Análisis Causal IA (Alpha)
El calculador de Análisis Causal IA utiliza aprendizaje automático para descubrir qué atributos de caso impulsan con mayor fuerza un resultado objetivo. En lugar de mostrar únicamente correlación, aísla las características que tienen el mayor impacto estadístico sobre si un caso cumple el resultado que definas, de modo que puedes pasar de "qué está ocurriendo" a "por qué está ocurriendo".
Función Alpha: Este calculador forma parte del Programa Alpha de mindzie. Requiere que PreRelease esté habilitado para tu tenant. Consulta Funciones Alpha para más información.
Visión General
El Análisis Causal IA responde preguntas como:
- ¿Por qué algunos casos tardan más de 7 días en completarse?
- ¿Qué atributos hacen que una factura sea más propensa a pagarse tarde?
- ¿Qué distingue a los casos que incumplen el SLA de los que no?
- ¿Qué instalaciones, equipos o categorías de producto influyen más en un resultado dado?
Tú defines el resultado (los casos que quieres explicar), apuntas el calculador a un conjunto de columnas de entrada y este devuelve una lista clasificada de los factores más responsables de que esos casos caigan dentro del grupo de resultado.
Cómo se compara con el Análisis de Causa Raíz
El Análisis Causal IA comparte un objetivo con el calculador existente de Análisis de Causa Raíz, pero adopta un enfoque mucho más riguroso:
| Capacidad | Análisis de Causa Raíz | Análisis Causal IA |
|---|---|---|
| Encuentra impulsores de un solo atributo | Sí | Sí |
| Encuentra conjunciones de múltiples atributos (hasta 3 atributos por regla) | No | Sí |
| Distingue correlación de causalidad | No | Sí (grafo causal + ajuste por propensión) |
| Reporta intervalos de confianza | No | Sí (Wilson CI al 95% en cada regla) |
| Controla pruebas múltiples | No | Sí (FDR de Benjamini-Hochberg) |
| Maneja atributos numéricos / fecha / hora | No (solo cadenas) | Sí (binning consciente del resultado) |
| Narrativa en lenguaje natural por impulsor | No | Sí |
Usa el Análisis de Causa Raíz para un escaneo rápido de un solo atributo y el Análisis Causal IA para cualquier investigación seria, especialmente cuando alguien vaya a actuar sobre el resultado.
Cómo Añadir el Calculador
- Abre un cuaderno en mindzieStudio
- Haz clic en Añadir Calculador y selecciona Análisis Causal IA (Alpha)
- Configura el resultado y las columnas de entrada (ver abajo)
- Haz clic en Crear
Configuración
Título
El nombre visible del calculador. Por defecto es Análisis Causal IA (Alpha): cámbialo por algo específico a la pregunta que estás respondiendo, por ejemplo ¿Por qué las estancias en UCI son largas? o Impulsores del Pago Tardío.
Descripción
Notas opcionales en texto libre. Útil para documentar la pregunta de negocio, el rango de fechas sobre el que se ejecutó el análisis o la parte interesada que lo solicitó.
Definición del Resultado
El resultado es el grupo de casos que quieres explicar. El calculador compara estos casos con el resto del conjunto de datos e identifica qué columnas de entrada separan mejor los dos grupos.
Hay tres modos disponibles para definir el resultado:
Modo Filtro
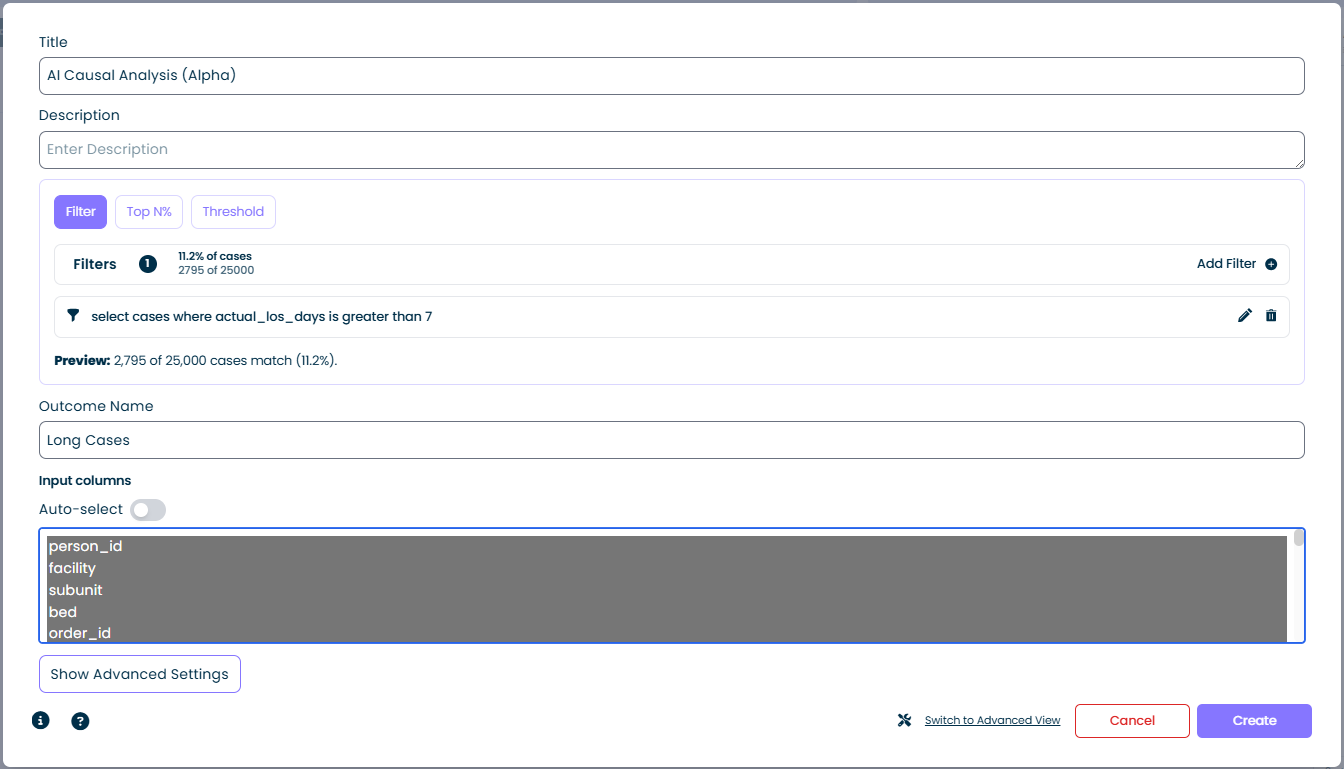
Selecciona la pestaña Filtro y añade una o más expresiones de filtro. El calculador trata los casos que coinciden con el filtro como el grupo de "resultado".
- Casos coincidentes: se muestran como un porcentaje y un conteo bruto, por ejemplo
11,2% de casos / 2.795 de 25.000 - Añadir Filtro: abre el constructor de filtros estándar; combina cualquier número de condiciones
- Vista previa: se actualiza en vivo a medida que construyes el filtro para que puedas validar la selección antes de ejecutar el calculador
El modo Filtro es la opción más flexible. Cualquier condición que puedas expresar como un filtro de mindzie (umbrales de duración, coincidencias de atributos, presencia de actividades, etc.) puede convertirse en un resultado. En la captura de pantalla anterior, el filtro seleccionar casos donde actual_los_days es mayor que 7 define "Casos Largos" como el resultado.
Modo Top N%
Selecciona la pestaña Top N% para usar los valores más altos (o más bajos) de un atributo numérico como resultado. Es útil cuando quieres explicar "los peores casos" o "los mejores desempeños" sin tener que elegir un umbral fijo. Ejemplo: el 10% superior de casos por tiempo de ciclo.
Modo Umbral
Selecciona la pestaña Umbral para definir el resultado con un único punto de corte numérico sobre un atributo. Cualquier caso por encima (o por debajo) del valor pasa a formar parte del grupo de resultado. Ejemplo: casos donde invoice_amount supera 50.000.
Nombre del Resultado
Una etiqueta corta que identifica al grupo de resultado en los resultados, por ejemplo Casos Largos, Pagos Tardíos o Incumplimiento de SLA. Este nombre aparece en toda la salida del análisis donde se haga referencia al grupo de resultado.
Columnas de Entrada
Las columnas que el modelo puede utilizar al buscar impulsores del resultado.
- Lista de columnas: se muestra cada atributo de caso del conjunto de datos. Selecciona una o más para incluirlas en el análisis. Las columnas se resaltan al seleccionarlas.
- Interruptor Auto-selección: cuando está habilitado, mindzie elige automáticamente un conjunto por defecto razonable de columnas de entrada basado en el esquema del conjunto de datos. Desactívalo cuando quieras control manual total, por ejemplo para excluir una columna que esté trivialmente correlacionada con el resultado (como un ID que filtre la respuesta).
Consejos para elegir columnas de entrada:
- Excluye columnas que sean aguas abajo del resultado. Si
discharge_datese usa para calcularactual_los_days, dominará los resultados sin aportar información. - Excluye identificadores de alta cardinalidad (
person_id,order_id) a menos que busques específicamente efectos por entidad. - Incluye atributos contextuales (instalación, categoría de producto, prioridad, región): ahí suelen estar los impulsores interesantes.
Mostrar Ajustes Avanzados
Abre opciones adicionales de ajuste para la búsqueda. Los valores por defecto funcionan bien para la mayoría de análisis: solo cámbialos cuando tengas una razón específica.
| Ajuste | Por defecto | Propósito |
|---|---|---|
| Beam width | 50 | Cuántas reglas candidatas se conservan en cada profundidad de búsqueda. Mayor = más exhaustivo, más lento. |
| Profundidad máxima de regla | 3 | Regla más larga permitida. 3 significa reglas de la forma A Y B Y C. |
| Mínimo de casos por regla | 30 | Las reglas que afectarían a menos casos que este valor se descartan por ser demasiado pequeñas para ser accionables. |
| Lift mínimo | 1.2 | La tasa de resultado dentro de la regla debe superar la línea base al menos por este factor (1.2 = al menos 20% por encima de la línea base). |
| Alfa FDR | 0.05 | Umbral de significancia Benjamini-Hochberg para controlar los descubrimientos falsos en la búsqueda de reglas. |
| Máximo de impulsores devueltos | 20 | Límite superior del número de reglas mostradas en la vista de tabla completa. |
| Jaccard de redundancia | 0.9 | Las reglas cuyos conjuntos de casos se solapan más que esta fracción se tratan como duplicadas y se filtran. |
| Umbral de muestreo | 2.000.000 de casos | Los conjuntos de datos por encima de este tamaño se muestrean de forma determinista usando el algoritmo de combinación de Floyd. La salida reporta WasSampled = true y el tamaño real de la muestra. |
Cambiar a Vista Avanzada
Cambia el editor al modo avanzado para un control detallado sobre cada parámetro del modelo. La vista guiada que se muestra aquí es suficiente para la gran mayoría de los casos de uso.
Flujo de Trabajo Típico
- Plantea la pregunta: decide qué resultado quieres explicar. "¿Qué hace que los casos sean lentos?" se convierte en un resultado de Filtro
case_duration > 7 días. - Define el resultado: usa el modo Filtro, Top N% o Umbral. Verifica que el porcentaje de Vista previa parece razonable (muy pocos casos producirán resultados inestables; demasiados significan que el resultado no es realmente distintivo).
- Nombra el resultado: elige una etiqueta concisa que se lea bien en los resultados y en los informes.
- Selecciona columnas de entrada: empieza con Auto-selección y luego recorta cualquier columna que filtre la respuesta o añada ruido.
- Crear: ejecuta el calculador. El resultado muestra los impulsores clasificados del resultado.
- Interpreta: revisa los principales impulsores, refina el resultado o el conjunto de entradas si es necesario y vuelve a ejecutar.
Ejemplo
Un equipo de operaciones hospitalarias quiere entender por qué algunas estancias hospitalarias superan los 7 días.
| Ajuste | Valor |
|---|---|
| Título | Análisis Causal IA (Alpha) |
| Modo Filtro | seleccionar casos donde actual_los_days es mayor que 7 |
| Vista previa | 2.795 de 25.000 casos coinciden (11,2%) |
| Nombre del Resultado | Casos Largos |
| Columnas de entrada | facility, subunit, bed, order_id, ... (auto-seleccionadas) |
Después de ejecutarse, el calculador reporta qué combinaciones de instalación, sub-unidad y atributos de cuidado distinguen con mayor fuerza los casos de estancia larga de los casos de estancia normal. Esto orienta al equipo hacia unidades y flujos de trabajo específicos a investigar, en lugar de dejarles explorar cada atributo manualmente.
Interpretación de los Resultados
Para cada impulsor principal, el calculador produce un párrafo narrativo en lenguaje natural y una insignia de evidencia que describe la fuerza del hallazgo:
| Insignia | Significado | Cómo actuar |
|---|---|---|
| Causal | Tanto la señal del grafo causal como el efecto ajustado por confundidores son positivos. | Evidencia accionable más fuerte; seguro para priorizar la intervención. |
| Probablemente Causal | El grafo causal conecta la regla con el resultado, pero el efecto se debilita una vez que ajustamos por confundidores. | Prometedor; investiga más antes de actuar. |
| Asociado | El efecto sobrevive al ajuste, pero el grafo no sitúa la regla en una ruta directa al resultado. | Asociación real, pero probablemente indirecta; puede ser un proxy del verdadero impulsor. |
| Correlacional | Hay una asociación, pero no podemos confirmar una relación causal. | Señal solo diagnóstica; no actúes basándote únicamente en ella. |
Ejemplo de narrativa para una regla Causal:
Channel = Online es un impulsor probable de Non-First Contact Resolution. Los casos que coinciden con esta regla muestran una tasa de resultado del 46,1% frente a la línea base del 29,0% (1,59x, IC 95% 1,51x - 1,68x, p < 0,001). Cubre 2.518 casos, lo que representa el 34,7% de todas las ocurrencias de Non-First Contact Resolution. El efecto sobrevivió al ajuste por otros impulsores principales y se sitúa en una ruta directa al resultado en el grafo causal aprendido.
La vista de Tabla Completa añade la lista clasificada completa con cobertura, lift, intervalo de confianza, efecto ajustado, p-valor e insignia para cada regla que sobrevivió a la búsqueda y al filtro de significancia.
Cómo Funciona el Algoritmo
El Análisis Causal IA ejecuta una tubería de cinco etapas. Cada etapa tiene una función específica y está diseñada para que todo el proceso termine en segundos, incluso en conjuntos de datos de un millón de casos.
1. Preparación y binning
- El calculador toma los casos de tu grupo de resultado y los etiqueta como
1; todos los demás se etiquetan como0. Esta es la tasa base que ves en la salida. - Los atributos categóricos (cadenas, booleanos, enteros de baja cardinalidad) se utilizan directamente. Cada valor distinto se convierte en un literal candidato (p. ej.,
facility = Memorial). - Los atributos numéricos y de fecha/hora se binan con un binner óptimo MDL, consciente del resultado. En lugar de elegir bins de igual anchura o igual frecuencia, el binner elige puntos de corte que separan mejor los casos con resultado de los que no lo tienen, y luego usa el principio de Longitud Mínima de Descripción (MDL) para elegir automáticamente el número de bins. Esto convierte una columna numérica como
actual_los_daysen un pequeño conjunto de cubos significativos (p. ej.,<= 3 días,4 - 7 días,> 7 días).
2. Indexación por bitmaps
Cada literal se almacena como un bitset: un bit por caso, 1 si el caso coincide con el literal. Combinar literales con Y se convierte en una rápida intersección bit a bit:
facility = Memorial Y priority = Highse calcula comobitset_A & bitset_B.- La cobertura, el conteo de resultados y el lift de una regla candidata pueden evaluarse en microsegundos, independientemente de la profundidad de la regla.
Los literales que cubren menos del Mínimo de casos por regla se descartan antes de que comience la búsqueda.
3. Descubrimiento de subgrupos por beam search
El calculador recorre el espacio de reglas en anchura:
- Profundidad 1: evalúa cada literal individual. Puntúa cada uno usando una medida de calidad (lift y Weighted Relative Accuracy) y conserva los mejores según el
Beam width(por defecto 50). - Profundidad 2: extiende cada regla conservada con cada literal compatible adicional para formar conjunciones como
A Y B. Las puntúa todas y conserva de nuevo los mejores según elBeam width. - Profundidad 3: repite una vez más. Se detiene en la Profundidad máxima de regla.
Las reglas que caen por debajo del Lift mínimo o del Mínimo de casos por regla se podan en cada nivel.
Después de la búsqueda, un filtro de redundancia Jaccard elimina las reglas casi duplicadas: si dos reglas cubren esencialmente los mismos casos (solapamiento por encima del Jaccard de redundancia, por defecto 0.9), solo se conserva la mejor.
4. Significancia estadística
Para cada regla superviviente, el calculador calcula:
- El cociente de riesgo (tasa de resultado dentro de la regla dividida por la tasa base) y su intervalo de confianza Wilson al 95%, que se comporta bien para probabilidades pequeñas y extremas donde la aproximación normal falla.
- Un p-valor bajo la hipótesis nula de que la regla no tiene efecto.
- Una corrección FDR de Benjamini-Hochberg sobre todas las reglas probadas. El Alfa FDR (por defecto 0.05) fija la tasa esperada de falsos descubrimientos. Las reglas que no sobreviven al FDR no se reportan, lo que evita que la búsqueda te ahogue en hallazgos espurios.
5. Adjudicación causal
La significancia por sí sola solo indica que hay una asociación. Dos señales adicionales deciden si una regla obtiene una insignia Causal:
- Señal de grafo causal: una puntuación estructural bayesiana ligera aprendida a partir de los atributos y el resultado. Se pregunta: ¿está esta regla en una ruta directa al resultado en el grafo aprendido, o solo en una ruta indirecta a través de un confundidor?
- Ajuste por puntuación de propensión: una regresión logística regularizada con ridge modela la probabilidad de que cada caso coincida con la regla, dados todos los demás impulsores principales. Entonces se reestima el efecto de la regla tras ponderar por esa propensión. Si el efecto se reduce a cero, la regla era solo un proxy de otros impulsores; si persiste, tiene poder explicativo independiente.
El adjudicador combina ambas señales en las cuatro insignias de evidencia definidas anteriormente.
6. Generación narrativa
El paso final compone el párrafo en lenguaje natural que se muestra en la vista de tarjeta. Entrelaza la definición de la regla, las tasas de resultado dentro de la regla y de línea base, el cociente de riesgo y el intervalo de confianza, el p-valor, la cobertura y la insignia de evidencia en una estructura de frase ajustada para leerse de forma natural por un lector no estadístico.
Rendimiento
Medido en una máquina de desarrollo:
| Conjunto de datos | Tiempo |
|---|---|
| 100.000 casos x 4 columnas | menos de 1 segundo |
| 200.000 casos x 20 columnas | menos de 2 segundos |
| 1.000.000 casos x 50 columnas | alrededor de 3 segundos |
Los conjuntos de datos por encima del umbral de muestreo (por defecto 2.000.000 de casos) se muestrean de forma determinista usando el algoritmo de combinación de Floyd. Cuando esto ocurre, la salida marca WasSampled = true y reporta el tamaño real de la muestra para que el resultado sea reproducible y el muestreo sea visible.
Limitaciones Conocidas (v1)
- Solo resultados binarios. Los resultados multi-clase (rápido / medio / lento, por ejemplo) no están soportados en esta versión. Define divisiones de dos vías como análisis separados.
- Aún no hay explicaciones por caso. La v1 responde "¿qué impulsa este resultado en todo el conjunto de datos?" Una versión futura añadirá paneles de "¿por qué este caso específico salió mal?".
- Sin análisis de deriva temporal. Si los impulsores cambian entre trimestres, la v1 no los dividirá en el tiempo. Ejecuta el calculador por separado en cada segmento temporal cuando eso importe.
- El binning numérico es consciente del resultado. Si quieres bins fijos elegidos por un humano, pre-segmenta la columna con un enriquecimiento antes de ejecutar el calculador.
Casos de Uso
Impulsores de Rendimiento
Identifica los atributos más asociados con casos que incumplen el SLA, exceden el presupuesto o superan su duración esperada. Funciona bien con un resultado de Filtro construido sobre un enriquecimiento de duración o KPI.
Análisis de Resultados
Compara casos exitosos con casos fallidos o cancelados. Usa un resultado de Filtro sobre un atributo de estado o resultado para ver qué atributos anteriores predicen cada resultado.
Riesgo y Cumplimiento
Apunta el calculador a casos marcados por un enriquecimiento de conformidad o control para aprender qué factores contextuales se correlacionan con fallos de cumplimiento.
Análisis de Mejores Desempeños
Usa el modo Top N% para explicar qué hace diferentes a tus mejores casos, equipos o clientes del resto. Retroalimenta los hallazgos al diseño del proceso o a la formación.
Consejos
- Empieza simple. Un Filtro bien elegido con dos o tres condiciones más las entradas auto-seleccionadas suele producir los resultados más claros.
- Vigila el porcentaje de la vista previa. Si el grupo de resultado es menos del ~2% o más del ~50% del conjunto de datos, el análisis se vuelve más difícil de interpretar. Ajusta el filtro hasta que el grupo sea una minoría significativa.
- Itera sobre las columnas de entrada. Elimina las columnas cuya presencia domine los resultados sin aportar información (IDs, marcas temporales que filtren el resultado) y vuelve a ejecutar.
- Nombra los resultados de forma específica.
Casos Largoses mejor queResultado 1cuando compartas resultados con partes interesadas o los uses en informes. - Combínalo con el calculador de Árbol de Decisiones para obtener una segunda visión sobre la misma pregunta. El Árbol de Decisiones muestra la estructura de ramificación; el Análisis Causal IA clasifica el impacto global de las características.
Calculadores Relacionados
- Árbol de Decisiones - vista complementaria que muestra cómo los atributos dividen los casos en grupos de resultado
- Análisis de Causa Raíz - descubrimiento determinista estadístico de causa raíz para desviaciones de KPI
- Resultado del Caso Por Categoría - compara tasas de resultado a través de un atributo categórico elegido
Funciones Relacionadas
- AI Studio (Alpha) - el espacio de trabajo de análisis predictivo más amplio, incluyendo Feature Impact y Root Cause
- Visión General de Funciones Alpha - lista completa de funciones en el Programa Alpha de mindzie
Envío de Comentarios
El Análisis Causal IA es una función Alpha y tus aportes dan forma directamente a cómo evoluciona:
- Correo electrónico: support@mindzie.com
- Asunto: Incluye
Alpha Feedback: AI Causal Analysis - Incluye: la definición de resultado que utilizaste, las columnas de entrada, lo que esperabas y lo que obtuviste