AI Causal Analysis (Alpha)
AI Causal Analysis 計算機は、機械学習を用いてターゲット結果を最も強く左右するケース属性を発見します。単に相関を示すだけでなく、定義した結果にケースが該当するかどうかに統計的に最も大きな影響を与える特徴量を特定します。これにより「何が起きているのか」から「なぜ起きているのか」へと分析を進めることができます。
アルファ機能: この計算機はmindzieのアルファプログラムの一部です。テナントでPreReleaseを有効にする必要があります。詳細はアルファ機能をご覧ください。
概要
AI Causal Analysisは次のような質問に答えます:
- なぜ一部のケースは完了までに7日以上かかるのか?
- どの属性が請求書の支払い遅延を発生しやすくしているのか?
- SLAに違反するケースとそうでないケースを何が区別しているのか?
- どの施設、チーム、製品カテゴリーが特定の結果に最も影響を与えているのか?
結果(説明したいケース)を定義し、入力列のセットを計算機に指定すると、これらのケースが結果グループに該当する原因として最も影響力のある要因がランク付けされて返されます。
Root Cause Analysisとの比較
AI Causal Analysisは既存のRoot Cause Analysis計算機と目的を共有しますが、はるかに厳密なアプローチを採用しています:
| 機能 | Root Cause Analysis | AI Causal Analysis |
|---|---|---|
| 単一属性のドライバーを見つける | はい | はい |
| 複数属性の連言(ルールあたり最大3属性)を見つける | いいえ | はい |
| 相関と因果を区別する | いいえ | はい(因果グラフ + 傾向スコア調整) |
| 信頼区間を報告する | いいえ | はい(全ルールに95% Wilson CI) |
| 多重検定を制御する | いいえ | はい(Benjamini-Hochberg FDR) |
| 数値 / 日付 / 時刻属性を扱える | いいえ(文字列のみ) | はい(結果に基づくビン分割) |
| ドライバーごとの平易な英語のナラティブ | いいえ | はい |
単一属性の高速スキャンには Root Cause Analysis を、本格的な調査、特に結果に基づいて誰かが行動を起こす場合には AI Causal Analysis を使用してください。
計算機の追加方法
- mindzieStudioでノートブックを開く
- Add Calculator をクリックし、AI Causal Analysis (Alpha) を選択
- 結果と入力列を設定する(以下参照)
- Create をクリック
設定
Title
計算機の表示名。デフォルトは AI Causal Analysis (Alpha) です。回答したい質問に合わせて、たとえば Why are ICU stays long? や Drivers of Late Payment のように具体的な名前に変更してください。
Description
任意の自由記述メモ。分析した業務上の質問、分析を実行した日付範囲、依頼したステークホルダーなどを記録するのに便利です。
Outcome Definition
結果(outcome)は、説明したいケースのグループです。計算機はこれらのケースをデータセットの残りと比較し、どの入力列が2つのグループを最もよく分離するかを特定します。
結果を定義する3つのモードが利用できます:
Filter Mode
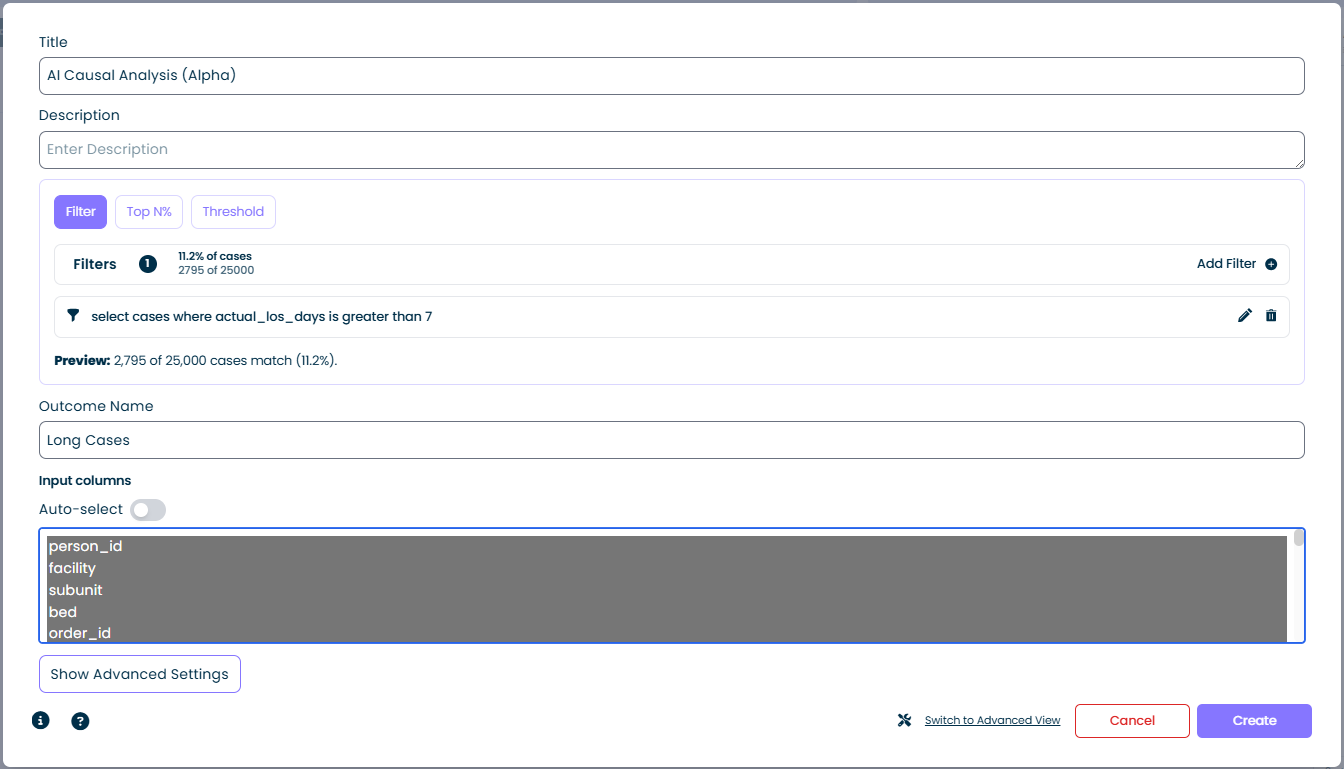
Filter タブを選択し、1つ以上のフィルター式を追加します。計算機はフィルターに一致するケースを「outcome」グループとして扱います。
- Cases matching: パーセンテージと実数で表示されます。例:
11.2% of cases / 2,795 of 25,000 - Add Filter: 標準のフィルタービルダーを開きます - 任意の数の条件を組み合わせ可能
- Preview: フィルターを構築すると同時にライブ更新されるため、計算機を実行する前に選択内容を検証できます
Filterモードは最も柔軟なオプションです。mindzieフィルターとして表現できる条件(期間のしきい値、属性の一致、アクティビティの有無など)はすべて結果として使えます。上記のスクリーンショットでは、フィルター select cases where actual_los_days is greater than 7 が「Long Cases」を結果として定義しています。
Top N% Mode
Top N% タブを選択し、数値属性の最上位(または最下位)の値を結果として使用します。これは「最悪のケース」や「トップパフォーマー」を、明確なしきい値を選ばずに説明したい場合に便利です。例:サイクルタイム上位10%のケース。
Threshold Mode
Threshold タブを選択し、属性の単一の数値しきい値で結果を定義します。値を上回る(または下回る)すべてのケースが結果グループの一部となります。例:invoice_amount が50,000を超えるケース。
Outcome Name
結果で結果グループを識別する短いラベル。例:Long Cases、Late Payments、SLA Breach。この名前は結果グループが参照される分析出力全体で表示されます。
Input Columns
結果のドライバーを探索する際に、モデルが使用を許可される列です。
- Column list: データセット内のすべてのケース属性が表示されます。1つ以上を選択して分析に含めます。選択された列はハイライトされます。
- Auto-select トグル: 有効にすると、mindzieがデータセットのスキーマに基づいて適切な入力列のデフォルトセットを自動的に選択します。手動で完全に制御したい場合、たとえば結果と自明に相関する列(答えを漏らすIDなど)を除外したい場合には、これを無効にしてください。
入力列を選ぶヒント:
- 結果の下流にある列は除外してください。
discharge_dateがactual_los_daysの計算に使われている場合、それは洞察を追加することなく結果を支配してしまいます。 - 高カーディナリティの識別子(
person_id、order_id)は、特にエンティティごとの効果を見たい場合を除き除外してください。 - コンテキスト属性(施設、製品カテゴリ、優先度、地域)を含めてください。興味深いドライバーは通常こういった属性にあります。
Show Advanced Settings
検索の追加チューニングオプションを開きます。デフォルトはほとんどの分析でうまく機能します。特定の理由がある場合にのみ上書きしてください。
| 設定 | デフォルト | 目的 |
|---|---|---|
| Beam width | 50 | 各探索深度で保持される候補ルールの数。大きいほど網羅的だが遅い。 |
| Max rule depth | 3 | 許可される最長のルール。3 は A AND B AND C のようなルールを意味する。 |
| Min cases per rule | 30 | これ未満のケースにしか影響しないルールは、実行可能と見なすには小さすぎるため破棄される。 |
| Min lift | 1.2 | ルール内結果率がベースラインを少なくともこの倍率で上回る必要がある(1.2 = ベースラインより少なくとも20%高い)。 |
| FDR alpha | 0.05 | ルール探索全体の誤発見を制御するBenjamini-Hochberg有意性しきい値。 |
| Max drivers returned | 20 | 全テーブルビューに表示されるルール数の上限。 |
| Redundancy Jaccard | 0.9 | ケースセットがこの割合を超えて重複するルールは重複として扱われフィルターされる。 |
| Sampling threshold | 2,000,000 cases | このサイズを超えるデータセットはFloydの組み合わせアルゴリズムを使って決定論的にサンプリングされる。出力は WasSampled = true と実際のサンプルサイズを報告する。 |
Switch to Advanced View
すべてのモデルパラメーターを細かく制御するために、エディタを高度モードに切り替えます。ここで示されているガイド付きビューは、大多数のユースケースで十分です。
一般的なワークフロー
- 質問を定式化する - 説明したい結果を決定します。「何がケースを遅くするのか?」は
case_duration > 7 daysというFilter結果になります。 - 結果を定義する - Filter、Top N%、またはThresholdモードを使用します。Preview のパーセンテージが妥当であることを確認してください(ケースが少なすぎると結果が不安定になり、多すぎると結果が本当に区別的なものではなくなります)。
- 結果に名前を付ける - 結果やレポートで読みやすい簡潔なラベルを選びます。
- 入力列を選択する - Auto-selectから始め、答えを漏らす列やノイズを追加する列を除外していきます。
- Create - 計算機を実行します。結果は、結果のドライバーをランク付けして提示します。
- 解釈する - 上位ドライバーを確認し、必要に応じて結果や入力セットを調整して再実行します。
例
病院の運営チームが、一部の入院患者の滞在が7日を超える理由を理解したいとします。
| 設定 | 値 |
|---|---|
| Title | AI Causal Analysis (Alpha) |
| Filter mode | select cases where actual_los_days is greater than 7 |
| Preview | 25,000件のうち2,795件が一致(11.2%) |
| Outcome Name | Long Cases |
| Input columns | facility, subunit, bed, order_id, ...(自動選択) |
実行後、計算機は施設、サブユニット、ケア属性のどの組み合わせが長期滞在ケースと通常滞在ケースを最も強く区別するかを報告します。これにより、チームはあらゆる属性を手動で探索するのではなく、調査すべき特定のユニットとワークフローに焦点を当てることができます。
結果の解釈
各上位ドライバーについて、計算機は平易な英語のナラティブ段落と、所見の強さを示すエビデンスバッジを生成します:
| バッジ | 意味 | 行動の方法 |
|---|---|---|
| Causal | 因果グラフシグナルと交絡調整後の効果の両方が正である。 | 最も強力な実行可能なエビデンス - 介入の優先順位を付けるのに安全。 |
| Likely Causal | 因果グラフはルールと結果を結びつけているが、交絡因子を調整すると効果が弱まる。 | 有望 - 行動する前にさらに調査する。 |
| Associated | 調整後も効果は残るが、グラフ上でルールが結果への直接経路に位置していない。 | 実在する関連だが、おそらく間接的 - 真のドライバーの代理指標かもしれない。 |
| Correlational | 関連はあるが、因果関係を確認できない。 | 診断信号のみ - これだけを根拠に行動しないこと。 |
Causal ルールのナラティブ例:
Channel = Online is a likely driver of Non-First Contact Resolution. Cases matching this rule show a 46.1% outcome rate vs. the 29.0% baseline (1.59x, 95% CI 1.51x - 1.68x, p < 0.001). It covers 2,518 cases, accounting for 34.7% of all Non-First Contact Resolution occurrences. The effect survived adjustment for other top drivers and sits on a direct path to the outcome in the learned causal graph.
Full Table ビューでは、探索と有意性フィルターを生き残ったすべてのルールについて、カバレッジ、リフト、信頼区間、調整後効果、p値、バッジを含む完全なランキング一覧が追加されます。
アルゴリズムの仕組み
AI Causal Analysisは5段階のパイプラインを実行します。各段階には特定の役割があり、全体が100万ケースのデータセットでも数秒で完了するように設計されています。
1. 準備とビン分割
- 計算機は結果グループに含まれるケースに
1とラベル付けし、それ以外には0とラベル付けします。これが出力で表示される ベースラインレート です。 - カテゴリ 属性(文字列、ブール値、低カーディナリティ整数)はそのまま使用されます。各個別の値が候補 リテラル となります(例:
facility = Memorial)。 - 数値および日付/時刻 属性は MDL最適・結果認識型ビン分割器 でビン分割されます。等幅や等頻度のビンを選ぶのではなく、ビン分割器は結果と非結果のケースを最もよく分離するカット点を選び、Minimum Description Length原理を用いてビンの数を自動的に選択します。これにより、
actual_los_daysのような数値列が意味のある少数のバケット(例:<= 3 days、4 - 7 days、> 7 days)に変換されます。
2. ビットマップインデックス
すべてのリテラルは bitset として保存されます - ケース1件につき1ビット、リテラルにマッチする場合は 1。AND でリテラルを組み合わせると、高速なビット単位の共通集合になります:
facility = Memorial AND priority = Highはbitset_A & bitset_Bとして計算されます。- 候補ルールのカバレッジ、結果カウント、リフトは、ルールの深さに関係なくマイクロ秒単位で評価できます。
Min cases per rule 未満のケースしかカバーしないリテラルは、検索開始前にドロップされます。
3. ビームサーチによるサブグループ発見
計算機はルール空間を幅優先で探索します:
- Depth 1: 各単一リテラルを評価します。品質指標(リフトとWeighted Relative Accuracy)を使ってスコアを付け、上位
Beam width個(デフォルト50)を保持します。 - Depth 2: 保持された各ルールを、互換性のある他の各リテラルで拡張し、
A AND Bのような連言を形成します。すべてをスコアリングし、再び上位Beam width個を保持します。 - Depth 3: もう一度繰り返します。
Max rule depthで停止します。
各レベルで Min lift または Min cases per rule を下回るルールは剪定されます。
検索後、Jaccard冗長性フィルター が近似重複のルールを削除します:2つのルールが本質的に同じケースをカバーしている場合(重複が Redundancy Jaccard デフォルト0.9を超える場合)、より良い方だけが保持されます。
4. 統計的有意性
生き残った各ルールについて、計算機は以下を計算します:
- リスク比(ルール内結果率をベースラインレートで割ったもの)とその 95% Wilson信頼区間。これは、正規近似が失敗する小さな確率や極端な確率でも良好に振る舞います。
- ルールに効果がないという帰無仮説下での p値。
- すべてのテストされたルールにまたがる Benjamini-Hochberg FDR補正。
FDR alpha(デフォルト0.05)が期待される誤発見率を設定します。FDRを生き残らなかったルールは報告されず、これが検索結果を偽の発見で溺れさせるのを防ぎます。
5. 因果判定
有意性だけでは関連があることしか示せません。2つの追加シグナルが、ルールが Causal バッジを受けるかを決定します:
- 因果グラフシグナル - 属性と結果から学習される軽量のベイズ構造スコア。このルールは学習されたグラフで結果への直接経路にあるのか、それとも交絡因子を介した間接経路にしかないのかを問います。
- 傾向スコア調整 - リッジ正則化ロジスティック回帰が、他の上位ドライバーすべてを条件として、各ケースがルールにマッチする確率をモデル化します。その傾向で重み付けした後、ルールの効果が再推定されます。効果がゼロに縮小すれば、ルールは他のドライバーの代理に過ぎませんでした。残存すれば、独立した説明力を持ちます。
判定器は両方のシグナルを上記の4つのエビデンスバッジにまとめます。
6. ナラティブ生成
最後のステップはカードビューに表示される平易な英語の段落を構成します。ルール定義、ルール内およびベースライン結果率、リスク比と信頼区間、p値、カバレッジ、エビデンスバッジを、統計に詳しくない読者に自然に読める文章構造に織り込みます。
パフォーマンス
開発マシンで測定:
| データセット | 時間 |
|---|---|
| 100,000ケース × 4列 | 1秒未満 |
| 200,000ケース × 20列 | 2秒未満 |
| 1,000,000ケース × 50列 | 約3秒 |
サンプリングしきい値(デフォルト2,000,000ケース)を超えるデータセットは、Floydの組み合わせアルゴリズムを用いて決定論的にサンプリングされます。これが発生すると、出力は WasSampled = true をフラグ付けし、実際のサンプルサイズを報告するため、結果は再現可能でサンプリングは可視化されます。
既知の制限(v1)
- 二値結果のみ対応。 多クラスの結果(例:fast / medium / slow)は本リリースではサポートされていません。2方向の分割を別々の分析として定義してください。
- ケース単位の説明はまだありません。 v1は「データセット全体で何がこの結果を駆動しているか?」に答えます。将来のリリースでは「なぜこの特定のケースがうまくいかなかったのか?」というパネルが追加される予定です。
- 時間的ドリフト分析はありません。 四半期ごとにドライバーが変わる場合、v1ではそれを時間で分割しません。それが重要な場合は、各時間スライスで計算機を別々に実行してください。
- 数値のビン分割は結果認識型です。 固定の、人が選んだビンが必要な場合は、計算機を実行する前にenrichmentで列を事前にバケット化してください。
利用例
パフォーマンスドライバー
SLAに違反するケース、予算を超えるケース、期待される期間を超えるケースに最も関連する属性を特定します。期間やKPIの enrichment上に構築されたFilter結果とよく機能します。
結果分析
成功したケースと失敗またはキャンセルされたケースを比較します。ステータスまたは結果属性でFilter結果を使用し、どの上流属性が各結果を予測するかを確認します。
リスクとコンプライアンス
適合性または制御の enrichmentによってフラグ付けされたケースに計算機を向け、どのコンテキスト要因がコンプライアンス違反と相関しているかを学びます。
トップパフォーマー分析
Top N%モードを使用して、最高のケース、チーム、顧客が他とどう異なるかを説明します。得られた洞察をプロセス設計やトレーニングに反映してください。
ヒント
- シンプルに始める。2〜3の条件と自動選択の入力を使った適切に選ばれたFilterが、通常最も明確な結果を生み出します。
- プレビューのパーセンテージに注意する。結果グループがデータセットの約2%未満または約50%超の場合、分析は解釈しにくくなります。結果グループが意味のある少数派になるまでフィルターを調整してください。
- 入力列を繰り返し調整する。洞察なく結果を支配する列(ID、結果を漏らすタイムスタンプ)を削除し、再実行してください。
- 結果に具体的な名前を付ける。ステークホルダーと結果を共有したりレポートに構成したりする場合、
Long CasesはOutcome 1より優れています。 - 同じ質問に対する別の視点として、Decision Tree計算機と組み合わせる。Decision Treeは分岐構造を示し、AI Causal Analysisは全体的な特徴の影響をランク付けします。
関連計算機
- Decision Tree - 属性がケースを結果グループにどのように分割するかを示す補完的なビュー
- Root Cause Analysis - KPI偏差のための決定論的な統計的根本原因発見
- Case Outcome By Category - 選択したカテゴリ属性にわたる結果率を比較
関連機能
- AI Studio (Alpha) - Feature ImpactとRoot Causeを含む、より広範な予測分析ワークスペース
- Alpha Features Overview - mindzieアルファプログラム内の機能の全リスト
フィードバックの提供
AI Causal Analysisはアルファ機能であり、あなたの意見はその進化を直接形作ります:
- メール: support@mindzie.com
- 件名:
Alpha Feedback: AI Causal Analysisを含めてください - 内容: 使用した結果定義、入力列、期待した結果、得られた結果