Analyse Causale IA (Alpha)
Le calculateur d'Analyse Causale IA utilise le machine learning pour découvrir quels attributs de cas influencent le plus fortement un résultat cible. Au lieu de simplement montrer une corrélation, il isole les caractéristiques qui ont le plus grand impact statistique sur la question de savoir si un cas répond au résultat que vous définissez - afin de passer du "qu'est-ce qui se passe" au "pourquoi cela se passe".
Fonctionnalité Alpha : Ce calculateur fait partie du programme Alpha de mindzie. Il nécessite que PreRelease soit activé pour votre locataire. Voir Fonctionnalités Alpha pour plus d'informations.
Vue d'ensemble
L'Analyse Causale IA répond à des questions telles que :
- Pourquoi certains cas mettent-ils plus de 7 jours à se terminer ?
- Quels attributs rendent une facture plus susceptible d'être payée en retard ?
- Qu'est-ce qui distingue les cas qui enfreignent les SLA de ceux qui les respectent ?
- Quels établissements, équipes ou catégories de produits influencent le plus un résultat donné ?
Vous définissez le résultat (les cas que vous souhaitez expliquer), vous indiquez au calculateur un ensemble de colonnes d'entrée, et il retourne une liste classée des facteurs les plus responsables du fait que ces cas tombent dans le groupe du résultat.
Comparaison avec l'Analyse des Causes Profondes
L'Analyse Causale IA partage un objectif avec le calculateur Analyse des Causes Profondes existant, mais adopte une approche beaucoup plus rigoureuse :
| Capacité | Analyse des Causes Profondes | Analyse Causale IA |
|---|---|---|
| Trouve les moteurs à attribut unique | Oui | Oui |
| Trouve les conjonctions multi-attributs (jusqu'à 3 attributs par règle) | Non | Oui |
| Distingue corrélation et causalité | Non | Oui (graphe causal + ajustement de propension) |
| Rapporte les intervalles de confiance | Non | Oui (IC Wilson à 95% sur chaque règle) |
| Contrôle les tests multiples | Non | Oui (FDR Benjamini-Hochberg) |
| Gère les attributs numériques / date / heure | Non (chaînes uniquement) | Oui (binning conscient du résultat) |
| Narration en français clair par moteur | Non | Oui |
Utilisez l'Analyse des Causes Profondes pour un scan rapide à attribut unique, et l'Analyse Causale IA pour toute investigation sérieuse - en particulier lorsque quelqu'un agira sur la base du résultat.
Comment Ajouter le Calculateur
- Ouvrez un carnet dans mindzieStudio
- Cliquez sur Ajouter un Calculateur et sélectionnez Analyse Causale IA (Alpha)
- Configurez le résultat et les colonnes d'entrée (voir ci-dessous)
- Cliquez sur Créer
Configuration
Titre
Le nom d'affichage du calculateur. Par défaut Analyse Causale IA (Alpha) - remplacez-le par quelque chose de spécifique à la question à laquelle vous répondez, par exemple Pourquoi les séjours en soins intensifs sont-ils longs ? ou Moteurs des Paiements en Retard.
Description
Notes en texte libre optionnelles. Utile pour documenter la question métier, la plage de dates sur laquelle l'analyse a été exécutée, ou le commanditaire qui l'a demandée.
Définition du Résultat
Le résultat est le groupe de cas que vous souhaitez expliquer. Le calculateur compare ces cas au reste du jeu de données et identifie quelles colonnes d'entrée séparent le mieux les deux groupes.
Trois modes sont disponibles pour définir le résultat :
Mode Filtre
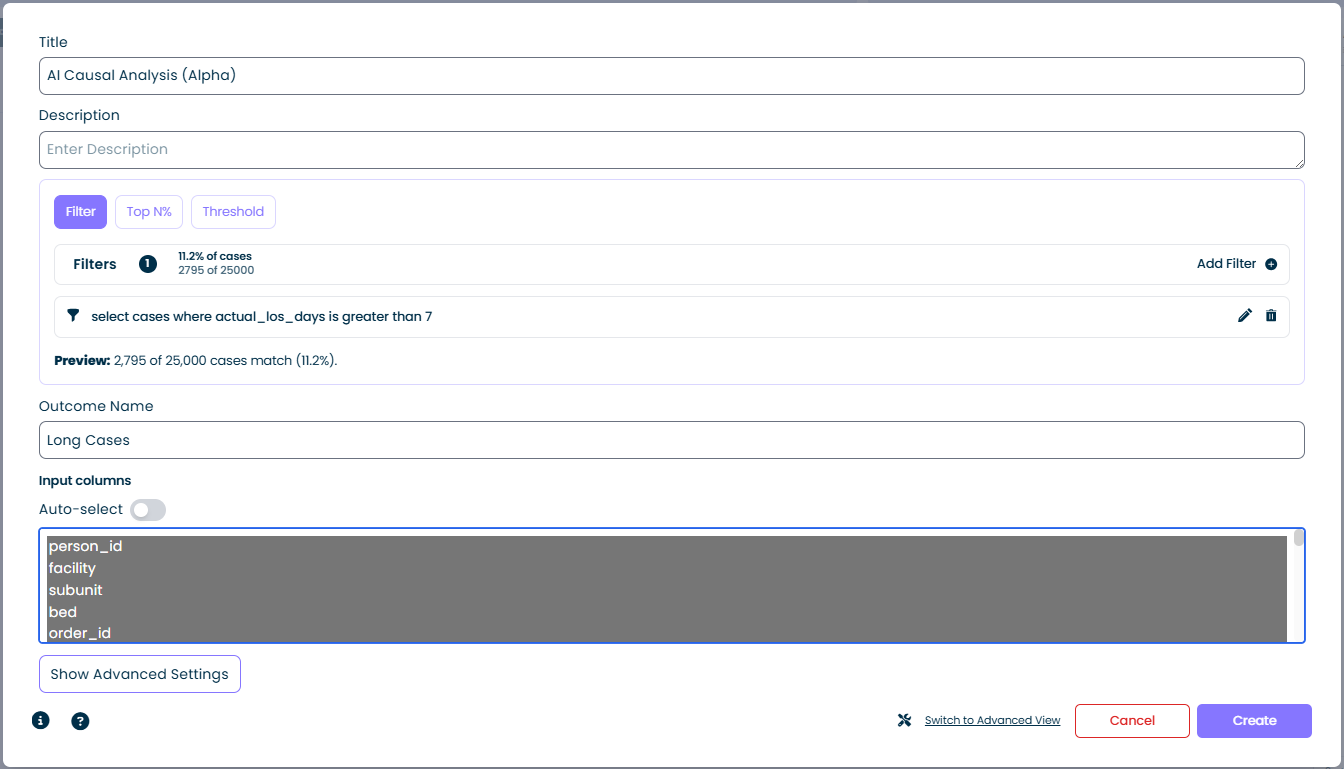
Sélectionnez l'onglet Filtre et ajoutez une ou plusieurs expressions de filtre. Le calculateur traite les cas qui correspondent au filtre comme le groupe "résultat".
- Cas correspondants : affiché sous forme de pourcentage et de décompte brut, par exemple
11,2 % des cas / 2 795 sur 25 000 - Ajouter un Filtre : ouvre le constructeur de filtre standard - combinez n'importe quel nombre de conditions
- Aperçu : se met à jour en direct pendant que vous construisez le filtre afin que vous puissiez valider la sélection avant d'exécuter le calculateur
Le mode Filtre est l'option la plus flexible. Toute condition exprimable sous forme de filtre mindzie (seuils de durée, correspondances d'attributs, présence d'activités, etc.) peut devenir un résultat. Dans la capture d'écran ci-dessus, le filtre select cases where actual_los_days is greater than 7 définit les "Cas Longs" comme résultat.
Mode Top N%
Sélectionnez l'onglet Top N% pour utiliser les valeurs les plus élevées (ou les plus basses) d'un attribut numérique comme résultat. Ceci est utile lorsque vous souhaitez expliquer "les pires cas" ou "les meilleurs performeurs" sans avoir à choisir un seuil strict. Exemple : les 10 % des cas ayant le temps de cycle le plus élevé.
Mode Seuil
Sélectionnez l'onglet Seuil pour définir le résultat avec une seule coupure numérique sur un attribut. Tout cas au-dessus (ou en dessous) de la valeur devient partie du groupe de résultat. Exemple : cas où invoice_amount dépasse 50 000.
Nom du Résultat
Une courte étiquette qui identifie le groupe de résultat dans les résultats, par exemple Cas Longs, Paiements en Retard, ou Violation SLA. Ce nom apparaît dans toute la sortie d'analyse partout où le groupe de résultat est référencé.
Colonnes d'Entrée
Les colonnes que le modèle est autorisé à utiliser lors de la recherche de moteurs du résultat.
- Liste des colonnes : chaque attribut de cas dans le jeu de données est affiché. Sélectionnez-en un ou plusieurs pour les inclure dans l'analyse. Les colonnes sont mises en évidence lorsqu'elles sont sélectionnées.
- Auto-sélection bascule : lorsque activée, mindzie choisit automatiquement un ensemble par défaut sensé de colonnes d'entrée en fonction du schéma du jeu de données. Désactivez ceci lorsque vous souhaitez un contrôle manuel complet - par exemple pour exclure une colonne trivialement corrélée au résultat (comme un ID qui révèle la réponse).
Conseils pour choisir les colonnes d'entrée :
- Excluez les colonnes en aval du résultat. Si
discharge_dateest utilisé pour calculeractual_los_days, il dominera les résultats sans ajouter d'insight. - Excluez les identifiants à haute cardinalité (
person_id,order_id) sauf si vous voulez spécifiquement des effets par entité. - Incluez les attributs contextuels (établissement, catégorie de produit, priorité, région) - c'est généralement là que vivent les moteurs intéressants.
Afficher les Paramètres Avancés
Ouvre des options de réglage supplémentaires pour la recherche. Les valeurs par défaut fonctionnent bien pour la plupart des analyses - ne les remplacez que lorsque vous avez une raison spécifique.
| Paramètre | Défaut | Objectif |
|---|---|---|
| Beam width | 50 | Combien de règles candidates sont conservées à chaque profondeur de recherche. Plus élevé = plus exhaustif, plus lent. |
| Profondeur max de règle | 3 | Règle la plus longue autorisée. 3 signifie des règles de la forme A AND B AND C. |
| Min cas par règle | 30 | Les règles qui affecteraient moins de ce nombre de cas sont écartées comme trop petites pour être actionnables. |
| Lift min | 1,2 | Le taux de résultat dans la règle doit dépasser la valeur de référence d'au moins ce facteur (1,2 = au moins 20 % plus élevé que la référence). |
| FDR alpha | 0,05 | Seuil de significativité Benjamini-Hochberg pour contrôler les fausses découvertes dans la recherche de règles. |
| Max de moteurs retournés | 20 | Borne supérieure du nombre de règles affichées dans la vue tableau complet. |
| Jaccard de redondance | 0,9 | Les règles dont les ensembles de cas se chevauchent de plus que cette fraction sont traitées comme des doublons et filtrées. |
| Seuil d'échantillonnage | 2 000 000 de cas | Les jeux de données au-dessus de cette taille sont échantillonnés de manière déterministe à l'aide de l'algorithme de combinaison de Floyd. La sortie indique WasSampled = true et la taille réelle de l'échantillon. |
Passer à la Vue Avancée
Bascule l'éditeur en mode avancé pour un contrôle granulaire de chaque paramètre du modèle. La vue guidée présentée ici est suffisante pour la grande majorité des cas d'usage.
Flux de Travail Typique
- Cadrer la question - décidez quel résultat vous souhaitez expliquer. "Qu'est-ce qui rend les cas lents ?" devient un résultat Filtre de
case_duration > 7 jours. - Définir le résultat - utilisez le mode Filtre, Top N% ou Seuil. Vérifiez que le pourcentage d'Aperçu semble raisonnable (trop peu de cas produira des résultats instables ; trop signifie que le résultat n'est pas vraiment distinctif).
- Nommer le résultat - choisissez une étiquette concise qui se lira bien dans les résultats et les rapports.
- Sélectionner les colonnes d'entrée - commencez par Auto-sélection, puis élaguez les colonnes qui révèlent la réponse ou ajoutent du bruit.
- Créer - exécutez le calculateur. Le résultat fait émerger les moteurs classés du résultat.
- Interpréter - examinez les principaux moteurs, affinez le résultat ou l'ensemble d'entrée si nécessaire, puis ré-exécutez.
Exemple
Une équipe des opérations hospitalières souhaite comprendre pourquoi certains séjours hospitaliers durent plus de 7 jours.
| Paramètre | Valeur |
|---|---|
| Titre | Analyse Causale IA (Alpha) |
| Mode Filtre | select cases where actual_los_days is greater than 7 |
| Aperçu | 2 795 sur 25 000 cas correspondent (11,2 %) |
| Nom du Résultat | Cas Longs |
| Colonnes d'entrée | facility, subunit, bed, order_id, ... (auto-sélectionnées) |
Après l'exécution, le calculateur rapporte quelles combinaisons d'établissement, de sous-unité et d'attributs de soin distinguent le plus fortement les cas à long séjour des cas à séjour normal. Cela oriente l'équipe vers des unités et des flux de travail spécifiques à investiguer plutôt que de les laisser explorer manuellement chaque attribut.
Interprétation des Résultats
Pour chaque moteur principal, le calculateur produit un paragraphe narratif en français clair et un badge de preuve décrivant la force de la conclusion :
| Badge | Signification | Comment agir |
|---|---|---|
| Causal | À la fois le signal du graphe causal et l'effet ajusté aux facteurs de confusion sont positifs. | Preuve actionnable la plus forte - sûr à prioriser pour une intervention. |
| Probablement Causal | Le graphe causal relie la règle au résultat, mais l'effet s'affaiblit une fois ajusté pour les facteurs de confusion. | Prometteur - à investiguer davantage avant d'agir. |
| Associé | L'effet survit à l'ajustement, mais le graphe ne place pas la règle sur un chemin direct vers le résultat. | Association réelle, mais probablement indirecte - peut être un proxy pour le vrai moteur. |
| Corrélationnel | Il existe une association mais nous ne pouvons pas confirmer une relation causale. | Signal diagnostique uniquement - ne pas agir sur cette base seule. |
Exemple de narration pour une règle Causale :
Channel = Online est un moteur probable de Non-First Contact Resolution. Les cas correspondant à cette règle montrent un taux de résultat de 46,1 % contre 29,0 % de référence (1,59x, IC 95 % 1,51x - 1,68x, p < 0,001). Elle couvre 2 518 cas, représentant 34,7 % de toutes les occurrences de Non-First Contact Resolution. L'effet a survécu à l'ajustement pour les autres moteurs principaux et se situe sur un chemin direct vers le résultat dans le graphe causal appris.
La vue Tableau Complet ajoute la liste classée complète avec la couverture, le lift, l'intervalle de confiance, l'effet ajusté, la p-value, et le badge pour chaque règle ayant survécu à la recherche et au filtre de significativité.
Comment Fonctionne l'Algorithme
L'Analyse Causale IA exécute un pipeline en cinq étapes. Chaque étape a une tâche spécifique et est conçue pour que l'ensemble se termine en quelques secondes même sur des jeux de données d'un million de cas.
1. Préparation et binning
- Le calculateur prend les cas dans votre groupe de résultat et les étiquette
1; tous les autres sont étiquetés0. C'est le taux de référence que vous voyez dans la sortie. - Les attributs catégoriels (chaînes, booléens, entiers à faible cardinalité) sont utilisés directement. Chaque valeur distincte devient un littéral candidat (par exemple,
facility = Memorial). - Les attributs numériques et date/heure sont binnés avec un binner MDL-optimal conscient du résultat. Au lieu de choisir des bins à largeur égale ou à fréquence égale, le binner choisit des points de coupure qui séparent le mieux les cas de résultat des cas hors résultat, puis utilise le principe de Minimum Description Length (MDL) pour choisir automatiquement le nombre de bins. Cela transforme une colonne numérique comme
actual_los_daysen un petit ensemble de buckets significatifs (par exemple,<= 3 jours,4 - 7 jours,> 7 jours).
2. Indexation bitmap
Chaque littéral est stocké sous forme de bitset - un bit par cas, 1 si le cas correspond au littéral. Combiner des littéraux avec AND devient une intersection bit à bit rapide :
facility = Memorial AND priority = Highest calculé commebitset_A & bitset_B.- La couverture, le nombre de résultats et le lift pour une règle candidate peuvent être évalués en microsecondes quelle que soit la profondeur de la règle.
Les littéraux qui couvrent moins que Min cas par règle sont abandonnés avant le début de la recherche.
3. Découverte de sous-groupes par beam search
Le calculateur parcourt l'espace des règles en largeur :
- Profondeur 1 : évaluer chaque littéral unique. Scorez chacun à l'aide d'une mesure de qualité (lift et Weighted Relative Accuracy) et conservez les
Beam widthpremiers (par défaut 50). - Profondeur 2 : étendez chaque règle conservée avec chaque autre littéral compatible pour former des conjonctions comme
A AND B. Scorez-les toutes et conservez à nouveau lesBeam widthpremières. - Profondeur 3 : répétez une fois de plus. Arrêtez à
Profondeur max de règle.
Les règles qui tombent en dessous de Lift min ou Min cas par règle sont élaguées à chaque niveau.
Après la recherche, un filtre de redondance Jaccard supprime les règles quasi-dupliquées : si deux règles couvrent essentiellement les mêmes cas (chevauchement au-dessus de Jaccard de redondance, par défaut 0,9), seule la meilleure est conservée.
4. Significativité statistique
Pour chaque règle survivante, le calculateur calcule :
- Le risk ratio (taux de résultat dans la règle divisé par le taux de référence) et son intervalle de confiance Wilson à 95%, qui se comporte bien pour les probabilités petites et extrêmes où l'approximation normale échoue.
- Une p-value sous l'hypothèse nulle que la règle n'a aucun effet.
- Une correction FDR Benjamini-Hochberg sur toutes les règles testées.
FDR alpha(par défaut 0,05) définit le taux de fausse découverte attendu. Les règles qui ne survivent pas au FDR ne sont pas rapportées, ce qui empêche la recherche de vous noyer sous des conclusions fallacieuses.
5. Adjudication causale
La significativité seule ne vous dit toujours qu'il existe une association. Deux signaux supplémentaires décident si une règle reçoit un badge Causal :
- Signal de graphe causal - un score structurel bayésien léger appris à partir des attributs et du résultat. Il demande : cette règle se situe-t-elle sur un chemin direct vers le résultat dans le graphe appris, ou seulement sur un chemin indirect à travers un facteur de confusion ?
- Ajustement par score de propension - une régression logistique régularisée ridge modélise la probabilité que chaque cas corresponde à la règle, étant donné tous les autres moteurs principaux. L'effet de la règle est ensuite réestimé après pondération par cette propension. Si l'effet rétrécit à zéro, la règle n'était qu'un proxy pour d'autres moteurs ; s'il persiste, elle a un pouvoir explicatif indépendant.
L'adjudicateur combine les deux signaux dans les quatre badges de preuve définis ci-dessus.
6. Génération de narration
L'étape finale compose le paragraphe en français clair affiché dans la vue carte. Elle tisse ensemble la définition de la règle, les taux de résultat dans la règle et de référence, le risk ratio et l'intervalle de confiance, la p-value, la couverture, et le badge de preuve en une structure de phrase ajustée pour se lire naturellement pour un lecteur non statisticien.
Performance
Mesurée sur une machine de développement :
| Jeu de données | Temps |
|---|---|
| 100 000 cas x 4 colonnes | moins d'1 seconde |
| 200 000 cas x 20 colonnes | moins de 2 secondes |
| 1 000 000 cas x 50 colonnes | environ 3 secondes |
Les jeux de données au-dessus du seuil d'échantillonnage (par défaut 2 000 000 de cas) sont échantillonnés de manière déterministe à l'aide de l'algorithme de combinaison de Floyd. Lorsque cela se produit, la sortie signale WasSampled = true et rapporte la taille réelle de l'échantillon afin que le résultat soit reproductible et que l'échantillonnage soit visible.
Limitations Connues (v1)
- Résultats binaires uniquement. Les résultats multi-classes (rapide / moyen / lent, par exemple) ne sont pas pris en charge dans cette version. Définissez les divisions bidirectionnelles comme des analyses séparées.
- Pas encore d'explications par cas. La v1 répond à "qu'est-ce qui motive ce résultat dans le jeu de données ?" Une version future ajoutera des panneaux "pourquoi ce cas spécifique a-t-il mal tourné ?".
- Pas d'analyse de dérive temporelle. Si les moteurs changent entre trimestres, la v1 ne les divisera pas dans le temps. Exécutez le calculateur séparément sur chaque tranche de temps lorsque cela compte.
- Le binning numérique est conscient du résultat. Si vous voulez des bins fixes, choisis par un humain, pré-catégorisez la colonne avec un enrichissement avant d'exécuter le calculateur.
Cas d'Usage
Moteurs de Performance
Identifier les attributs les plus associés aux cas qui enfreignent les SLA, dépassent le budget, ou vont au-delà de leur durée prévue. Fonctionne bien avec un résultat Filtre construit sur un enrichissement de durée ou de KPI.
Analyse des Résultats
Comparer les cas réussis avec les cas échoués ou annulés. Utilisez un résultat Filtre sur un attribut de statut ou de résultat pour voir quels attributs en amont prédisent chaque résultat.
Risque et Conformité
Pointez le calculateur sur les cas signalés par un enrichissement de conformité ou de contrôle pour apprendre quels facteurs contextuels sont corrélés aux échecs de conformité.
Analyse des Meilleurs Performeurs
Utilisez le mode Top N% pour expliquer ce qui rend vos meilleurs cas, équipes ou clients différents du reste. Réinjectez les insights dans la conception de processus ou la formation.
Conseils
- Commencez simplement. Un Filtre bien choisi avec deux ou trois conditions plus des entrées auto-sélectionnées produit généralement les résultats les plus clairs.
- Surveillez le pourcentage d'aperçu. Si le groupe de résultat est inférieur à ~2 % ou supérieur à ~50 % du jeu de données, l'analyse devient plus difficile à interpréter. Ajustez le filtre jusqu'à ce que le groupe soit une minorité significative.
- Itérez sur les colonnes d'entrée. Retirez les colonnes dont la présence domine les résultats sans insight (IDs, horodatages qui révèlent le résultat), puis ré-exécutez.
- Nommez les résultats spécifiquement.
Cas Longsest meilleur queRésultat 1lorsque vous partagez les résultats avec des commanditaires ou les composez en rapports. - Associez au calculateur Arbre de Décision pour une seconde vue sur la même question. L'Arbre de Décision montre la structure de branchement ; l'Analyse Causale IA classe l'impact global des caractéristiques.
Calculateurs Associés
- Arbre de Décision - vue complémentaire montrant comment les attributs divisent les cas en groupes de résultats
- Analyse des Causes Profondes - découverte statistique déterministe des causes profondes pour les écarts de KPI
- Résultat du Cas par Catégorie - comparer les taux de résultats à travers un attribut catégoriel choisi
Fonctionnalités Associées
- AI Studio (Alpha) - l'espace de travail d'analytique prédictive plus large, incluant Feature Impact et Root Cause
- Aperçu des Fonctionnalités Alpha - liste complète des fonctionnalités du programme Alpha de mindzie
Donner votre avis
L'Analyse Causale IA est une fonctionnalité Alpha et votre avis façonne directement son évolution :
- Email : support@mindzie.com
- Objet : Inclure
Alpha Feedback: AI Causal Analysis - Inclure : la définition du résultat que vous avez utilisée, les colonnes d'entrée, ce que vous attendiez, et ce que vous avez obtenu