合成データの生成
合成データの生成機能は、元のデータの統計的特性を保ちながら、元データの実際の値を含まない完全に新しい架空のデータセットを作成します。これは以下の用途に役立ちます:
- デモ - プロセスマイニングの機能を示すためのリアルな見た目のデータ作成
- テスト - 既知の特性を持つテストデータセットの生成
- 共有 - 機密情報を公開せずにデータパターンを外部に共有
- トレーニング - 機械学習モデルのトレーニング用データセット作成
重要: これは匿名化ではありません。合成データは完全に架空のもので、出力には元のデータ値は一切存在しません。合成データセットは外部に安全に共有できます。
アクセス方法
- Datasets ページに移動します
- 任意のデータセットの 三点リーダーメニュー をクリックします
- Generate Synthetic Data を選択します
設定オプション
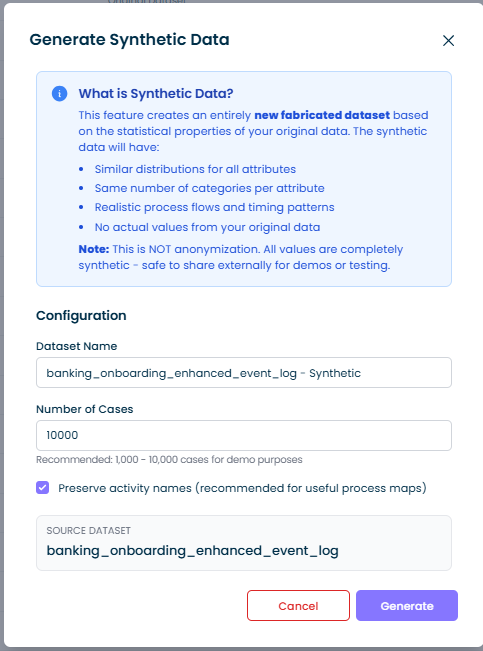
データセット名
合成データセットの名前です。デフォルトでは元データセット名に「 - Synthetic」が付加されます。
ケース数
合成データセットに生成するケース数を指定します:
- 最小: 100 ケース
- 最大: 100,000 ケース
- 推奨: デモ用途は1,000~10,000ケース
大きなデータセットは生成に時間がかかり、ダウンロードファイルも大きくなります。
アクティビティ名の保持
有効にすると(推奨)、合成データセットは「Submit Order」「Review Application」など元のアクティビティ名を保持します。これにより実際のプロセスフローを反映した有用なプロセスマップが作成されます。
無効にするとアクティビティ名は「Activity_1」「Activity_2」などの一般的なラベルに置き換えられます。アクティビティ名自体に機密情報が含まれる場合はこちらを使用してください。
生成される内容
合成データ生成器は元データセットを分析し、以下のように新しいデータを作成します:
| 要素 | 生成方法 |
|---|---|
| ケースID | 新しい連番ID: Case_1, Case_2 など |
| アクティビティ名 | 元データから保持(無効時は匿名化) |
| タイムスタンプ | アクティビティ間の期間パターンを保ったリアルな日付 |
| テキスト属性 | 分布を保ちつつ Customer_1, Region_2 などの一般的値に置換(例: 60%が「高優先度」なら約60%の合成ケースにPriority_1) |
| 数値属性 | 平均、分散、最小/最大など類似した統計特性で生成 |
| プロセスフロー | 実際のプロセス変種からサンプリングしたアクティビティ順序 |
含まれないもの
計算済み列はmindzieStudioにインポート時に再計算されるため合成出力には含まれません。
出力
GenerateをクリックするとmindzieStudioは以下を実行します:
- 元データの統計パターンを分析
- 指定された数の合成ケースを生成
- 結果をCSVファイルとして自動的にダウンロード
ダウンロードファイル名はデータセット名に .csv 拡張子が付いたものになります。
例
元データ:
CaseId,Activity,Timestamp,Customer,Amount
C001,Submit,2024-01-01 09:00,Acme Corp,1500.00
C001,Review,2024-01-01 11:00,Acme Corp,1500.00
C002,Submit,2024-01-02 10:00,Beta Inc,2300.00
合成出力(アクティビティ名保持有効時):
CaseId,Activity,Timestamp,Customer,Amount
Case_1,Submit,2020-03-15 14:23,Customer_1,1842.37
Case_1,Review,2020-03-15 16:45,Customer_1,1842.37
Case_2,Submit,2020-07-22 09:12,Customer_2,1523.89
ご注意:
- アクティビティ名は保持されています
- 顧客名は
Customer_1,Customer_2のような一般的名称に置換 - 金額は範囲が似ていますが架空の数字
- タイムスタンプはリアルですが完全に新しい日時です
利用ケース
デモ用データセットの作成
実運用のプロセスから合成データを生成し、実際のビジネスデータを公開せずにリアルなプロセスパターンを示す安全なデモデータセットを作成します。
外部コンサルタントへの共有
外部のプロセスマイニングコンサルタントやベンダーと作業する際、機密情報を明かさずにプロセスの特性を保った合成データセットを共有します。
パフォーマンステスト
5万ケース以上の大規模合成データセットを生成し、ノートブックやダッシュボードが大容量データにどう対応するかをテストします。
トレーニング・教育用
リアルで安全なデータを使って、プロセスマイニングの概念を新メンバーに教育するための合成データセットを作成します。