Architecture des Données
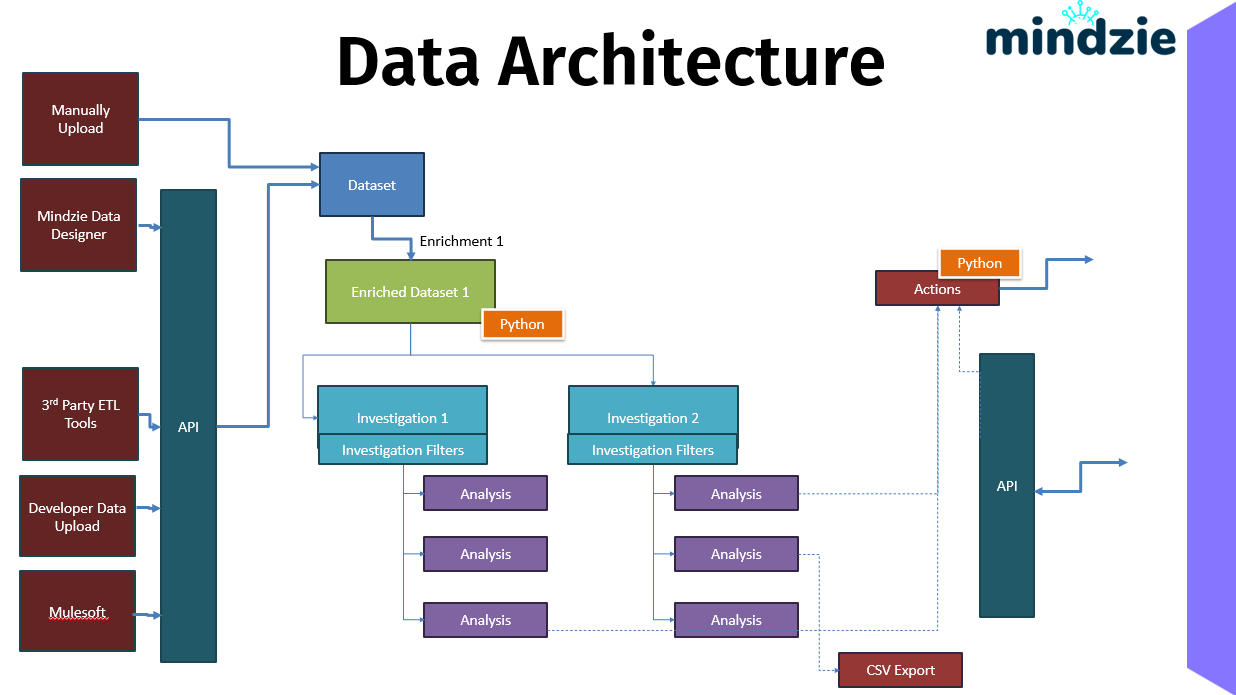
L'architecture des données montre comment les données de processus entrent dans mindzieStudio, sont transformées via l'enrichissement, et peuvent être exportées ou utilisées pour déclencher des actions automatisées. Comprendre ces flux de données vous aide à concevoir des stratégies d’intégration de données efficaces.
Vue d’ensemble
mindzieStudio prend en charge plusieurs méthodes d'entrée de données, une couche API centralisée, et diverses options de sortie. Cette architecture flexible vous permet d'intégrer le process mining dans votre écosystème de données existant.
Sources d’Entrée des Données
Il existe plusieurs façons d'importer des données de processus dans mindzieStudio :
Téléversement Manuel
La méthode la plus simple consiste à téléverser des fichiers directement via l’interface mindzieStudio. Les formats pris en charge incluent :
- Fichiers CSV : valeurs séparées par des virgules standard
- Fichiers Excel : feuilles de calcul .xlsx
- Fichiers Parquet : format de stockage en colonnes pour grands ensembles de données
- Archives ZIP : paquets compressés contenant plusieurs fichiers
Le téléversement manuel est idéal pour des analyses ponctuelles, des projets de preuve de concept, ou lorsque les données sont déjà exportées des systèmes sources.
mindzie Data Designer
mindzie Data Designer est un outil visuel qui se connecte directement à vos bases de données et systèmes sources. Il vous permet de :
- Définir les schémas de données visuellement
- Mapper les colonnes sources au format journal d’événements
- Planifier des rafraîchissements de données automatisés
- Transformer les données lors de l'extraction
Data Designer supporte les connexions aux principales bases de données dont SQL Server, Oracle, PostgreSQL, MySQL, SAP HANA, et bien d'autres.
Outils ETL Tiers
Si votre organisation dispose déjà d’une infrastructure ETL (Extract, Transform, Load), vous pouvez l’intégrer à mindzieStudio via des pipelines de données standards. Cette approche exploite vos capacités d’ingénierie des données et processus de gouvernance existants.
Téléversement de Données par Développeur
Pour un accès programmatique, l’API mindzieStudio permet aux développeurs de :
- Téléverser des ensembles de données via des points de terminaison HTTP
- Automatiser le rafraîchissement des données depuis des applications personnalisées
- S’intégrer avec des pipelines CI/CD
- Construire des connecteurs de données personnalisés
Cela convient parfaitement aux organisations construisant des pipelines de données automatisés ou intégrant le process mining dans des systèmes plus larges.
Intégration Mulesoft
Les organisations d’envergure utilisant Mulesoft pour l’intégration peuvent connecter mindzieStudio comme point de terminaison API dans leurs flux d’intégration. Cela permet aux données de processus de circuler dans le cadre de votre stratégie d’intégration d’entreprise globale.
API
L’API sert de passerelle centrale à tous les déplacements de données dans mindzieStudio. Toutes les données - qu’elles soient téléversées manuellement ou via automatisation - transitent par la couche API.
L’API offre :
- Authentification : accès sécurisé par jetons d’accès bearer
- Validation : validation du format et du schéma des données
- Routage : acheminement des données vers les composants de traitement appropriés
- Contrôle d’accès : permissions au niveau locataire et projet
L’API est disponible dans les éditions Enterprise Server et SaaS de mindzieStudio.
Dataset
Une fois les données entrées dans mindzieStudio, elles sont stockées sous forme de Dataset. Les Datasets sont :
- Compressés : format de stockage binaire efficace
- Validés : contrôlés pour les colonnes nécessaires et les types de données
- Versionnés : les versions précédentes peuvent être conservées pour comparaison
Chaque dataset doit inclure les trois colonnes principales du journal d'événements :
- Case ID (identifiant de chaque instance de processus)
- Activity (nom de chaque étape)
- Timestamp (moment auquel chaque étape s’est produite)
Les colonnes d’attributs supplémentaires peuvent contenir toutes les données métier pertinentes.
Enrichissement avec Python
La couche d’enrichissement transforme les datasets bruts en données prêtes pour l’analyse. Les enrichissements peuvent inclure :
- Opérateurs de transformation intégrés
- Scripts Python personnalisés pour une logique avancée
- Calculs de règles métier
- Corrections de qualité de données
L’intégration Python vous permet de :
- Écrire une logique de transformation personnalisée
- Exploiter les bibliothèques Python de data science
- Créer des scripts de transformation réutilisables
- Gérer des scénarios complexes de manipulation de données
Les enrichissements s’exécutent en arrière-plan et mettent en cache leurs résultats pour un accès rapide lors de l’analyse.
Investigation et Analyse
La couche Investigation est le lieu où l’analyse a lieu. Dans les investigations, vous pouvez :
- Appliquer des filtres d’investigation pour vous concentrer sur des sous-ensembles spécifiques de données
- Créer des carnets d’analyse composés de blocs ordonnés
- Générer des insights via des calculateurs
- Construire des visualisations
Les résultats d’analyse sont mis en cache et peuvent être actualisés lors de la mise à jour des données sources.
Sortie et Intégration
mindzieStudio propose plusieurs moyens d’exporter les données et de s’intégrer avec des systèmes externes :
Actions
Les Actions sont des workflows automatisés qui s’exécutent selon des horaires ou des déclencheurs. Les Actions peuvent :
- Exécuter des scripts Python pour un traitement personnalisé
- Appeler des APIs HTTP externes
- Exporter des données vers des systèmes externes
- Enchaîner plusieurs étapes
- Gérer les erreurs avec des actions de secours
Les Actions permettent une intégration opérationnelle, où les insights de processus déclenchent des réponses concrètes.
Export API
Les systèmes externes peuvent interroger mindzieStudio via l’API pour :
- Récupérer les résultats d’analyse de façon programmatique
- Extraire les données des tableaux de bord dans d’autres applications
- Intégrer les métriques de processus dans des systèmes de reporting
- Alimenter des tableaux de bord opérationnels dans des outils externes
Export CSV
Pour une exportation simple des données, vous pouvez télécharger les résultats d’analyse au format CSV. Cela est utile pour :
- Partager les données avec des parties prenantes sans accès à mindzieStudio
- Charger les données dans des outils de tableur
- Créer des copies de sauvegarde des résultats d’analyse
Résumé du Flux de Données
Le flux complet des données à travers mindzieStudio :
- Entrée : Les données arrivent via Téléversement Manuel, Data Designer, outils ETL, API ou Mulesoft
- Passerelle : L’API valide, authentifie et route les données
- Stockage : Les données sont stockées sous forme de Datasets compressés
- Transformation : Les enrichissements (avec Python en option) préparent les données
- Analyse : Les investigations et carnets génèrent des insights
- Sortie : Les résultats circulent vers les Actions, consommateurs API ou exports CSV
Cette architecture supporte à la fois l’analyse interactive et les workflows opérationnels automatisés, rendant mindzieStudio adapté aussi bien à l’exploration ponctuelle qu’à la surveillance des processus en production.