Analyse de Conformité
Aperçu
L'analyse de conformité vous permet de définir à quoi votre processus devrait ressembler, puis de vérifier automatiquement dans quelle mesure vos cas réels suivent ce processus. Elle répond à la question : « Mes cas se déroulent-ils comme ils devraient ? »
Vous procédez en passant en revue vos variantes de processus, en acceptant celles qui sont correctes et en rejetant celles qui ne le sont pas. Pour les variantes rejetées, vous pouvez documenter pourquoi elles dévient du processus attendu – avec une assistance IA optionnelle pour aider à rédiger l'explication. mindzie construit ensuite un modèle de processus à partir de vos variantes acceptées et évalue chaque autre variante par rapport à ce modèle.
Le résultat est un processus documenté où :
- Les bonnes variantes définissent à quoi le processus DOIT ressembler (le modèle de référence)
- Les mauvaises variantes expliquent ce qui peut mal se passer et pourquoi (le catalogue des écarts)
- Tout le reste est automatiquement classifié par rapport au modèle
Pour commencer
- Naviguez vers Conformance dans le menu supérieur
- Sélectionnez un jeu de données dans le menu déroulant en haut à droite
- Triez vos variantes de haut en bas (les plus fréquentes en premier) :
- Cliquez sur la coche pour marquer une variante comme Bonne (un clic, sans complication)
- Cliquez sur le X pour marquer une variante comme Mauvaise – une ligne de note s'ouvre automatiquement
- Pour les mauvaises variantes, documentez l’écart : saisissez une raison ou cliquez sur le bouton étincelle pour que l’IA génère une explication
- Cliquez sur Build & Check Conformance pour construire un modèle de processus et lancer la vérification de conformité
- Examinez les résultats : chaque variante reçoit un score d’adéquation et est classée comme « Conform » ou « Non-conform »
- Ajustez éventuellement le curseur Threshold pour contrôler la rigueur de la vérification de conformité
- Cliquez sur Save Model pour enregistrer votre modèle de conformité et les notes d’écart en vue de leur utilisation dans les enrichissements
Comment ça marche
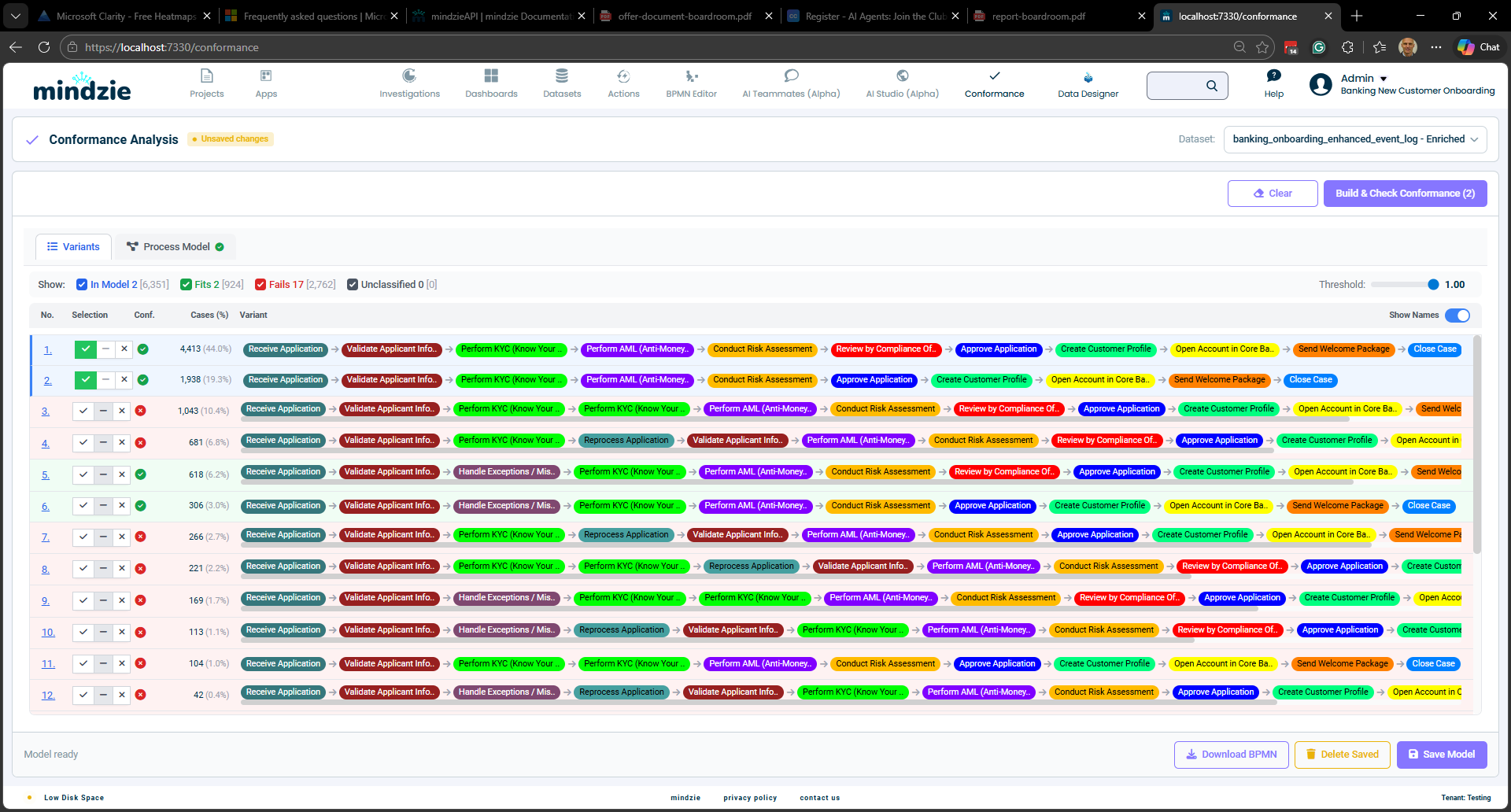
Étape 1 : Trier vos variantes
L’onglet Variants affiche toutes les variantes de processus dans votre jeu de données, triées par fréquence (les plus courantes en premier). Chaque ligne représente une séquence unique d’activités, avec des étiquettes colorées montrant le flux du processus.
Parcourez la liste de haut en bas. Pour chaque variante, cliquez sur l’un des trois boutons :
- Bonne (coche) – Cette variante représente une exécution correcte du processus. Un clic, aucune autre saisie requise.
- Mauvaise (X) – Cette variante est une anomalie connue. En cliquant sur X, une ligne de note apparaît automatiquement sous la variante où vous pouvez documenter la raison de l’écart.
- Non classée (tiret) – Laissez le système décider selon la conformité. C’est l’état par défaut.
Vous pouvez également modifier la classification d’une variante auto-classifiée en cliquant sur ses boutons de sélection.
Documentation des écarts
Lorsque vous marquez une variante comme Mauvaise, une ligne de note en ligne apparaît directement en dessous. Cette ligne contient :
- Une zone de texte où vous pouvez taper la raison pour laquelle cette variante dévie du processus attendu
- Un bouton étincelle (si l’IA est configurée pour votre locataire) qui génère automatiquement une description de l’écart
L’IA analyse vos variantes bonnes acceptées et les compare à la variante rejetée pour identifier ce qui diffère – activités manquantes, étapes en trop, ordre erroné ou activités répétées. La description générée est placée dans la zone de texte que vous pouvez accepter telle quelle ou modifier avant enregistrement.
Les notes sont optionnelles. Vous pouvez marquer une variante comme Mauvaise sans fournir de raison, mais documenter les écarts crée un catalogue précieux d’incidents connus du processus, utile pour les rapports, la formation et l’amélioration continue.
Pour réduire une ligne de note sans supprimer la note, cliquez sur la flèche de repli à droite de la ligne. Les variantes avec notes enregistrées affichent une petite icône de note même lorsqu’elles sont repliées.
Étape 2 : Construire le modèle de processus
Lorsque vous cliquez sur Build & Check Conformance, mindzie effectue deux opérations :
Découverte de processus – mindzie analyse les variantes bonnes sélectionnées et découvre un modèle de processus structuré capturant tous les chemins d'exécution valides. Le modèle identifie :
- La séquence des activités
- Les points de décision où le processus peut emprunter différents chemins (passerelles XOR)
- Les chemins parallèles où les activités peuvent se dérouler simultanément (passerelles AND)
- Les activités optionnelles qui peuvent être ignorées
- Les boucles où les activités se répètent
Le modèle découvert est affiché dans deux formats :
Arbre de processus – Vue hiérarchique montrant la structure du processus avec des opérateurs (séquence, choix, parallèle, boucle) et les nœuds d’activités.
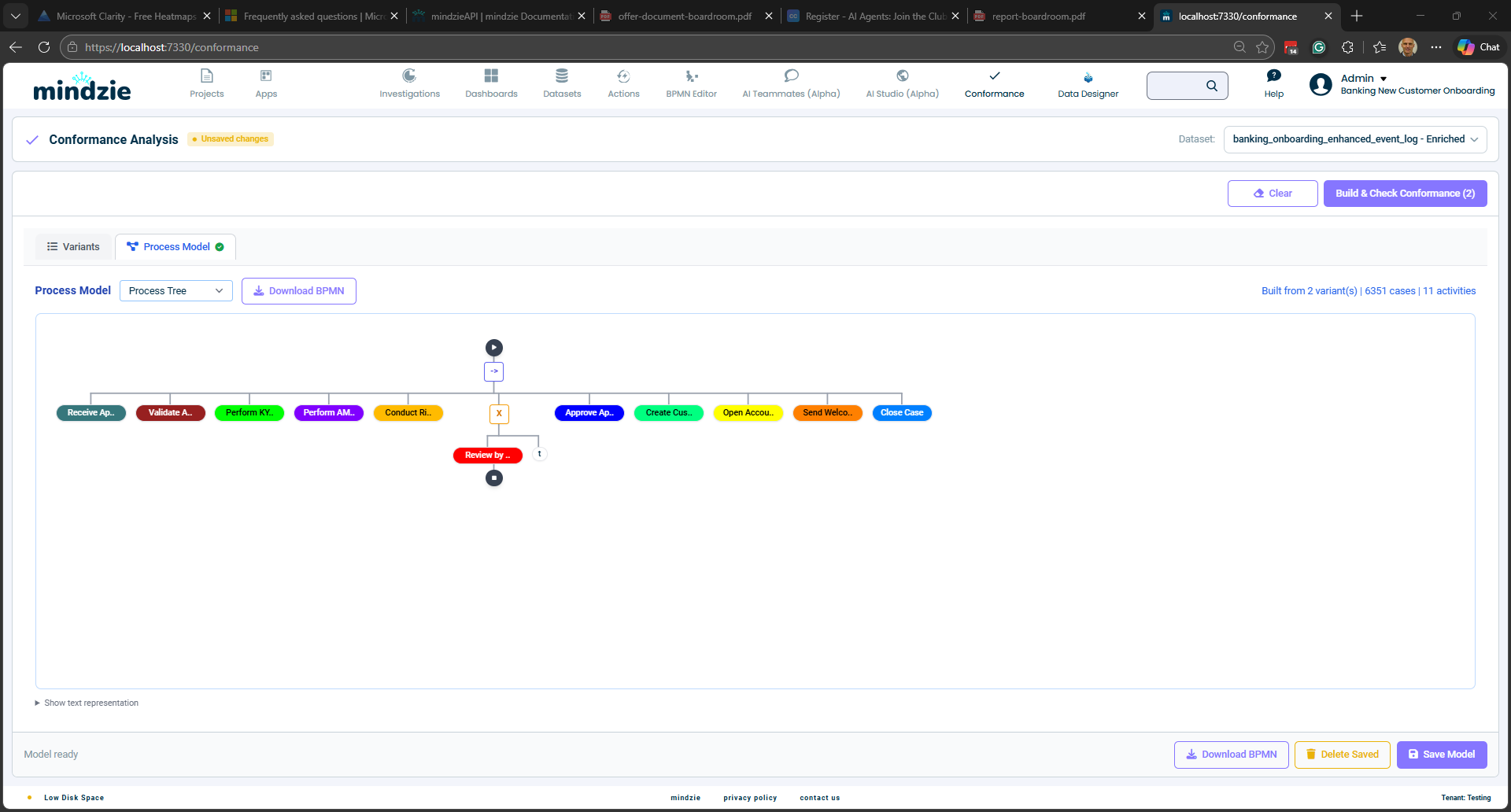
Diagramme BPMN – Un diagramme standard Business Process Model and Notation montrant le flux du processus avec événements de début/fin, blocs d’activités et losanges de passerelle.
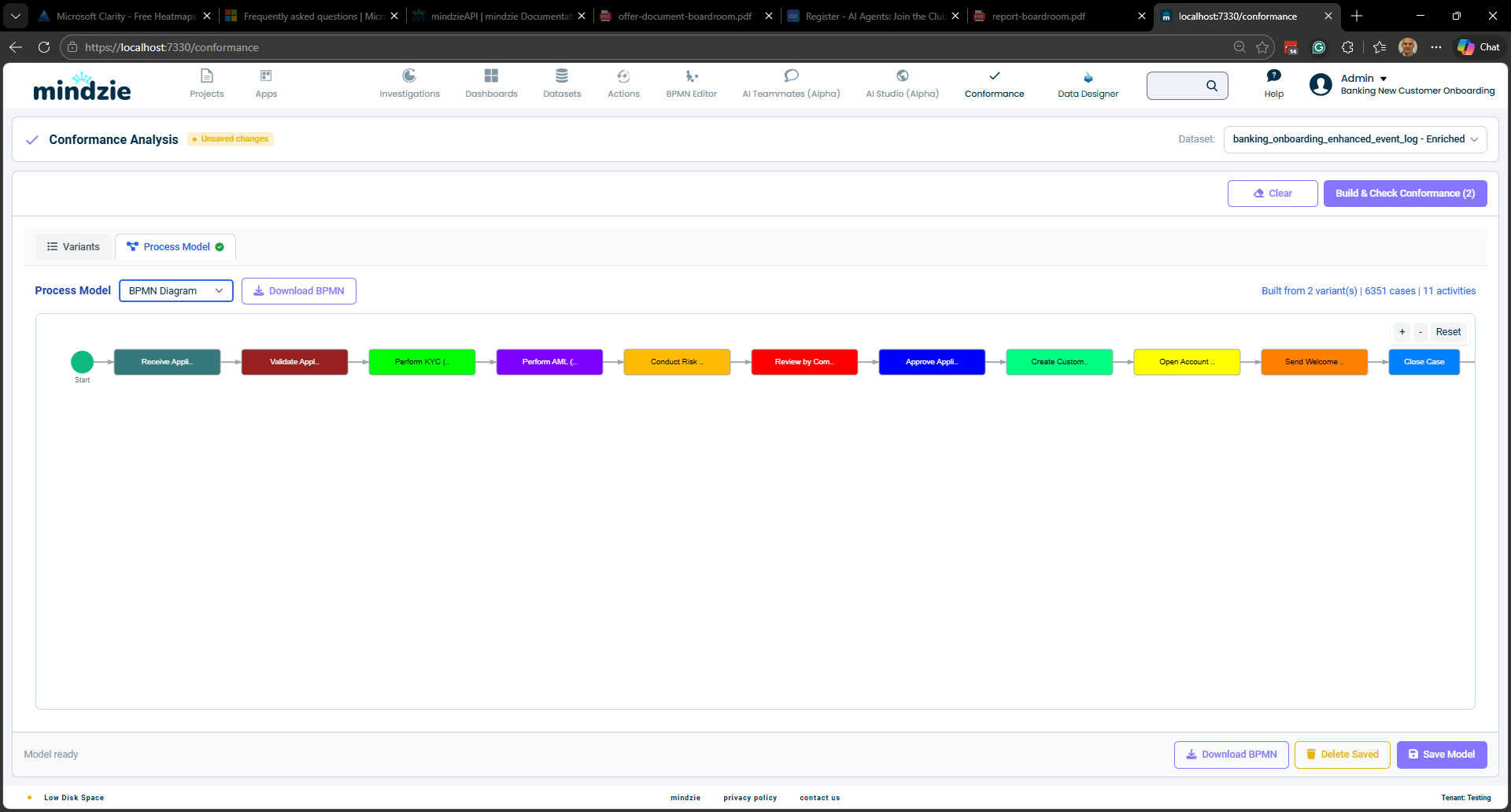
Vous pouvez basculer entre ces vues via le menu déroulant Process Model. Vous pouvez aussi télécharger le BPMN au format XML via le bouton Download BPMN.
Étape 3 : Vérifier la conformité
Une fois le modèle construit, mindzie le convertit en un réseau de Petri (modèle mathématique du processus) et utilise le rejeu de jetons pour vérifier chaque variante par rapport au modèle.
Le rejeu de jetons simule l'exécution de chaque cas à travers le réseau de Petri :
- Un jeton est placé au début du processus
- Pour chaque activité du cas, le système tente de déplacer le jeton via la transition correspondante dans le modèle
- Si la transition peut s’activer normalement, le cas est conforme à cette étape
- Si la transition ne peut pas s’activer (activité hors ordre ou inattendue), une violation de conformité est enregistrée
- Après toutes les activités, le système vérifie si le jeton a atteint la fin du processus
Cette simulation produit quatre mesures clés :
| Mesure | Signification |
|---|---|
| Jetons consommés | Total des jetons utilisés lors du rejeu (activités exécutées) |
| Jetons produits | Total des jetons créés lors du rejeu (transitions activées) |
| Jetons manquants | Jetons qu’il a fallu ajouter artificiellement car le modèle n’était pas dans l’état requis |
| Jetons restants | Jetons restant après le rejeu qui ne devraient pas être là |
Score d’adéquation
Le score d’adéquation est une valeur entre 0,0 et 1,0 qui quantifie dans quelle mesure une variante est conforme au modèle :
Fitness = 0.5 x (1 - missing/consumed) + 0.5 x (1 - remaining/produced)
- 1.0 = Conformité parfaite. La variante suit exactement le modèle.
- 0.8 = Bonne conformité. Écarts mineurs par rapport au modèle.
- 0.5 = Faible conformité. Écarts significatifs.
- 0.0 = Aucune conformité. La variante ne suit pas du tout le modèle.
Comment les écarts réduisent le score
Jetons manquants surviennent quand le cas fait quelque chose que le modèle n’attend pas à ce moment :
- Une activité se produit hors ordre
- Une activité est sautée et la suivante ne peut pas s’activer
Jetons restants surviennent quand le cas ne termine pas le processus attendu :
- Le cas se termine avant l’état final
- Une branche d’un processus parallèle n’est pas terminée
Activités non mappées surviennent quand le cas contient des activités qui n’existent pas du tout dans le modèle :
- Une étape supplémentaire a été réalisée qui ne fait partie d’aucune variante bonne
- Chaque activité non mappée réduit la conformité proportionnellement à la longueur de la trace
Une variante est considérée entièrement conforme uniquement si elle a zéro jetons manquants, zéro jetons restants et zéro activité non mappée.
Seuil (Threshold)
Le curseur Threshold (de 0.0 à 1.0) contrôle la rigueur de la vérification de conformité :
- À 1.0 (le plus strict) : seules les variantes correspondant parfaitement au modèle sont classées comme « Conformes »
- À 0.95 (recommandé) : les variantes avec des écarts très mineurs passent encore
- À 0.8 : les variantes avec écarts modérés passent
- À 0.5 : seules les variantes avec écarts majeurs échouent
Effet sur la classification
Après la vérification de conformité, le système classe chaque variante :
| Filtre | Couleur | Signification |
|---|---|---|
| In Model | Bleu | Variantes que vous avez explicitement sélectionnées comme bonnes |
| Fits | Vert | Variantes non sélectionnées qui atteignent le seuil d’adéquation |
| Fails | Rouge | Variantes non sélectionnées qui ne remplissent pas le seuil |
| Unclassified | Gris | Variantes non encore vérifiées |
Utilisez les cases à cocher du filtre en haut pour afficher ou masquer chaque catégorie.
Les variantes non sélectionnées peuvent-elles passer à un seuil de 1.0 ?
Oui. Si une variante non sélectionnée suit un chemin parfaitement valide dans le modèle de processus (chaque activité existe, chaque transition s’active correctement, et l’état final est atteint), elle recevra un score d’adéquation de 1.0 et sera classée « Conform ». C’est volontaire – le modèle représente tous les chemins valides, pas uniquement les variantes exactes que vous avez sélectionnées.
Par exemple, si vous sélectionnez deux variantes avec des branches différentes (A puis B, ou A puis C), le modèle crée une passerelle de choix. Toute autre variante suivant exactement l’une de ces branches aura aussi un score de 1.0.
Classification automatique des nouvelles variantes
Lorsque vous enregistrez un modèle de conformité et qu’il est appliqué comme enrichissement, les nouveaux cas qui arrivent ensuite sont automatiquement classifiés :
- Les cas dont la variante correspond à une variante bonne précédemment sélectionnée sont classifiés comme Good
- Les cas dont la variante correspond à une variante mauvaise précédemment sélectionnée sont classifiés comme Anomaly
- Les cas avec des variantes nouvelles et inconnues sont auto-classifiés en exécutant un rejeu de jetons sur le modèle enregistré
- Si le score d’adéquation atteint le seuil : classé Good (source : AutoConformance)
- Si le score d’adéquation est inférieur au seuil : classé Anomaly (source : AutoConformance)
Cela signifie que vos règles de conformité continuent de fonctionner lorsque de nouvelles données arrivent, sans avoir besoin de reclasser manuellement chaque nouvelle variante.
Enregistrement et utilisation du modèle
Enregistrer le modèle
Cliquez sur Save Model pour enregistrer le modèle de conformité. Cela sauvegarde :
- Vos sélections de variantes (bonnes/mauvaises/surclassées)
- Vos notes d’écart pour les mauvaises variantes
- Le modèle de processus découvert (BPMN et réseau de Petri)
- Le réglage du seuil d’adéquation
Le modèle enregistré est stocké comme un opérateur d’enrichissement sur le jeu de données, ce qui signifie qu’il s’exécute automatiquement à chaque actualisation du jeu de données.
Sortie d’enrichissement
Lorsque le modèle de conformité s’exécute en enrichissement, il ajoute cinq colonnes à vos données de cas :
| Colonne | Type | Valeurs |
|---|---|---|
| Is Variant Anomaly | Booléen | Oui / Non |
| Variant Classification | Texte | « Good » ou « Anomaly » |
| Variant Fitness Score | Pourcentage | 0 % à 100 % |
| Classification Source | Texte | « Explicit », « UserOverride » ou « AutoConformance » |
| Deviation Reason | Texte | Description de la raison de l’écart (issue de vos notes) |
La colonne Deviation Reason est remplie à partir des notes que vous avez écrites (ou générées par l’IA) lors du marquage des variantes comme Mauvaises. Pour les variantes explicitement rejetées avec une raison documentée, le texte exact de la note apparaît dans cette colonne. Pour les anomalies auto-classifiées, cette colonne est vide sauf si vous ajoutez ultérieurement une note.
Ces colonnes peuvent être utilisées dans des filtres, calculateurs et tableaux de bord pour analyser la conformité de votre processus. La colonne Deviation Reason est particulièrement utile pour créer des tableaux de bord montrant les types d’écarts de processus les plus fréquents.
Télécharger BPMN
Cliquez sur Download BPMN pour exporter le modèle de processus sous forme de fichier BPMN 2.0 XML standard. Ce fichier peut être ouvert dans n’importe quel outil compatible BPMN pour analyse ou documentation complémentaire.
Exemple de workflow
Voici un workflow typique pour configurer l’analyse de conformité :
- Chargez votre jeu de données et accédez à la page Conformance
- Commencez par le haut de la liste des variantes – les variantes sont triées par fréquence, donc les chemins les plus importants apparaissent en premier
- Triez chaque variante :
- Pour les chemins corrects : cliquez sur la coche (un clic, c’est fait)
- Pour les anomalies connues : cliquez sur le X, puis documentez la raison via la ligne de note
- Pour les variantes dont vous n’êtes pas sûr : laissez non classées et laissez le modèle décider
- Utilisez l’IA pour aider à documenter les écarts – cliquez sur le bouton étincelle pour générer une description comparant la variante rejetée à vos variantes bonnes acceptées
- Cliquez sur Build & Check Conformance pour générer le modèle et classer toutes les variantes restantes
- Passez à l’onglet Process Model pour examiner le diagramme BPMN découvert
- Ajustez le seuil si besoin en fonction de votre tolérance aux écarts
- Examinez les résultats : utilisez les filtres pour vous concentrer sur les variantes échouées et comprendre pourquoi elles dévient
- Cliquez sur Save Model pour sauvegarder le modèle de conformité, les notes d’écart, et activer la classification automatique sur les futurs rafraîchissements de données
- Créez des tableaux de bord avec les colonnes d’enrichissement (y compris Deviation Reason) pour suivre les indicateurs de conformité au fil du temps
Descriptions d’écarts assistées par IA
Quand l’IA est configurée pour votre locataire, le bouton étincelle apparaît à côté de la zone de texte pour les mauvaises variantes. En cliquant dessus, le contexte suivant est envoyé à l’IA :
- Toutes les variantes que vous avez marquées comme Bonnes (les chemins attendus)
- La variante spécifique que vous avez marquée comme Mauvaise (l’écart)
L’IA les compare et produit une explication en 1-2 phrases identifiant :
- Activités supplémentaires – étapes qui n’apparaissent dans aucune variante bonne
- Activités manquantes – étapes présentes dans les variantes bonnes mais absentes ici
- Ordre erroné – étapes dans une séquence différente
- Activités répétées – étapes qui se produisent plus que prévu
La suggestion de l’IA est placée dans la zone de texte. Vous pouvez l’accepter telle quelle, la modifier pour être plus précise, ou la remplacer entièrement par votre propre texte. L’IA est totalement optionnelle – si elle n’est pas configurée, le bouton étincelle n’apparaît pas et vous pouvez toujours saisir les notes manuellement.
Conseils
- Commencez avec quelques variantes bonnes seulement : sélectionner trop de variantes crée un modèle trop permissif. Débutez avec 1 à 3 variantes représentant le chemin principal.
- Travaillez de haut en bas : les variantes sont triées par fréquence. Classer les chemins les plus fréquents en premier vous donne la meilleure couverture avec moins d’effort.
- Documentez les écarts au fur et à mesure : écrire une note quand vous marquez une variante Mauvaise prend quelques secondes mais crée une documentation durable. Utilisez l’IA pour accélérer.
- Utilisez la vue Arbre de processus pour comprendre la structure du modèle découvert, notamment les points de décision et activités optionnelles.
- Réglez le seuil à 0,95 au départ : un seuil à 1,0 est très strict et peut signaler des variantes avec des différences triviales. Commencez à 0,95 et ajustez selon vos résultats.
- Consultez la colonne Classification Source : elle indique si une classification vient de votre sélection explicite, d’une surclassification ou de l’auto-classification. Utilisez-la pour auditer le traitement des nouvelles variantes.
- Exploitez la colonne Deviation Reason dans vos tableaux de bord : créez des rapports présentant les raisons d’écarts les plus fréquentes pour prioriser les efforts d’amélioration.
- Combinez avec d’autres enrichissements : utilisez la colonne "Is Variant Anomaly" comme entrée pour d’autres analyses, comme l’analyse des causes profondes des cas anormaux ou l’analyse des tendances de conformité dans le temps.