Téléversement et Configuration des Sources de Données
Aperçu
Ce guide vous accompagne dans le processus de téléversement de données CSV dans mindzie Studio et de configuration des colonnes clés pour l’analyse de process mining. La correspondance correcte de vos colonnes de données est essentielle pour que mindzie analyse efficacement vos processus métier.
Prérequis
Avant de téléverser des données, assurez-vous de disposer de :
- Un fichier CSV contenant les données de votre journal d’événements de processus
- Au minimum, les colonnes suivantes dans vos données :
- Case ID : Un identifiant unique pour chaque instance de processus
- Activity : Le nom de chaque étape ou activité du processus
- Timestamp : Date et heure auxquelles chaque activité a eu lieu
- Resource (recommandé) : La personne ou le système ayant réalisé l’activité
Choisir votre méthode d’importation de données
mindzie propose deux méthodes principales pour importer des données dans vos projets :
Téléversement CSV
Idéal pour :
- Analyse de données ponctuelle
- Projets de test et de preuve de concept
- Jeux de données plus petits
- Scénarios de mise à jour manuelle des données
mindzie Data Designer
Idéal pour :
- Surveillance continue et mises à jour programmées
- Connexion directe aux bases de données ou entrepôts de données
- Transformations ETL complexes
- Déploiements en production avec actualisation automatisée des données
Ce guide se concentre sur la méthode de téléversement CSV, qui est la façon la plus rapide de démarrer avec mindzie Studio.
Étape par étape : Téléversement d’un fichier CSV
Étape 1 : Accéder à la section Datasets
Lorsque vous entrez pour la première fois dans votre projet mindzie Studio, vous êtes dirigé automatiquement vers la section Datasets. Si vous n’y êtes pas déjà :
- Cliquez sur l’onglet Datasets dans la barre de navigation supérieure
- Vous verrez l’écran "Bienvenue dans mindzieStudio" avec plusieurs options
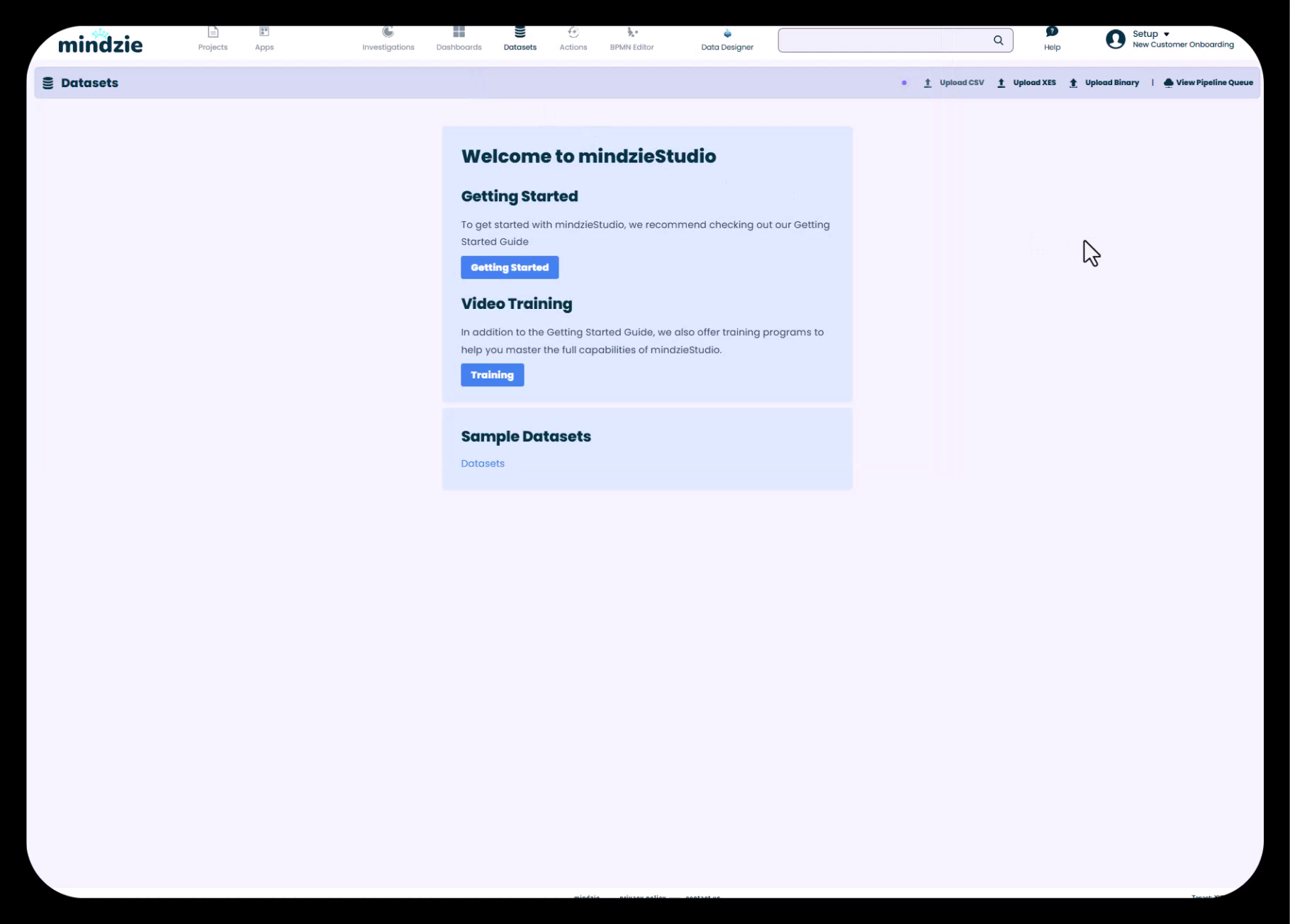
Étape 2 : Sélectionner Téléversement CSV
Sur l’écran Datasets, cliquez sur le bouton Upload CSV en haut à droite de l’interface. Cela ouvrira une boîte de dialogue de sélection de fichiers.
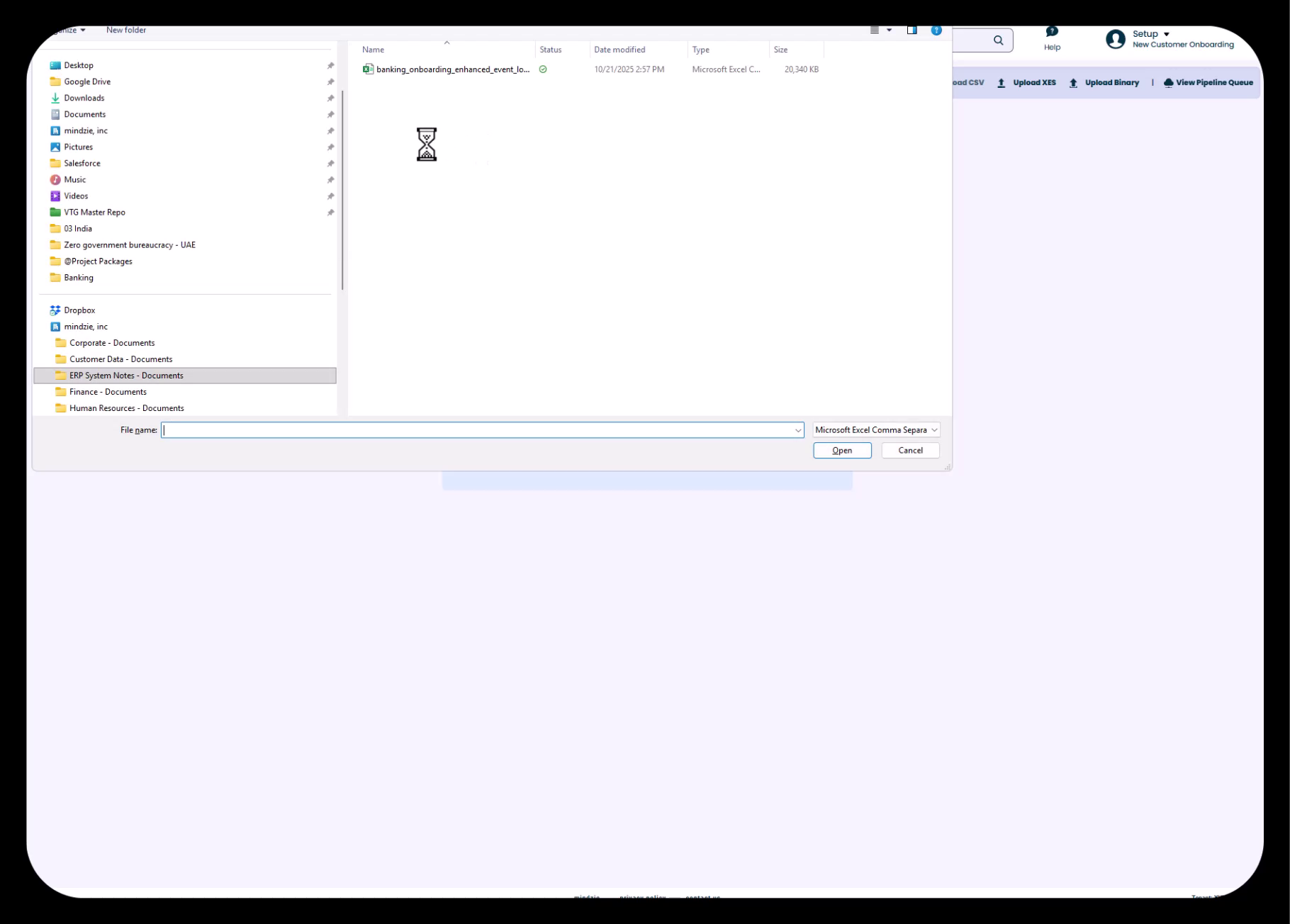
Étape 3 : Sélectionner votre fichier CSV
- Naviguez jusqu’à l’emplacement de votre fichier CSV sur votre ordinateur
- Sélectionnez le fichier (par exemple,
banking_onboarding_enhanced_event_log.csv) - Cliquez sur Open pour commencer le téléversement
Le système affichera un indicateur de chargement montrant la progression du téléversement.
Étape 4 : Valider et configurer les paramètres de données
Après le téléversement, mindzie Studio affichera un aperçu de vos données et vous permettra de configurer les paramètres :
Paramètres d’encodage
- Le système détectera automatiquement l’encodage du fichier
- Si vos données contiennent des caractères spéciaux, vous pourriez avoir besoin d’ajuster ce paramètre
Aperçu des données
- Vérifiez que l’aperçu montre bien les données chargées correctement
- Contrôlez que les colonnes sont correctement séparées
- Assurez-vous que les horodatages et autres valeurs s’affichent comme prévu
Une fois la vérification terminée, cliquez sur Next pour passer au mappage des colonnes.
Configuration des colonnes clés
L’écran de mappage des colonnes est l’endroit où vous indiquez à mindzie Studio quelles colonnes de votre CSV correspondent aux champs clés du process mining.
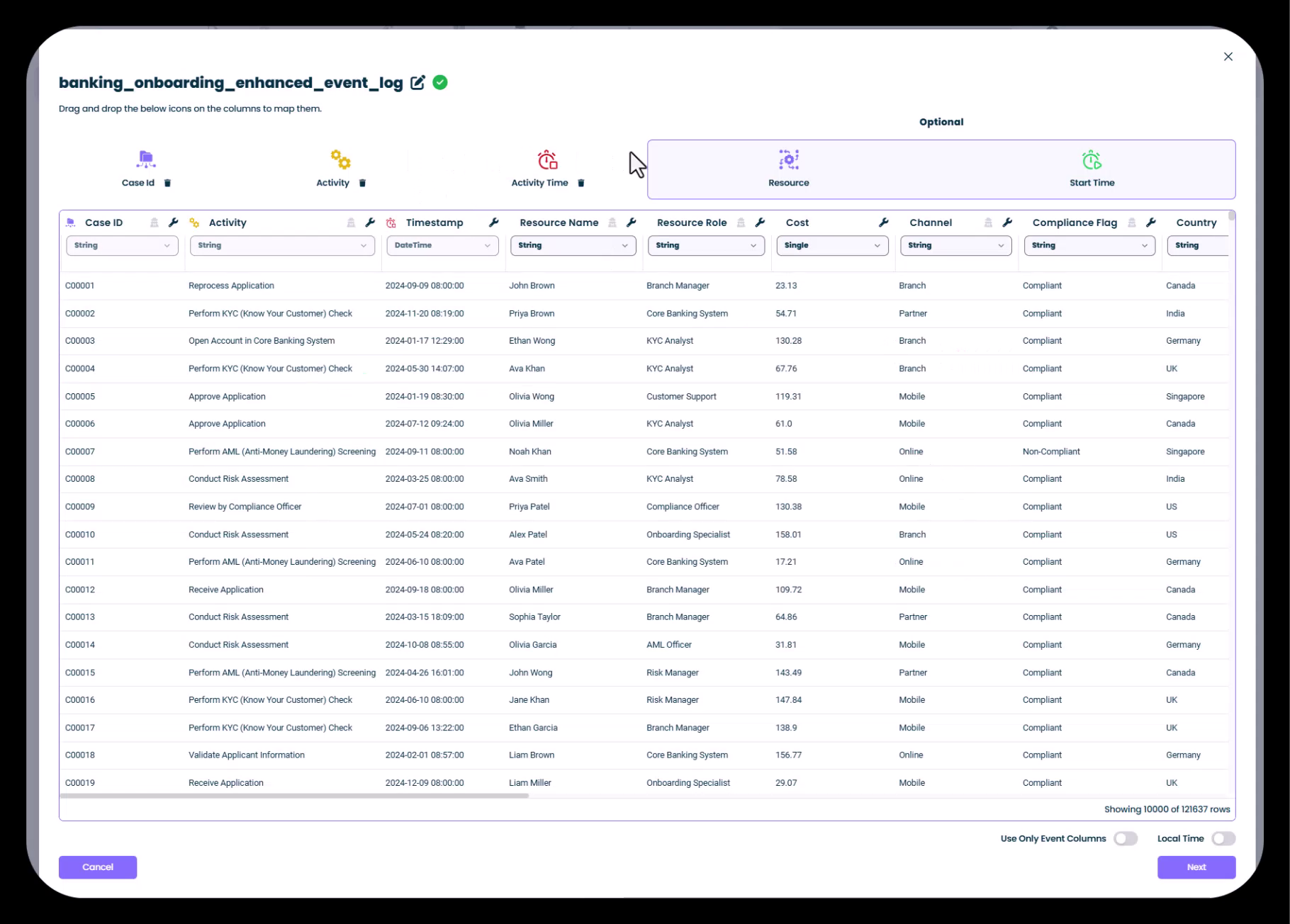
Comprendre les icônes des colonnes clés
mindzie Studio utilise des icônes visuelles pour vous aider à identifier et mapper les colonnes clés :
- Case ID : icône violette - Identifie les instances uniques de processus
- Activity : icône jaune - Contient les noms des étapes du processus
- Activity Time : icône orange - Horodatage du moment où chaque activité a eu lieu
- Resource : icône bleue - Personne ou système réalisant l’activité
Étape 5 : Mapper vos colonnes par glisser-déposer
mindzie Studio détecte automatiquement et suggère les correspondances pour les noms de colonnes courants. Pour mapper ou modifier les affectations :
- Détection automatique : le système détecte généralement automatiquement les colonnes standard comme Case ID, Activity et Timestamp
- Glisser-déposer : pour affecter une colonne manuellement, faites-la glisser depuis la section inférieure vers une des cases des colonnes clés en haut
- Affectation de la ressource : si vous avez une colonne resource (recommandé), faites-la glisser vers le champ Resource
Dans l’exemple montré :
- Case ID est mappé sur la colonne
Case ID - Activity est mappé sur la colonne
Activity - Timestamp est mappé sur la colonne
DateTime - Resource Name est mappé sur la colonne
Resource Name
Étape 6 : Configurer les paramètres supplémentaires des colonnes
Pour chaque colonne de votre jeu de données, vous pouvez :
Changer le type de colonne
- Cliquez sur une colonne pour modifier son type
- Options disponibles : chaîne de caractères, nombre, date, booléen, etc.
Modifier les types de données
- Ajustez la façon dont mindzie interprète les données
- Assurez-vous que les dates sont reconnues comme des horodatages
- Confirmez que les valeurs numériques sont correctement typées
Anonymiser les données sensibles
- Activez l’anonymisation pour les colonnes contenant des données sensibles
- Utile pour respecter les réglementations sur la confidentialité des données
- Les noms, ID clients et autres informations personnelles peuvent être masqués
Colonnes optionnelles La section « Optionnel » à droite de l’écran permet de mapper des attributs supplémentaires pour le process mining :
- Resource Role : poste ou rôle de la ressource
- Cost : coûts associés à chaque activité
- Channel : canal du processus (ex. Agence, Mobile, En ligne)
- Compliance Flags : indicateurs de conformité ou respect des règles
- Country/Region : attributs géographiques
Étape 7 : Traiter et enregistrer le jeu de données
Une fois le mappage terminé :
- Vérifiez toutes les correspondances pour en assurer la précision
- Cliquez sur Next pour lancer le traitement
mindzie Studio va maintenant :
- Transformer vos données CSV au format journal d’événements mindzie
- Valider la qualité et la structure des données
- Créer le jeu de données de base pour l’analyse
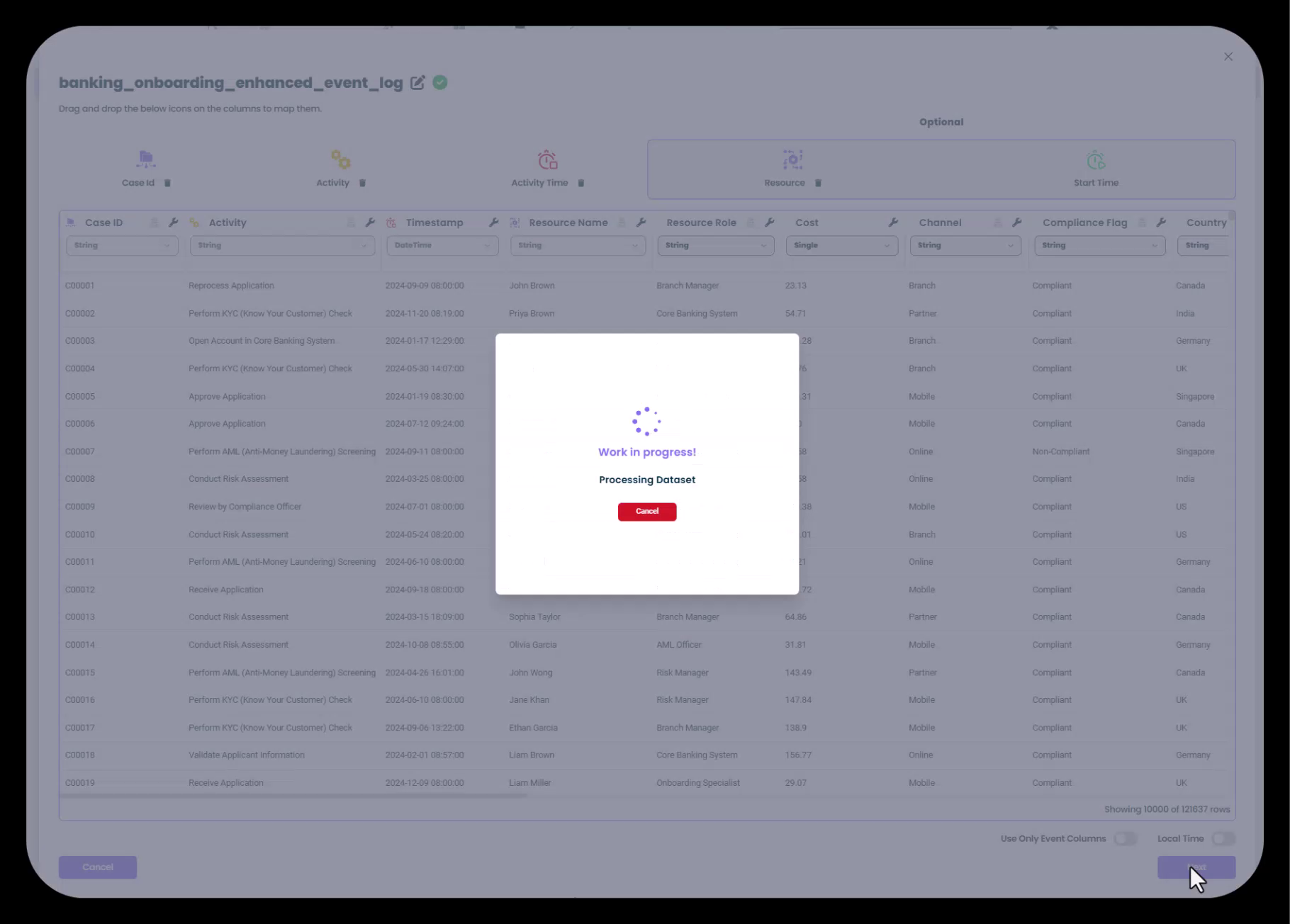
Cette étape de traitement peut prendre quelques instants selon la taille du jeu de données. Vous verrez une boîte de dialogue "Travail en cours ! Traitement du jeu de données" pendant ce temps.
Étape 8 : Confirmer la réussite de l’importation des données
Une fois le traitement terminé, mindzie Studio affichera un dialogue de confirmation indiquant :
- Le nom du jeu de données
- Le nombre total de cas (instances de processus)
- Le nombre total d’événements (activités)
Dans l’exemple présenté, le jeu de données contient :
- 10 000 cas (instances uniques d’onboarding client)
- 121 000 événements (activités totales pour tous les cas)
Cliquez sur Save pour finaliser l’import.
Que se passe-t-il après le téléversement des données
Une fois que vous avez enregistré votre jeu de données, mindzie Studio exécute automatiquement :
Création de deux jeux de données :
- Jeu de données original : votre journal d’événements brut tel que téléversé
- Jeu de données enrichi : version améliorée créée par le pipeline mindzie (utilisée pour toutes les analyses)
Construction d’un pipeline de données : prépare vos données pour l’enrichissement avec métriques de performance, règles de conformité et autres améliorations
Génération d’analyses par défaut : création d’analyses de démarrage incluant :
- Vue d’ensemble du processus
- Analyse des cas à longue durée
- Durée entre les étapes principales du processus
- Autres insights fondamentaux
Ces analyses par défaut vous donnent un point de départ pour comprendre votre processus et peuvent être personnalisées ou supprimées selon vos besoins.
Comprendre la transformation des données
Pendant la phase de téléversement et de traitement, mindzie Studio :
- Standardise le format des données : convertit votre CSV au format optimisé de journal d’événements mindzie
- Valide la qualité des données : vérifie les champs obligatoires manquants, les horodatages invalides et les incohérences dans les données
- Prépare à l’enrichissement : structure les données pour pouvoir être améliorées avec des attributs calculés, des métriques de performance et des règles de conformité
Le processus de transformation garantit que vos données sont prêtes pour une analyse puissante et une visualisation du process mining.
Conseils pour un téléversement réussi
Nomination des colonnes
- Utilisez des noms de colonnes clairs et cohérents dans votre CSV
- Des noms courants comme "CaseID", "Activity", "Timestamp" sont détectés automatiquement
- Évitez les caractères spéciaux dans les noms de colonnes
Qualité des données
- Assurez-vous que chaque ligne a un Case ID, une Activity et un Timestamp
- Les horodatages doivent suivre un format cohérent (ISO 8601 recommandé)
- Supprimez ou corrigez les en-têtes dupliqués ou les lignes malformées
Considérations sur la taille du fichier
- Le téléversement CSV fonctionne bien pour des jeux de données jusqu’à plusieurs millions d’événements
- Pour des jeux très volumineux ou une surveillance continue, préférez mindzie Data Designer
- Testez d’abord avec un échantillon de vos données pour vérifier le mappage des colonnes
Colonnes Resource et optionnelles
- Bien que seules les colonnes Case ID, Activity et Timestamp soient requises, ajouter des informations Resource permet une analyse plus approfondie
- Des colonnes supplémentaires comme Cost, Channel et Region permettent des segmentations et insights plus riches
- Vous pouvez toujours ajouter d’autres colonnes optionnelles plus tard via l’enrichissement des données
Prochaines étapes
Après avoir téléversé et configuré avec succès votre source de données :
- Vérifiez les jeux de données générés : consultez les jeux original et enrichi dans la section Datasets
- Explorez les analyses par défaut : allez dans Investigations pour voir les insights générés automatiquement
- Planifiez la structure de vos tableaux de bord : décidez des tableaux de bord et métriques à créer pour vos utilisateurs
- Améliorez vos données : utilisez le Log Enrichment Engine pour ajouter des métriques de performance, des règles de conformité et des attributs personnalisés
Vos données sont désormais prêtes à être transformées en intelligence processuelle exploitable !
Sujets connexes
- Comprendre l’architecture duale des jeux de données mindzie : Découvrez les différences entre jeux originaux et enrichis
- Maîtriser le Log Enrichment Engine : Ajoutez des métriques de performance et des règles de conformité pour enrichir vos données
- Utiliser mindzie Data Designer : Connectez-vous à des sources de données en direct pour une actualisation automatique des données
- Créer votre première analyse : Construisez des métriques et KPIs à partir de vos données téléversées