mindzieのデュアルデータセットアーキテクチャの理解
概要
mindzie Studioにデータをアップロードすると、プラットフォームは自動的に2つの異なるデータセットを作成し、これらが連携してプロセスマイニング分析を支えます。これらのデータセットの違いと、どのタイミングでどちらを使うべきかを理解することは、mindzie Studioを効果的に使いこなすための基本です。
このガイドでは、デュアルデータセットアーキテクチャ、mindzieのデータパイプラインがどのようにデータを変換するか、および初回データインポート時に自動的に何が起こるかを解説します。
2つのデータセット
Original Dataset
Original Datasetは、mindzie Studioに最初にアップロードする生のイベントログです。このデータセットはCSVファイルでアップロードされた場合も、mindzie Data Designerを通じてソースシステムから取り込まれた場合も、提供されたままのプロセスデータを含みます。
特徴:
- 生データを元の形で保持
- インポートしたカラムや属性のみを含む(Case ID、Activity、Timestamp、Resource、および追加属性)
- 分析中は変更されない
- すべての後続のデータ処理の基盤となる
Original Datasetの使用シーン:
- ソースデータの検証を行うとき
- データ品質チェック・検証のため
- 変換が行われる前の元のデータ内容を理解したいとき
Enriched Dataset
Enriched Datasetは、mindzie Studioのデータパイプライン実行後に自動的に作成されるデータセットです。計算されたすべての属性、パフォーマンス指標、適合性フラグ、ログエンリッチメントエンジンによって付加されたその他の強化情報を含む拡張版データです。
特徴:
- データインポート時に自動的に作成される
- 元の属性に加えて新たに計算された属性をすべて含む
- エンリッチメント計算を実行するたびに更新される
- すべての分析、調査、ダッシュボードの基盤となる
Enriched Datasetの使用シーン:
- すべての分析と調査作業で使用(分析の主要データセット)
- ダッシュボードやKPIの作成時
- パフォーマンス指標、適合ルール、カスタムエンリッチメントの活用時
- 日々のプロセスマイニング業務で
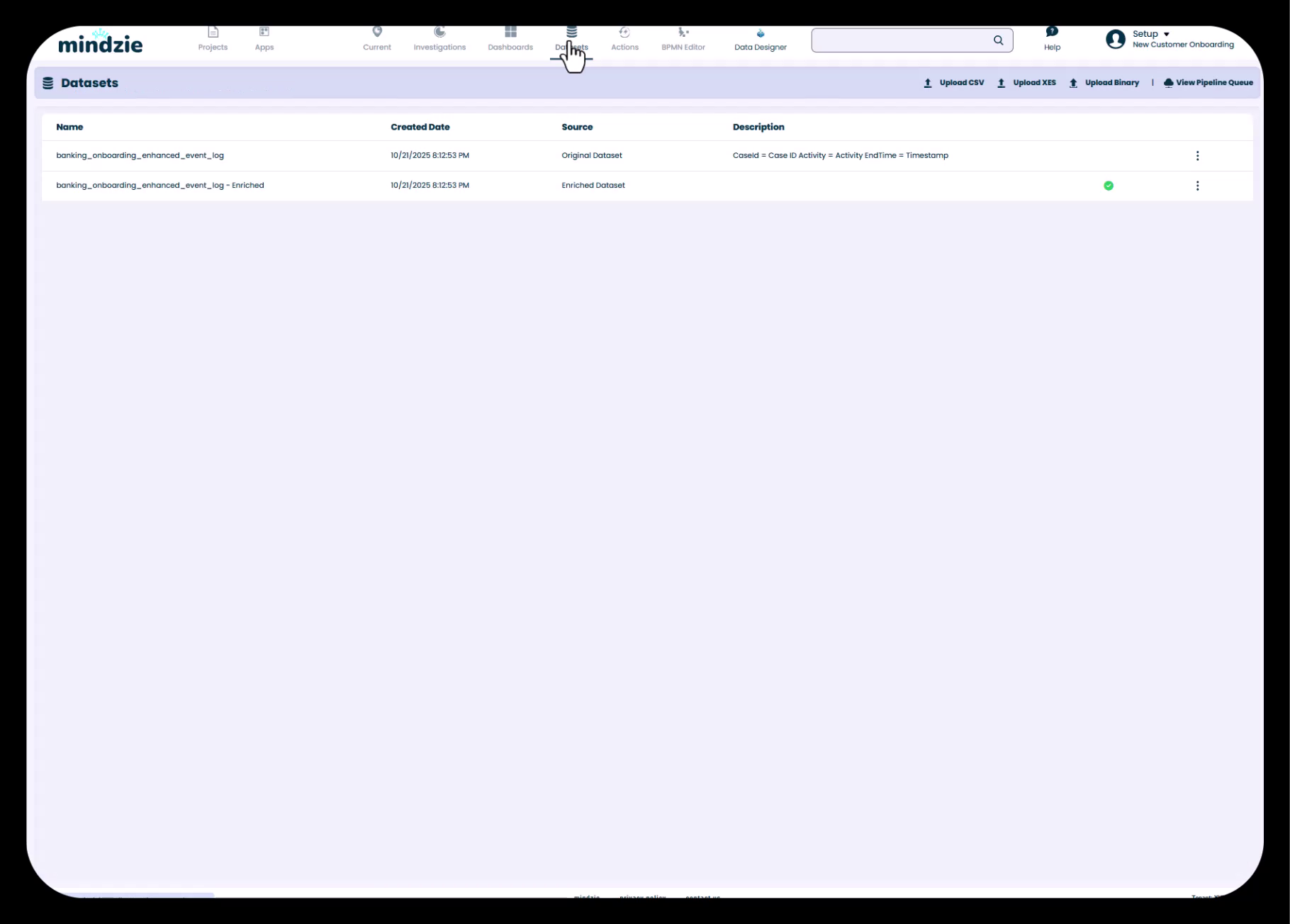 Original DatasetとEnriched Datasetの両方を表示したDatasetsビュー
Original DatasetとEnriched Datasetの両方を表示したDatasetsビュー
データパイプラインの仕組み
mindzie Studioにデータをアップロードすると、自動で以下のことが行われます:
ステップ1:データのインポートと検証
CSVファイルやmindzie Data Designerからのデータがmindzie Studioに読み込まれます。システムは:
- データフォーマットと構造の検証
- 主要カラム(Case ID、Activity、Timestamp、Resource)のマッピング
- カラムタイプとデータタイプの割り当て
- Original Datasetの作成
ステップ2:自動パイプライン実行
データアップロード後に「保存」をクリックすると、mindzie Studioは自動的に:
- データパイプラインを実行
- Enriched Datasetを作成
- 分析能力を強化する基礎属性を追加
ステップ3:デフォルト分析の生成
すぐに分析を開始できるよう、mindzie Studioは以下の役立つデフォルト分析を自動生成します:
- プロセス概要
- 長時間を要したケース
- 主要プロセスステップ間の期間
- その他の重要なインサイト
これらの事前構築済み分析により、一から作成しなくてもすぐにプロセス探索を始められます。
 データインポート時に自動作成されるデフォルト調査
データインポート時に自動作成されるデフォルト調査
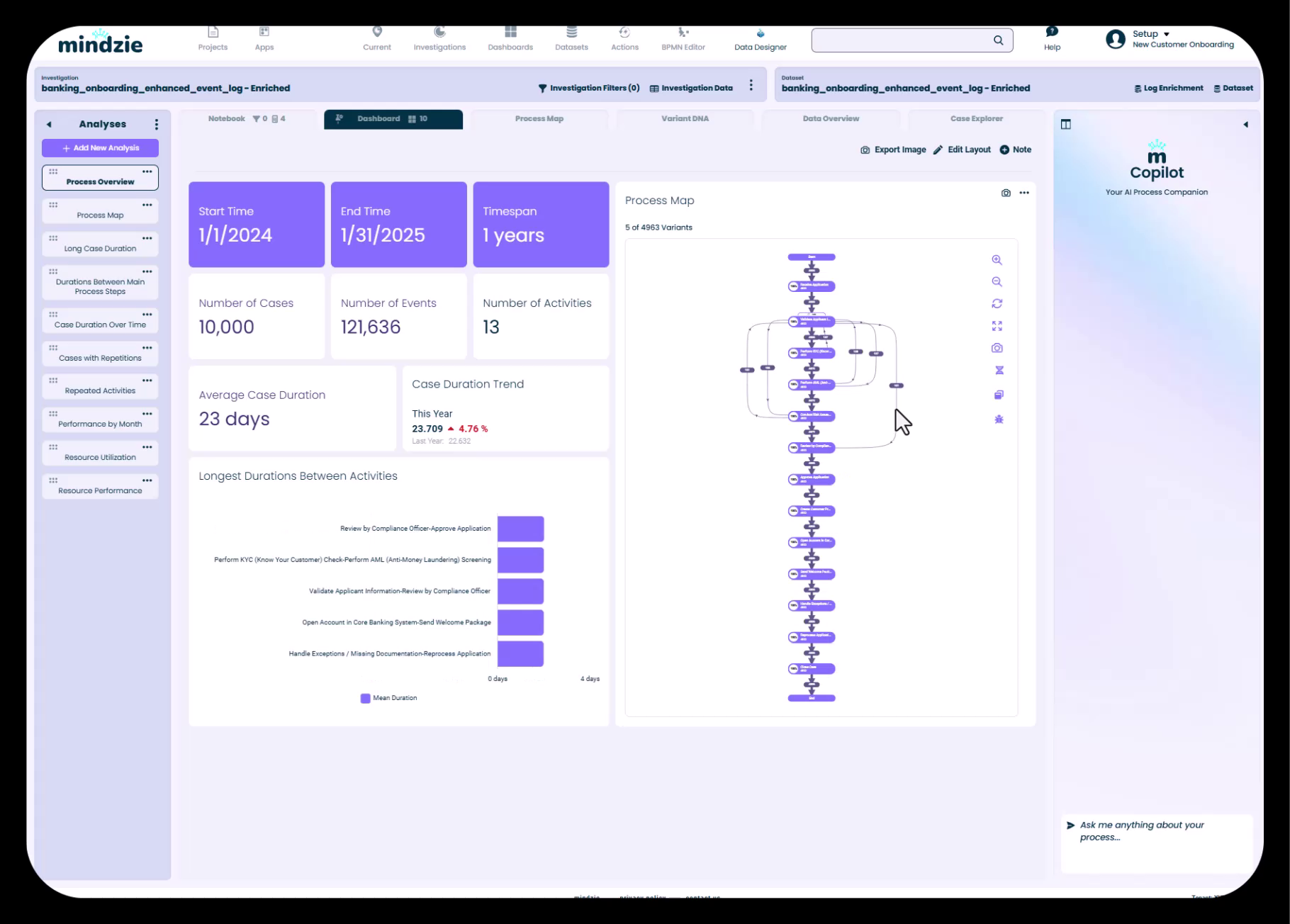 10,000件のケースと121,000件のイベントを示すデフォルト分析、主要なプロセスインサイト付き
10,000件のケースと121,000件のイベントを示すデフォルト分析、主要なプロセスインサイト付き
データセットのサイズ理解:例
デモでは、バンキングのオンボーディングデータセットに:
- 10,000件のケース - 各ケースは1つの顧客オンボーディングの旅を示す
- 121,000件のイベント - すべてのケースに渡るプロセスステップの合計数
つまり平均すると、1件の顧客オンボーディングケースあたり約12のアクティビティ(プロセスステップ)が含まれていることになります。データをmindzie Studioにロードすると、この種の情報がすぐに見えるようになります。
ログエンリッチメントの役割
デュアルデータセットアーキテクチャの真価は、ログエンリッチメントエンジンの使用時に明確になります。Enriched DatasetがOriginal Datasetと明確に差別化されるのはここです。
ログエンリッチメントが行うこと
ログエンリッチメントにより、データを以下のように強化できます:
パフォーマンス指標:
- アクティビティペア間の期間計算
- ケースの開始から終了までの総期間
- パフォーマンスの階層(速い、通常、遅い)
- カスタムSLAコンプライアンス追跡
適合ルール:
- 望ましくないアクティビティのフラグ設定
- 必須ステップの欠落検知
- 誤ったアクティビティ順序
- 繰り返しアクティビティや再作業ループ
カスタム属性:
- アクティビティベースのコスト計算
- AI予測
- カスタムカテゴリ分類
- 数学的変換
- 時間ベースの計算
エンリッチメントによるデータセットの更新方法
新しいエンリッチメントを作成して計算するたびに:
- データパイプラインが実行され
- 新しい属性がEnriched Datasetに追加され
- これらの新属性はフィルターや計算機で利用可能になり
- 各エンリッチメントで分析がより強力に
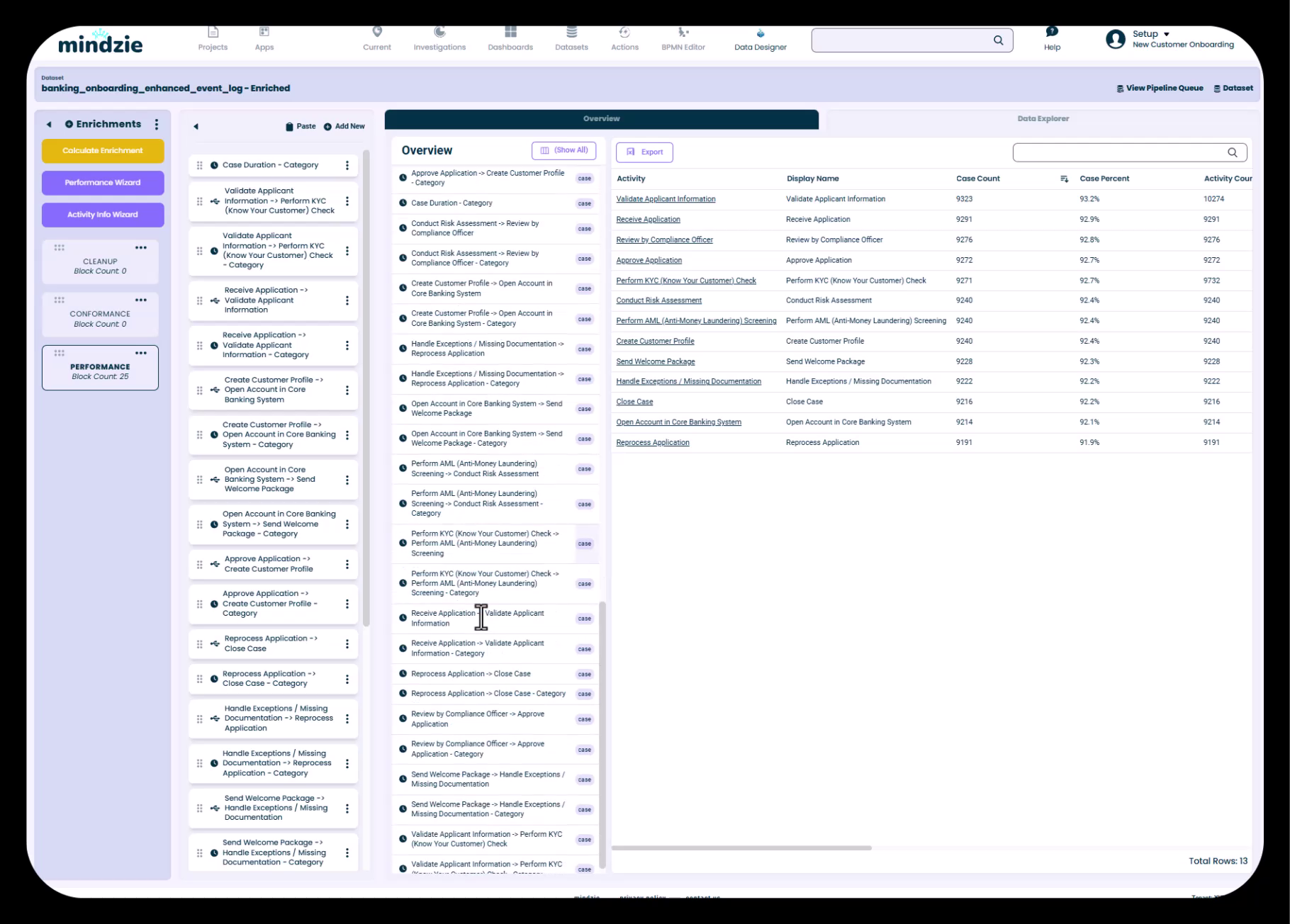 元の属性とシステム生成の強化属性(アイコン付き)を示すデータ概要
元の属性とシステム生成の強化属性(アイコン付き)を示すデータ概要
mindzieによって自動追加される属性
手動のエンリッチメントがなくても、mindzie StudioはEnriched Datasetに以下のような有用な属性を自動追加します:
- 時間帯 - アクティビティが発生した時間帯
- ケース開始 - 各ケースの開始時刻
- ケース終了 - 各ケースの終了時刻
- ケース期間 - 開始から終了までの総期間
- 最初のリソース - ケースを開始した担当者
- アクティビティ頻度 - アクティビティの出現頻度
- その他多数
これらの自動エンリッチメントにより、設定不要で即座に分析能力が得られます。
分析に適したデータセットの選択
mindzie Studioで調査や分析ノートブックを作成するとき、どのデータセットを分析するか選択する必要があります。
推奨: 調査および分析作業には常にEnriched Datasetを選択してください。このデータセットには、分析を強力かつ洞察に富んだものにする拡張属性と計算済み指標がすべて含まれています。
Original Datasetは主に以下の用途で使用してください:
- 参照および検証
- データ品質監査
- ソースデータ構造の理解
継続的な強化サイクル
デュアルデータセットアーキテクチャは、反復的なワークフローをサポートします:
- アップロード - データをインポートしOriginal Datasetを作成
- エンリッチ - パフォーマンス指標、適合ルール、カスタム属性を追加
- 計算 - パイプラインを実行しEnriched Datasetを更新
- 分析 - 拡張属性を使い調査と分析を作成
- 繰り返し - より深い洞察のためにエンリッチメントを追加
サイクルを繰り返すことでEnriched Datasetの価値が高まり、分析がより高度になります。
まとめ
- 2つのデータセットが作成される :Original(生データ)とEnriched(拡張データ)
- 自動作成 :データアップロード時にEnriched Datasetが自動作成される
- Enriched Datasetを使う :すべての分析や調査の主要データセットとして利用
- パイプライン実行 :OriginalをEnrichedに変換
- 継続的な強化 :エンリッチメント計算ごとに新属性がEnriched Datasetに追加
- デフォルト分析 :mindzie Studioが便利なスターター分析を自動提供
- 反復プロセス :分析を強化するためにエンリッチメントを継続的に追加可能