データアーキテクチャ
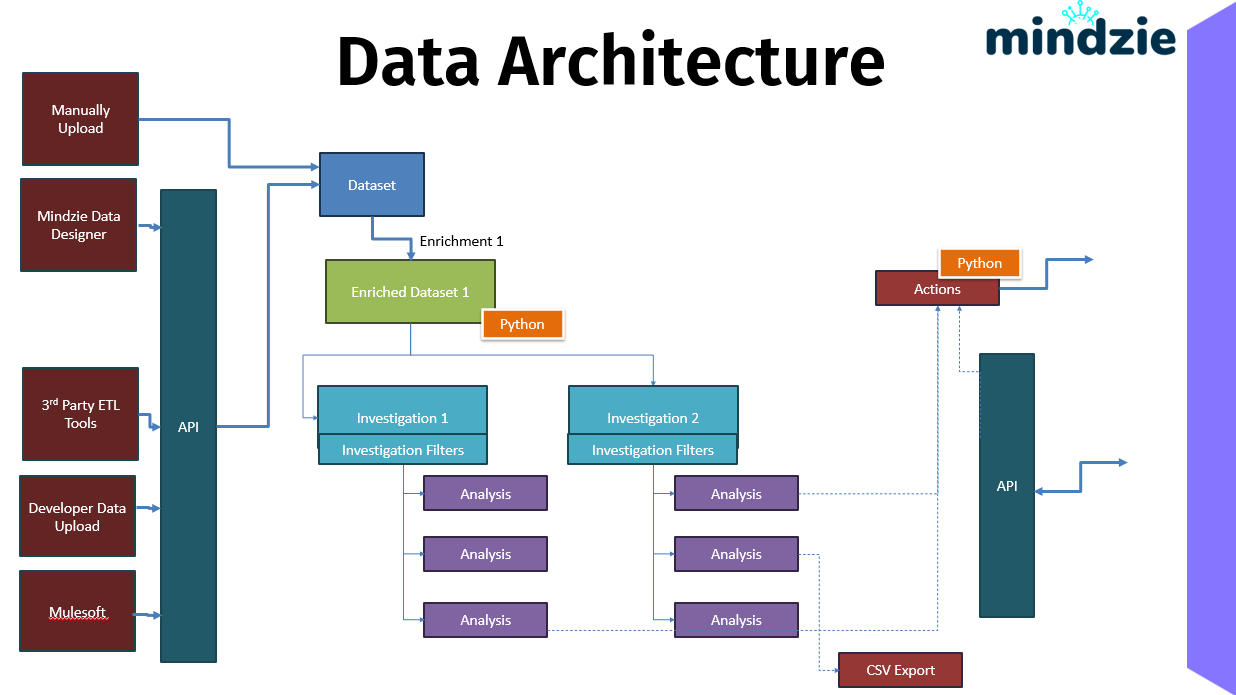
データアーキテクチャは、プロセスデータがどのようにmindzieStudioに流入し、エンリッチメントを通じて変換され、エクスポートや自動アクションのトリガーに使用されるかを示しています。これらのデータ経路を理解することで、効果的なデータ統合戦略を設計することができます。
概要
mindzieStudioは複数のデータ入力方法、中央集約されたAPI層、そしてさまざまな出力オプションをサポートしています。この柔軟なアーキテクチャにより、プロセスマイニングを既存のデータエコシステムに統合することが可能です。
データ入力ソース
mindzieStudioにプロセスデータを取り込む方法はいくつかあります:
手動アップロード
最も簡単な方法はmindzieStudioのインターフェースから直接ファイルをアップロードすることです。対応フォーマットは以下の通りです:
- CSVファイル:標準的なカンマ区切り形式
- Excelファイル:.xlsxスプレッドシート
- Parquetファイル:大規模データセット向けのカラムナーストレージ形式
- ZIPアーカイブ:複数ファイルを含む圧縮パッケージ
手動アップロードはアドホック分析、概念実証プロジェクト、またはデータが既にソースシステムからエクスポートされている場合に最適です。
mindzie Data Designer
mindzie Data Designerは、ソースデータベースやシステムに直接接続するビジュアルツールです。以下が可能です:
- データスキーマの視覚的定義
- ソースカラムをイベントログ形式にマッピング
- 自動データ更新のスケジュール設定
- 抽出時のデータ変換
Data DesignerはSQL Server、Oracle、PostgreSQL、MySQL、SAP HANAなど主要なデータベースへの接続をサポートしています。
サードパーティETLツール
組織に既にETL(抽出、変換、ロード)インフラがある場合、標準的なデータパイプラインを通じてmindzieStudioと統合できます。この方法は既存のデータエンジニアリング能力およびガバナンスプロセスを活用します。
開発者向けデータアップロード
プログラム的なアクセスの場合、mindzieStudio APIを使用して以下が可能です:
- HTTPエンドポイント経由でのデータセットアップロード
- カスタムアプリケーションからのデータ更新の自動化
- CI/CDパイプラインとの統合
- カスタムデータコネクタの構築
これは、自動化されたデータパイプラインを構築したり、プロセスマイニングを大規模システムに統合したりする組織に理想的です。
Mulesoft統合
Mulesoftを使った統合を行うエンタープライズ組織は、mindzieStudioを統合フロー内のAPIエンドポイントとして接続できます。これにより、プロセスデータが企業全体の統合戦略の一部として流れます。
API
APIはmindzieStudioにおけるすべてのデータ移動の中央ゲートウェイとして機能します。手動または自動でアップロードされたすべてのデータはAPI層を通過します。
APIは以下を提供します:
- 認証:ベアラートークンによる安全なアクセス
- 検証:データ形式およびスキーマの検証
- ルーティング:適切な処理コンポーネントへのデータ振り分け
- アクセス制御:テナントおよびプロジェクト単位の権限管理
APIはmindzieStudioのEnterprise ServerおよびSaaSエディションで利用可能です。
データセット
データがmindzieStudioに取り込まれると、Datasetとして格納されます。データセットは:
- 圧縮:効率的なバイナリストレージ形式
- 検証済み:必要なカラムとデータ型がチェックされる
- バージョン管理:過去のアップロードも比較のため保持可能
すべてのデータセットには、以下の3つのコアイベントログカラムが必須です:
- ケースID(各プロセスインスタンスの識別子)
- アクティビティ(各ステップの名前)
- タイムスタンプ(各ステップが発生した日時)
追加の属性カラムには、ビジネスに関連する任意のデータを含められます。
Pythonによるエンリッチメント
エンリッチメント層は、生のデータセットを分析準備済みのデータに変換します。エンリッチメントには以下が含まれます:
- 組み込みの変換オペレーター
- 高度なロジックのためのカスタムPythonスクリプト
- ビジネスルール計算
- データ品質の修正
Python統合により次が可能です:
- カスタム変換ロジックの作成
- Pythonのデータサイエンスライブラリの活用
- 再利用可能な変換スクリプトの作成
- 複雑なデータ操作シナリオへの対応
エンリッチメントはバックグラウンドで実行され、分析中の高速アクセスのために結果をキャッシュします。
調査・分析
調査層は分析が行われる場所です。調査内で以下を実施します:
- 調査フィルターを適用して特定データサブセットに焦点をあてる
- 順序化されたブロックで構成される分析ノートブックを作成
- 計算器による洞察の生成
- ビジュアライゼーションの構築
分析結果はキャッシュされ、ソースデータ更新時にリフレッシュ可能です。
出力と統合
mindzieStudioはデータのエクスポートや外部システムとの統合を複数の方法で提供します:
アクション
アクションはスケジュールまたはトリガーに基づいて実行される自動化ワークフローです。アクションは:
- カスタム処理のためにPythonスクリプトを実行
- 外部HTTP APIを呼び出し
- 外部システムへのデータエクスポート
- 複数ステップの連鎖処理
- フォールバックアクションによるエラー処理
アクションは、プロセスの洞察から実際の業務反応をトリガーする運用上の統合を可能にします。
APIエクスポート
外部システムはAPIを通じてmindzieStudioに問い合わせることができ:
- 分析結果をプログラム的に取得
- ダッシュボードデータを他のアプリケーションに取り込み
- プロセス指標を報告システムに統合
- 外部ツールの運用ダッシュボードにデータ連携
CSVエクスポート
単純なデータエクスポートにはCSVファイルとして分析結果をダウンロードできます。用途としては:
- mindzieStudioを持たないステークホルダーとのデータ共有
- スプレッドシートツールへのデータ読み込み
- 分析結果のバックアップ作成
データフローのまとめ
mindzieStudio全体のデータフロー:
- 入力:Manual Upload、Data Designer、ETLツール、API、またはMulesoft経由でデータが取り込まれる
- ゲートウェイ:APIがデータの検証、認証、ルーティングを行う
- 格納:データは圧縮されたDatasetとして保存される
- 変換:エンリッチメント(Pythonオプション付き)でデータを準備
- 分析:調査とノートブックにより洞察を生成
- 出力:結果はアクション、API利用者、またはCSVエクスポートへ流れる
このアーキテクチャはインタラクティブな分析と自動化された運用ワークフローの双方をサポートし、mindzieStudioをアドホックな探索から本番環境でのプロセス監視まで適したものにしています。