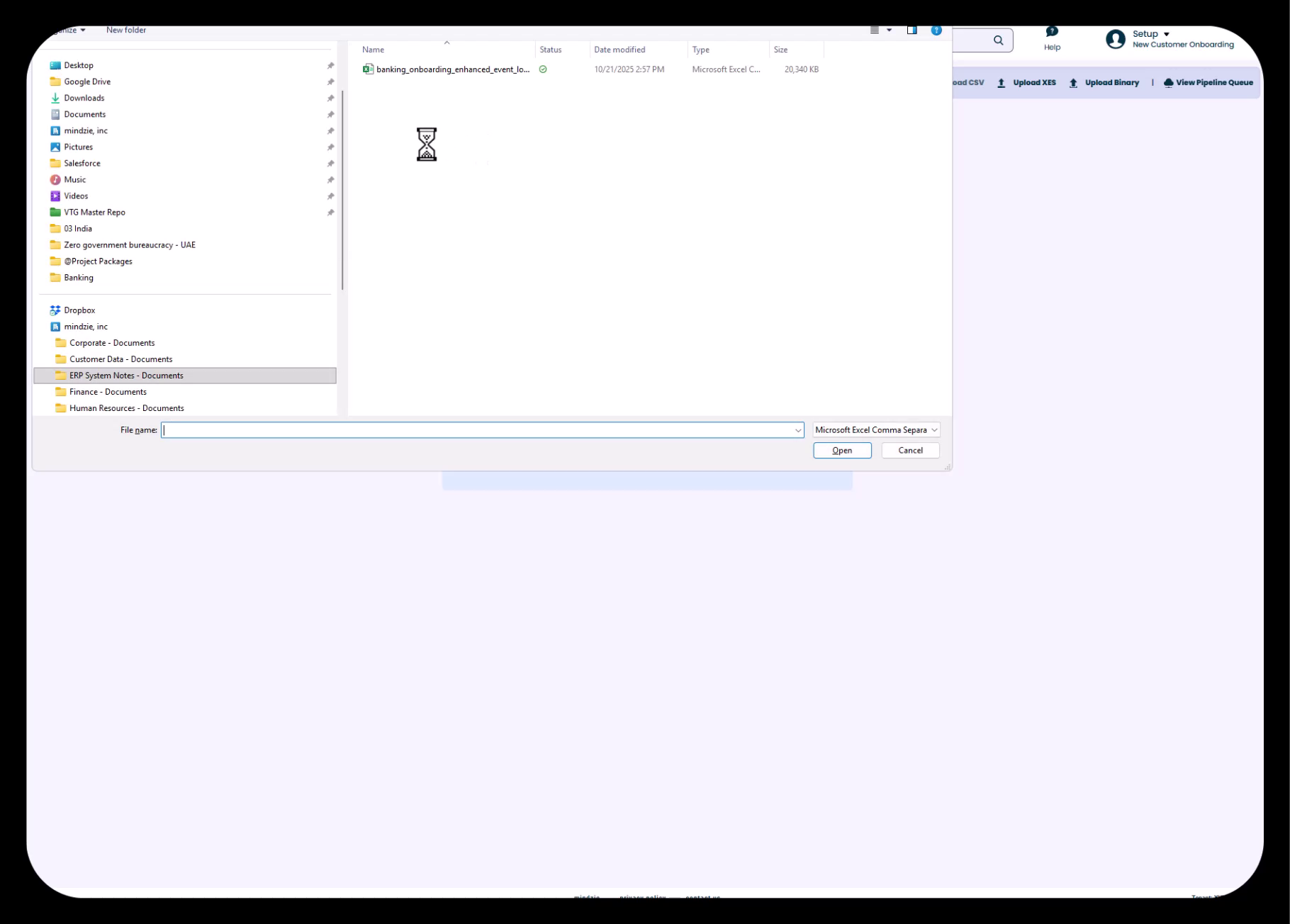
ステップ3:CSVファイルを選択
- コンピュータ上でCSVファイルの場所に移動
- ファイルを選択(例:
banking_onboarding_enhanced_event_log.csv) - Openをクリックしてアップロードを開始
アップロードの進捗を示す読み込みインジケーターが表示されます。
ステップ4:データ設定の検証と構成
ファイルがアップロードされた後、mindzie Studioはデータのプレビューを表示し、設定を行うことができます:
エンコーディング設定
- システムがファイルのエンコーディングを自動検出
- 特殊文字を含む場合、エンコーディング設定の調整が必要になることがあります
データプレビュー
- データが正しく読み込まれているかプレビューを確認
- 列が正しく区切られているかチェック
- タイムスタンプやその他の値が期待通りに表示されているか確認
設定を確認したら、Nextをクリックして列のマッピングへ進みます。
主要列の設定
列マッピング画面では、mindzie Studioに対してCSVのどの列がプロセスマイニングの主要フィールドに対応するかを指定します。
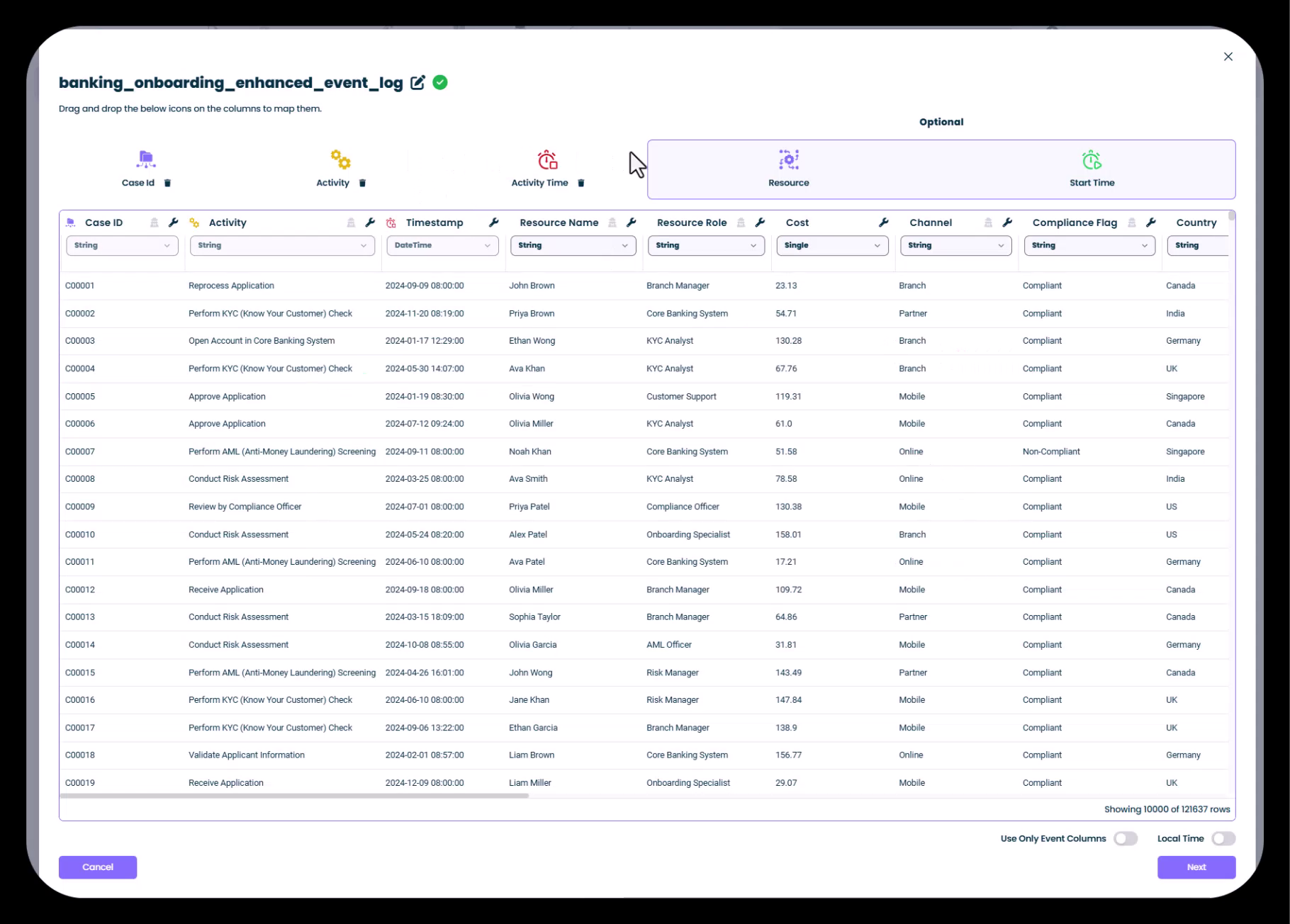
主要列アイコンの意味
mindzie Studioは視覚的なアイコンを使って主要列の識別とマッピングを補助します:
- Case ID:紫のアイコン - ユニークなプロセスインスタンスを識別
- Activity:黄色のアイコン - プロセスステップ名を含む
- Activity Time:オレンジのアイコン - 各アクティビティのタイムスタンプ
- Resource:青のアイコン - アクティビティを実行した人やシステム
ステップ5:ドラッグ&ドロップで列をマッピング
mindzie Studioは一般的な列名を自動検出し、マッピングを提案します。マッピングの指定や変更は以下の方法で行います:
- 自動検出:通常、Case ID、Activity、Timestampなどの標準列を自動的に検出
- ドラッグ&ドロップ:列を下部のリストから上部の主要列ボックスへドラッグして手動で割り当て
- Resourceの割り当て:リソース列がある場合(推奨)、Resourceフィールドへドラッグ
例では:
- Case ID は
Case ID列にマッピング - Activity は
Activity列にマッピング - Timestamp は
DateTime列にマッピング - Resource Name は
Resource Name列にマッピング
ステップ6:追加の列設定を行う
データセット内の各列に対して以下の操作が可能です:
列タイプの変更
- 任意の列をクリックしてタイプを変更
- 選択肢には文字列、数値、日付、ブール値などがあります
データタイプの修正
- mindzieがデータをどのように解釈するかを調整
- 日付をタイムスタンプとして認識させる
- 数値型の値を正しく認識させる
機微情報の匿名化
- 個人情報など機微なデータを含む列の匿名化を有効化可能
- データプライバシー規制の遵守に役立ちます
- 名前、顧客IDなどの個人識別情報はマスクされます
オプション列 画面右側の「Optional」セクションでは、追加のプロセスマイニング属性をマッピングできます:
- Resource Role:リソースの職位または役割
- Cost:アクティビティに関連するコスト
- Channel:プロセスチャネル(例:支店、モバイル、オンライン)
- Compliance Flags:適合性や準拠のフラグ
- Country/Region:地理的属性
ステップ7:データセットの処理と保存
列マッピングが完了したら:
- マッピングの正確さを再確認
- Nextをクリックして処理を開始
mindzie Studioは以下を行います:
- CSVデータをmindzieのイベントログ形式に変換
- データの品質と構造を検証
- 分析用の基礎データセットを生成
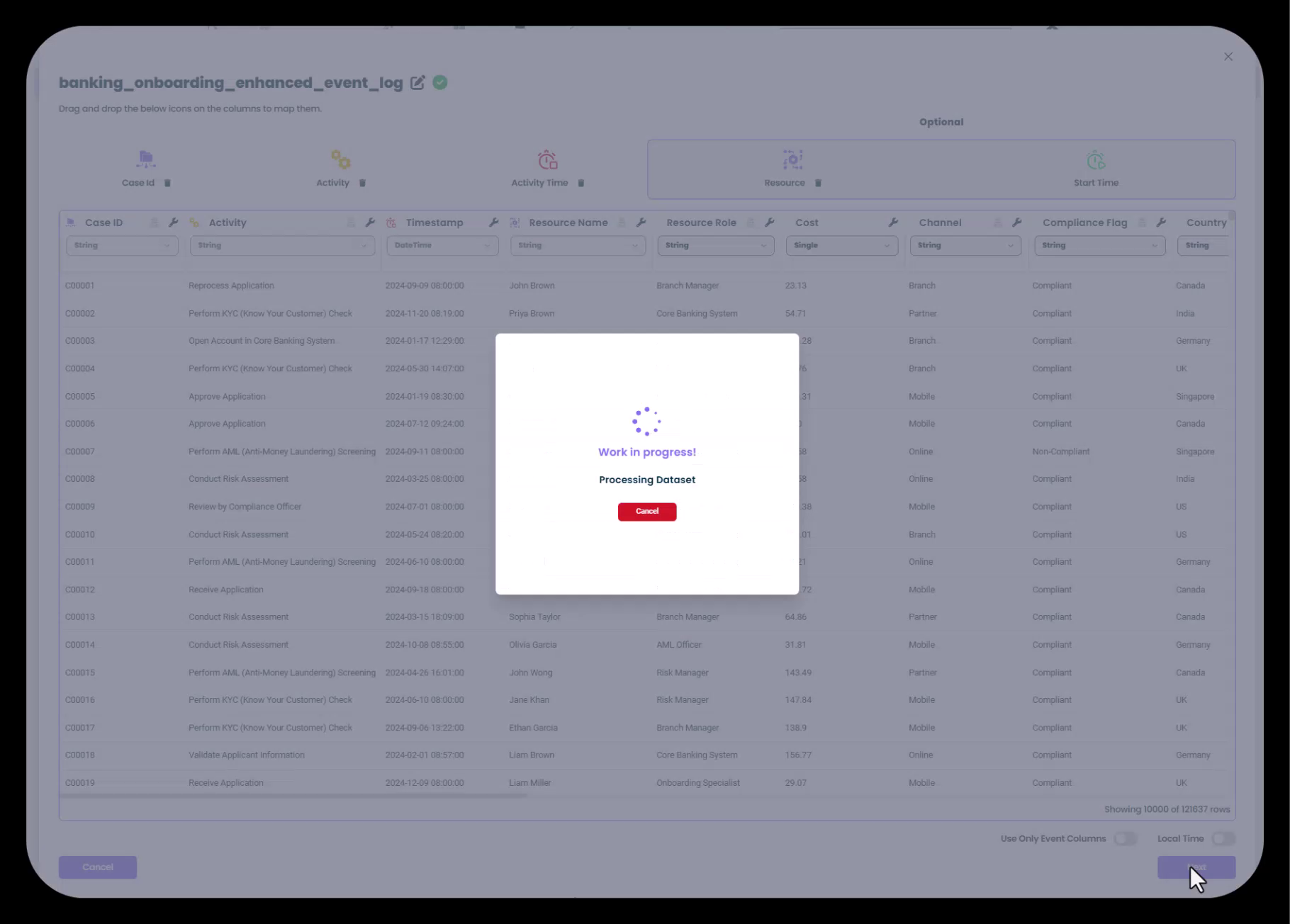
データセットのサイズによっては、処理に数分かかる場合があります。その間、「Work in progress! Processing Dataset」というダイアログが表示されます。
ステップ8:データインポート成功の確認
処理が完了するとmindzie Studioは以下を表示する確認ダイアログを出します:
- データセット名
- 合計ケース数(プロセスインスタンス数)
- 合計イベント数(アクティビティ数)
表示例では、データセットには:
- 10,000件のケース(一意の顧客オンボーディングインスタンス)
- 121,000件のイベント(すべてのケースにわたる合計アクティビティ)
Saveをクリックしてインポートを確定します。
データアップロード後の動作
データセットを保存するとmindzie Studioは自動で:
2つのデータセットを作成:
- Original Dataset:アップロードされた生のイベントログ
- Enriched Dataset:mindzieパイプラインによって作成された強化版(分析用)
データパイプラインを構築:パフォーマンス指標、準拠ルールなどでデータを強化する準備
デフォルト分析を生成:以下を含む初期分析を自動作成
- プロセス概要
- 長時間ケース分析
- メインのプロセスステップ間の期間
- その他の基礎的な洞察
これらのデフォルト分析はプロセス理解の出発点を提供し、カスタマイズや削除も可能です。
データ変換の理解
アップロードおよび処理フェーズで、mindzie Studioは:
- データ形式を標準化:CSVをmindzie最適化のイベントログ構造へ変換
- データ品質を検証:必須項目の欠落、無効なタイムスタンプ、不整合をチェック
- 強化準備を実施:計算属性、パフォーマンス指標、準拠ルールの追加が可能な構造へ整備
変換プロセスにより、強力なプロセスマイニング分析と可視化に適したデータが準備されます。
データアップロード成功のためのヒント
列名について
- CSV内の列名は明確で一貫性を持たせる
- 「CaseID」「Activity」「Timestamp」など一般的な名前は自動検出される
- 列名に特殊文字は使わない
データ品質
- 各行に必ずCase ID、Activity、Timestampを含める
- タイムスタンプは一貫したフォーマット(ISO 8601推奨)を使う
- 重複ヘッダーや不正な行は除去または修正する
ファイルサイズの考慮
- CSVアップロードは数百万イベントまでのデータセットに適している
- 非常に大きなデータや継続的な監視にはmindzie Data Designerの利用を検討
- まずデータのサンプルで列マッピングをテストすることを推奨
リソースおよびオプション列
- 必須はCase ID、Activity、Timestampのみだが、Resourceを加えると分析の深みが増す
- Cost、Channel、Regionなどの追加列はセグメント化や洞察を豊かにする
- 後からデータ強化機能でオプション列を追加可能
次のステップ
データソースを正常にアップロードし設定した後は:
- 生成されたデータセットを確認:Datasetsセクションでオリジナルと強化済みの両方をチェック
- デフォルト分析を探索:Investigationsで自動作成された洞察を閲覧
- ダッシュボード構成を計画:ユーザー向けのダッシュボードや指標を設計
- データを強化:Log Enrichment Engineを使い、パフォーマンス指標、準拠ルール、カスタム属性を追加
これでデータは実用的なプロセスインテリジェンスに変換可能です!
関連トピック
- mindzieの二重データセットアーキテクチャの理解:オリジナルと強化済みデータセットについて
- Log Enrichment Engineのマスター:パフォーマンス指標と準拠ルールでデータを強化
- mindzie Data Designerの使い方:ライブデータソースへの接続と自動データ更新
- 最初の分析の作成:アップロードデータから指標やKPIの構築