フィルターと計算機を使った分析の作成
概要
mindzie studioは、分析、フィルター、計算機という基本的なパラダイムを通じて、プロセス分析を構築する強力なローコード/ノーコードアプローチを提供します。本チュートリアルでは、複雑なコーディングや手動での計算を排除し、mindzieの豊富なプリビルトフィルターと計算機ライブラリを利用して、有意義なメトリクスとインサイトを作成する方法を案内します。
フィルターで特定のデータセグメントを抽出し、計算機でインサイトを可視化することで、パフォーマンス、効率、コンプライアンスに関する重要なビジネス課題に答える高度なプロセスメトリクスを迅速に構築できます。
前提条件
フィルターと計算機を用いた分析を作成する前に、以下を準備してください:
- データがロードされたアクティブなmindzie studioプロジェクト
- 強化属性作成のためのログエンリッチメントを完了していること(「Mastering the Log Enrichment Engine」参照)
- 調査および分析ノートブックを作成済みであること(「Working with Investigations and Analysis Notebooks」参照)
- データセットの属性と構造についての理解
分析-フィルター-計算機パラダイムの理解
mindzie studioは、分析作業を三つの基本要素で構成しています:
分析(ワークスペース)
分析ノートブックはJupyterノートブックに似ており、ワークブックやワークシートとして機能し、メトリクスの発見と作成の場を提供します。各分析はプロセスの特定の側面を探求する専用スペースを持ちます。
フィルター(データの分離)
フィルターは、特定のデータセグメントを抽出してターゲット分析を行うためのものです。問いは「どのデータで作業したいか?」です。例として以下があります:
- 部門、課、地域でフィルタリング
- 特定の期間のケースを抽出
- 特定の属性を持つケースの選択
- プロセスバリアントや結果によるデータの分離
計算機(視覚化とメトリクス)
計算機は「そのデータで何をしたいか?」という問いに答える視覚化ツールです。フィルターされたデータをチャート、統計、プロセスマップなどの視覚的表現に変換し、実用的なインサイトにします。
組み合わせの力
これらの要素を組み合わせることで本当の力が発揮されます。複数のフィルターと計算機を組み合わせて、コードを書くことなく複雑なビジネス課題に答える精緻な分析を作成可能です。
最初の分析の作成:平均プロセス期間
このウォークスルーでは、フィルターと計算機のアプローチを使って、顧客オンボーディングケースの平均期間というシンプルながら強力なメトリクスを作成する方法を示します。
ステップ1:分析ノートブックにアクセス
- 左サイドバーの調査へ移動
- 作業したい分析ノートブックをクリック
- 分析インターフェイスの「Notebook」タブを表示
上部に各種ブロック追加ボタンが並ぶメイン分析ワークスペースが表示されます。
ツールバーの内容:
- Add Filter - データフィルターブロックを追加
- Add Calculator - 視覚化・メトリクスブロックを追加
- Add Alert - 閾値ベースの自動アラートを作成
- Paste Block - 以前コピーした分析ブロックを貼り付け
- Expand/Collapse - コパイロットサイドバーの表示切替
ステップ2:フィルター利用のタイミングを理解する
この最初のメトリクスでは、フィルターなしで計算機に集中します。これにより、データセット内のすべてのケースの総体的な平均が得られます。
フィルターは次のような場合に重要になります:
- 異なる部門や地域間のパフォーマンス比較(例:米国対ヨーロッパ)
- 特定期間の分析(例:第1四半期対第2四半期)
- 問題のあるケースの抽出(例:コンプライアンスルール違反のケースのみ)
- ケースやイベント属性によるセグメント化
利用可能なフィルターを閲覧するには、「Add Filter」ボタンをクリックしてください。
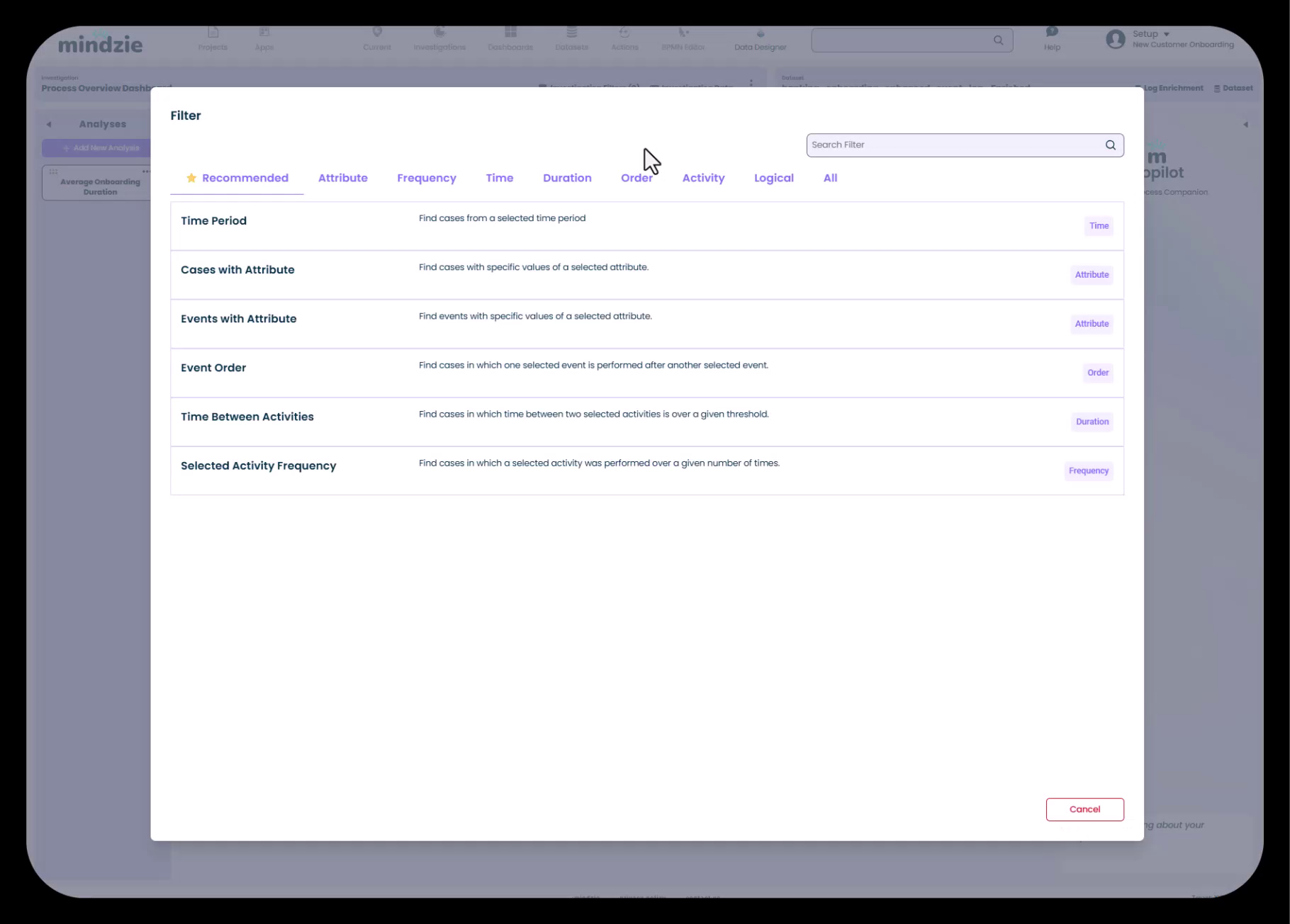
mindzieはカテゴリ別に整理された豊富なプリビルトフィルターライブラリを提供しています:
- Recommended - データに基づく一般的なフィルター
- Attribute - ケースやイベント属性値でフィルタリング
- Frequency - 活動の出現数でフィルター
- Time - 期間や日付範囲でフィルター
- Duration - プロセスまたは活動の期間でフィルター
- Order - 活動の順序でフィルター
- Activity - 特定活動でフィルター
- Logical - AND/ORロジックでフィルターを結合
各フィルターには用途を説明する説明文が付いているため、目的の分析に適したツールを簡単に見つけられます。
ステップ3:計算機の追加
「Add Calculator」ボタンをクリックして計算機ライブラリを開きます。
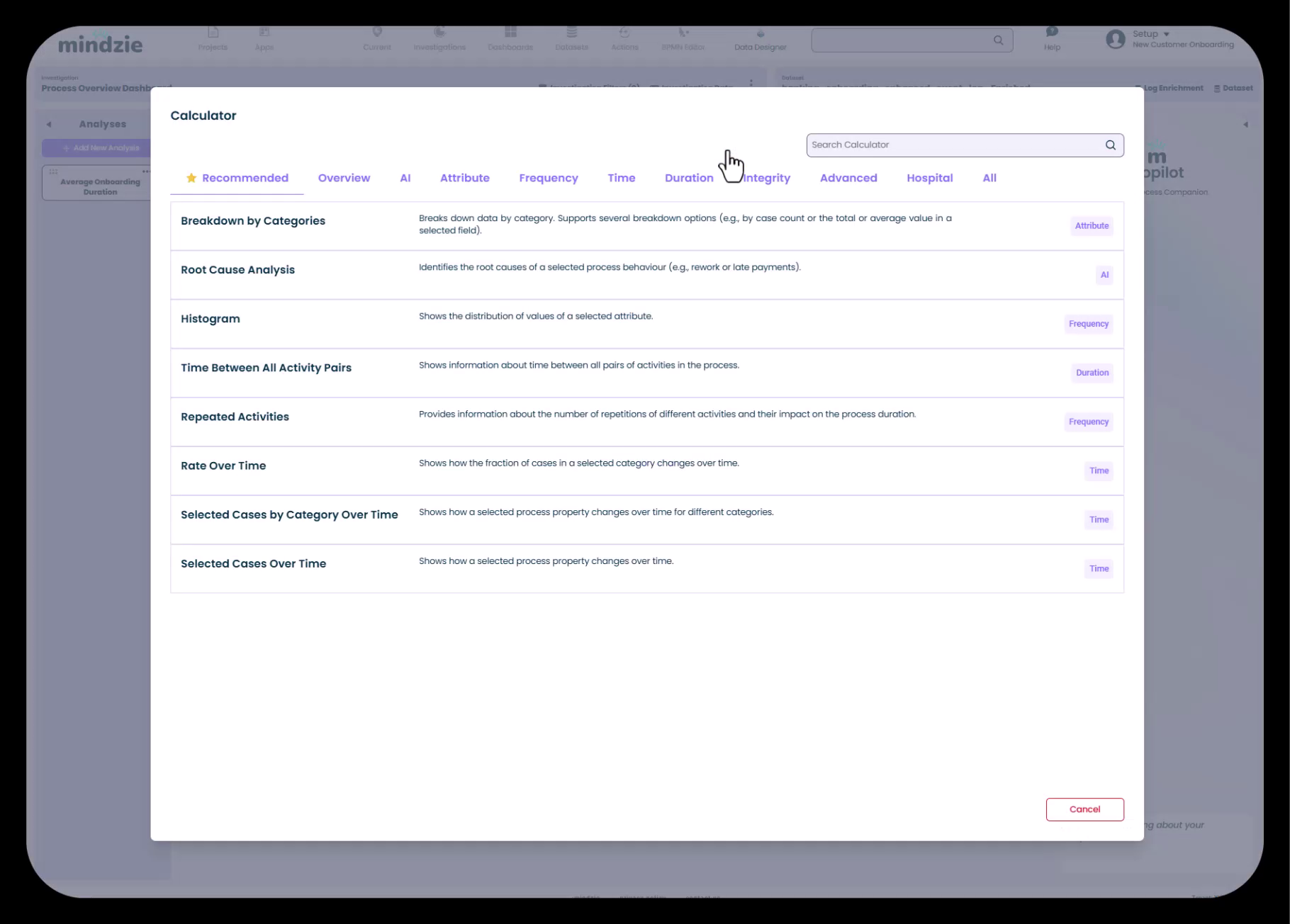
計算機ライブラリは以下のカテゴリに分かれています:
- Recommended - 現在のコンテキストに適した計算機
- Overview - サマリ統計とKPI
- AI - 機械学習ベースのインサイト
- Attribute - 属性に基づく分析と分布
- Frequency - 活動頻度分析
- Time - 時系列トレンドとパターン
- Duration - 期間メトリクスと分布
- Integrity - データ品質と整合性メトリクス
- Advanced - 複雑な分析向けの専門計算機
- Hospital - 医療専用メトリクス(該当する場合)
ステップ4:平均計算機を検索
計算機ライブラリ上部の検索ボックスを使い、目的の計算機を素早く見つけます。
- 検索ボックスに「average」と入力
- 絞り込み結果から「Average Value」を選択
この検索機能は、mindzieの40以上の計算機ライブラリで効率的に作業するのに役立ちます。計算機名、カテゴリ、機能で検索可能です。
ステップ5:計算機の属性を設定
「Average Value」計算機を選んだ後、平均値を算出する属性を指定します。
- 計算機設定の「Attribute Name」ドロップダウンをクリック
- 属性リストで「duration」を検索
- 「Case Duration」を選択
Case Durationが利用可能な理由:
Case Duration属性は、以前にmindzie Log Enrichment Engineでデータを処理したため存在します。Performance Wizardや他のエンリッチメントブロックが、ケース開始イベントと完了イベントのタイムスタンプ差分からこの属性を算出しました。
これはログエンリッチメントと分析の重要な関係を示しています:エンリッチメントが計算機を支える属性を生成します。
ステップ6:結果の確認
Case Duration属性を選択し計算機を追加すると、mindzieが即座に計算して結果を表示します。
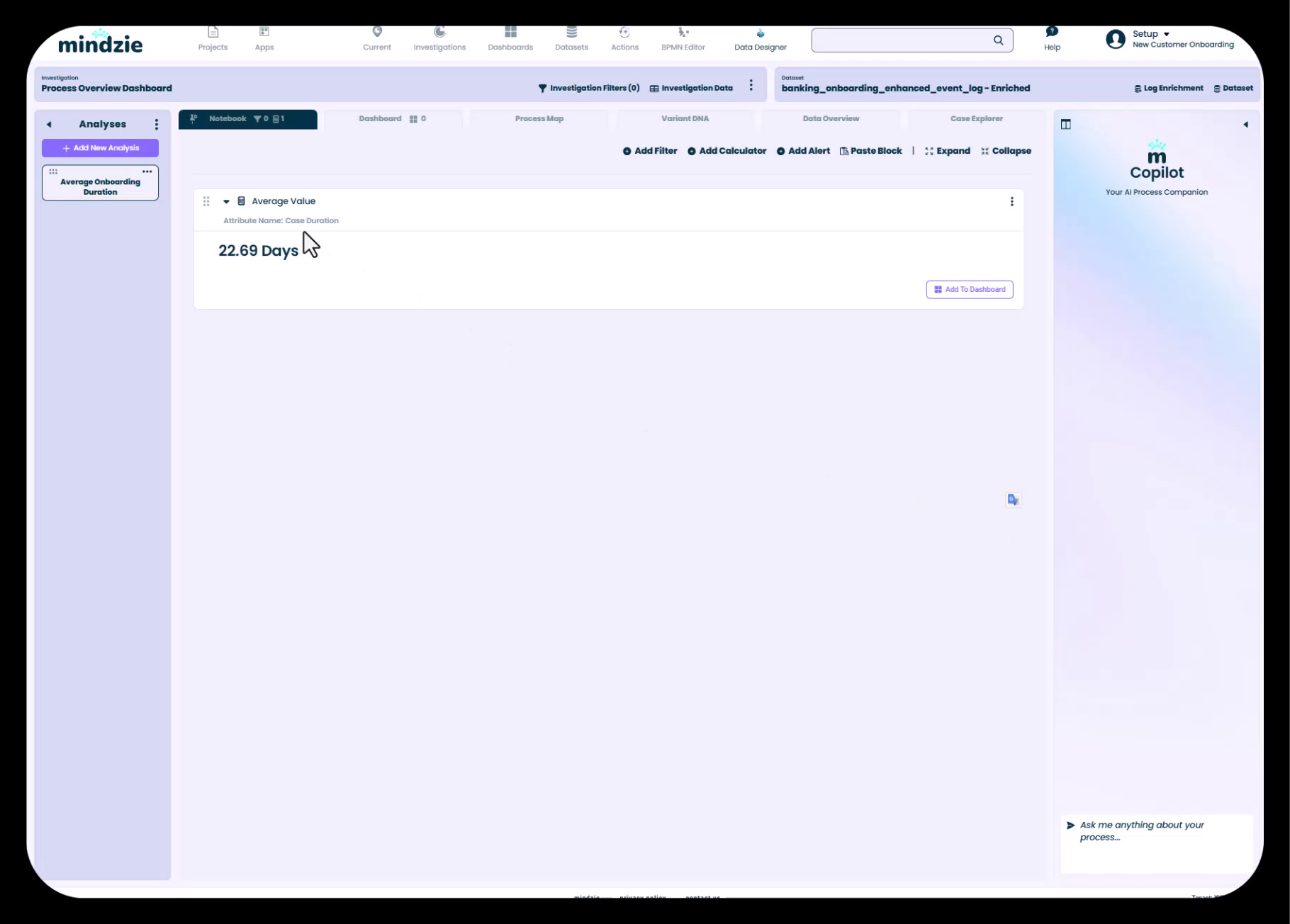
結果ブロックは以下を示します:
- 計算機タイプ - 「Average Value」ヘッダー
- 属性名 - 「Case Duration」(平均対象の属性)
- 計算済みメトリクス - 「22.69 Days」(全ケースの平均期間)
- 操作ボタン - ダッシュボード追加、設定、削除オプション
このメトリクスが、プロセスの主要パフォーマンス指標(KPI)となります:顧客オンボーディングに平均22.69日かかっていることを示します。
より複雑な分析の構築
複数フィルターの組み合わせ
セグメント分析を作成するには、同じ分析ブロックに複数のフィルターを追加可能です:
- 「Add Filter」で最初のフィルターを追加(例:Division = 「North America」)
- もう一度「Add Filter」で追加フィルターを追加(例:Year = 「2024」)
- 計算機を追加(例:Case DurationのAverage Value)
フィルターは通常ANDロジックで連携し、分析対象を正確に絞り込みます。
複数計算機の追加
同じフィルターデータに対して複数の計算機を追加し、異なる視点を一度に表示可能です:
- データセグメント定義のためにフィルターを追加
- 複数の計算機を追加(例:Average Value、分布チャート、時間トレンド)
- 各計算機は同じフィルター済みデータで動作し、補完的なインサイトを提供
比較分析の作成
セグメント間のパフォーマンス比較には:
- セグメントごとに別々の分析ブロックを作成
- 各ブロックでフィルターによりセグメントを分離(例:米国地域用ブロック、欧州地域用ブロック)
- 各ブロックで同じ計算機設定を使用
- 結果を並べて比較、または同一ダッシュボードに公開
計算機の高度な設定
多くの計算機は属性選択以外に追加設定が可能です:
- 集約方法 - 平均、中央値、合計、最小、最大の選択
- グルーピング - 別属性で結果をグループ化(例:部署別の平均期間表示)
- 時間バケット - 日、週、月、年ごとの傾向表示
- ビジュアルスタイリング - 色、ラベル、表示フォーマットのカスタマイズ
- 閾値設定 - パフォーマンス目標や警告レベルの設定
計算機ブロックの3点メニューをクリックして各計算機の設定パネルを確認してください。
強化属性の活用
フィルターと計算機の力は、有意義な分析属性の有無に大きく依存します。強力な分析を可能にする一般的な強化属性は以下です:
パフォーマンス属性(Performance Wizard由来):
- Case Duration
- Activity Duration
- Time Between Activities
- Performance Buckets(Fast、Normal、Slow)
コンフォーマンス属性(Conformance Rules由来):
- Conformance Status(適合/非適合)
- ルール違反回数
- 深刻度レベル
コスト属性(Activity Info Wizard由来):
- ケース合計コスト
- 活動コスト
- リソースコスト
AI予測(AI強化由来):
- 予測完了時間
- リスクスコア
- 推奨アクション
エンリッチメントされていない場合は、元のデータ属性(Case ID, Activity Name, Timestamp, Resource)のみを分析できます。エンリッチメントでmindzie studioの分析力が最大化します。
ベストプラクティス
シンプルに始めてから洗練させる
最初は全体平均や件数など基本的なメトリクスから始め、複雑なフィルター追加は後回しにします。これにより、
- ベースラインパフォーマンスの理解
- データロードの正確さ確認
- インターフェイスへの慣れを得てから、複雑シナリオに挑戦
分析名は説明的に
分析ノートブック作成時は、調査内容を明確に示す名称を付けます:
- 「Average Onboarding Duration」(明確)
- 「Analysis 1」(不明瞭)
フィルターは論理的に整理
複数フィルター使用時は以下順序で整理すると良いです:
- 時間ベース(年、四半期、月)
- 構造ベース(部門、課、地域)
- 結果ベース(適合状況、パフォーマンスバケット)
成功パターンの再利用
有効な分析を作成後は、
- 分析ブロック全体をコピーしフィルターを修正
- 同一プロジェクト内の他調査へコピー
- 他プロジェクトへコピー(「Reusing Analysis: Copying and Adapting Notebooks」参照)
分析内容のドキュメント化
分析ノートブックのノート機能で以下を記録:
- 分析が答える質問内容
- 使用フィルターと計算機の理由と設定
- 仮定やデータの制限事項
- 結果の解釈方法
よくあるユースケース
パフォーマンスベンチマーク
目的: 地域間で平均プロセス期間を比較する
- 地域ごとに分析ブロックを作成
- 地域別「Cases with Attribute」フィルターを追加(例:Region = 「North America」)
- Case Duration属性のAverage Value計算機を追加
- すべてのメトリクスを同一ダッシュボードに公開し並列比較
トレンド分析
目的: パフォーマンスの時間的変化を追跡
- 対象期間を選ぶTime Periodフィルターを追加
- Case Durationの推移を示すTrend計算機を設定・追加
- 時間バケットを月や四半期に設定
- 季節パターンや改善傾向を探る
根本原因の調査
目的: なぜ一部のケースが長期化するのか理解する
- 「Slow」ケースを抽出するPerformance Bucketフィルターを追加
- 複数の計算機で異なる観点を調査:
- Variant DNAで遅延のあるプロセス経路を分析
- Attribute Distributionで遅延部署を特定
- Root Cause Analysisで統計的に有意な要因を検出
コンプライアンス監視
目的: ルール違反の計測
- 「Non-Compliant」ケースを抽出するConformance Statusフィルターを追加
- 問題を数値化する計算機を追加:
- 非適合ケース数
- 総ケースに対する割合
- 違反タイプ別内訳
- 時系列推移
トラブルシューティング
計算機が「No Data」を表示する
原因:
- フィルターが厳しすぎてすべてのケースが除外されている
- 選択した属性がデータセットに存在しない
- データロードが完了していない
対策:
- フィルターを一つずつ外してどれが過剰か確認
- Data Overviewタブで属性の存在を確認
- エンリッチメントが正しく計算されたかチェック
属性がドロップダウンにない
原因:
- エンリッチメントが未計算
- 設定エラーでエンリッチメントが失敗
- 元データセットを使用している(強化済みデータセットではない)
対策:
- Log Enrichmentに移動してエンリッチメントを計算
- 設定エラーをチェック
- 調査で強化済みデータセットを利用しているか確認
計算機の結果がおかしい
原因:
- フィルターが意図通りでない
- 属性選択ミス
- 元データの品質問題
対策:
- フィルター設定を再確認
- 属性選択が意図に合致しているかチェック
- Data Overviewで手動確認
- Case Explorerで個別ケースを調査
まとめ
分析-フィルター-計算機パラダイムは、mindzie studioのすべての作業の基盤です。これらの構成要素をマスターすることで:
- コーディングなしで高度なメトリクスを作成
- 視覚解析を通じて複雑なビジネス課題に答える
- 調査を迅速に反復し洗練
- プロジェクト間で再利用可能な分析パターンを構築
忘れないでください:フィルターは「どのデータを分析するか」、計算機は「そのデータから何を知りたいか」を定義します。この二つのシンプルな概念の組み合わせが無限の分析可能性を生み出します。