Arquitectura de Datos
La arquitectura de datos muestra cómo los datos del proceso fluyen hacia mindzieStudio, se transforman mediante enriquecimiento y pueden ser exportados o usados para desencadenar acciones automatizadas. Comprender estos flujos de datos te ayuda a diseñar estrategias de integración de datos efectivas.
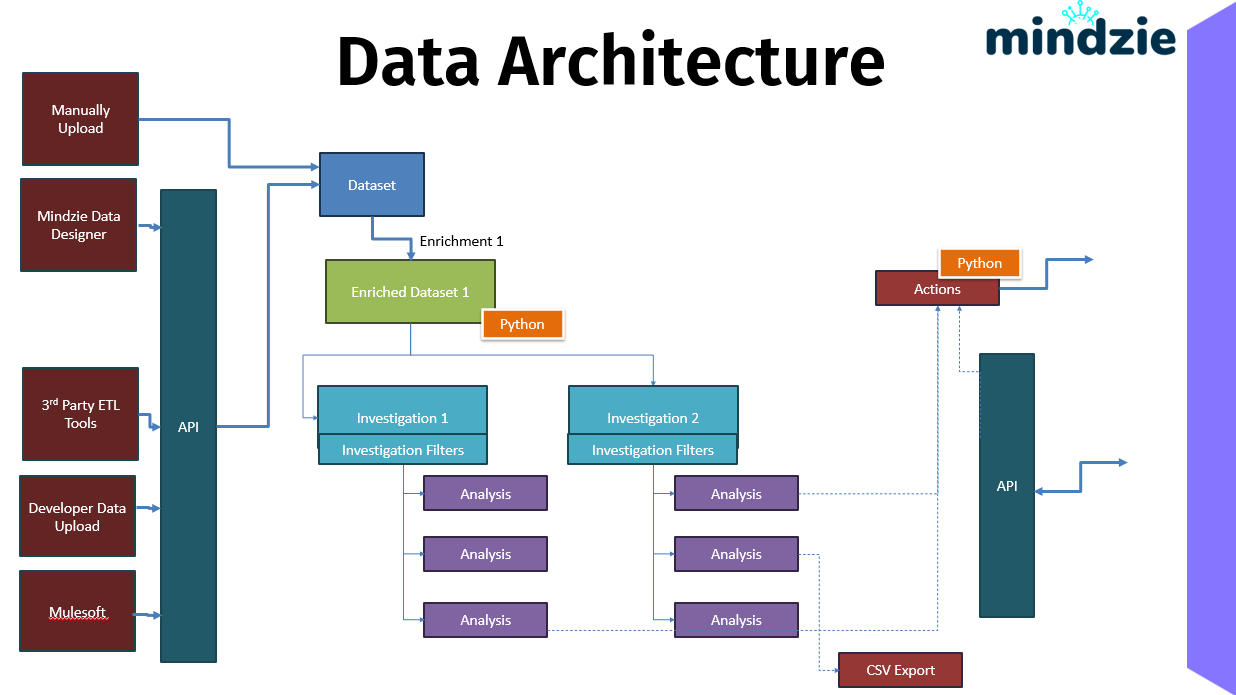
Visión General
mindzieStudio soporta múltiples métodos de entrada de datos, una capa centralizada de API y varias opciones de salida. Esta arquitectura flexible te permite integrar la minería de procesos en tu ecosistema de datos existente.
Fuentes de Entrada de Datos
Existen varias maneras de ingresar datos de procesos a mindzieStudio:
Carga Manual
El enfoque más simple es cargar archivos directamente a través de la interfaz de mindzieStudio. Los formatos soportados incluyen:
- Archivos CSV: Valores separados por comas estándar
- Archivos Excel: Hojas de cálculo .xlsx
- Archivos Parquet: Formato de almacenamiento columnar para grandes conjuntos de datos
- Archivos ZIP: Paquetes comprimidos que contienen múltiples archivos
La carga manual es ideal para análisis ad hoc, proyectos de prueba de concepto o cuando los datos ya han sido exportados desde los sistemas fuente.
mindzie Data Designer
mindzie Data Designer es una herramienta visual que se conecta directamente a tus bases de datos y sistemas fuente. Permite:
- Definir esquemas de datos visualmente
- Mapear columnas fuente al formato de registro de eventos
- Programar actualizaciones automáticas de datos
- Transformar datos durante la extracción
Data Designer soporta conexiones a bases de datos principales como SQL Server, Oracle, PostgreSQL, MySQL, SAP HANA, y muchas otras.
Herramientas ETL de Terceros
Si tu organización ya cuenta con infraestructura ETL (Extraer, Transformar y Cargar), puedes integrarla con mindzieStudio mediante pipelines de datos estándar. Este enfoque aprovecha las capacidades existentes de ingeniería de datos y los procesos de gobernanza.
Carga de Datos para Desarrolladores
Para acceso programático, la API de mindzieStudio permite a los desarrolladores:
- Cargar conjuntos de datos vía endpoints HTTP
- Automatizar la actualización de datos desde aplicaciones personalizadas
- Integrar con pipelines CI/CD
- Construir conectores de datos personalizados
Esto es ideal para organizaciones que desarrollan pipelines de datos automatizados o integran minería de procesos en sistemas más grandes.
Integración con Mulesoft
Las organizaciones empresariales que usan Mulesoft para integración pueden conectar mindzieStudio como un endpoint de API en sus flujos de integración. Esto permite que los datos del proceso fluyan como parte de la estrategia integral de integración empresarial.
API
La API sirve como puerta central para todo el movimiento de datos en mindzieStudio. Todos los datos —ya sea que se suban manualmente o mediante automatización— fluyen a través de la capa de API.
La API proporciona:
- Autenticación: Acceso seguro mediante tokens bearer
- Validación: Validación de formato y esquema de datos
- Enrutamiento: Direccionamiento de datos hacia los componentes de procesamiento adecuados
- Control de Acceso: Permisos a nivel de tenant y proyecto
La API está disponible en ediciones Enterprise Server y SaaS de mindzieStudio.
Conjunto de Datos
Una vez que los datos ingresan a mindzieStudio, se almacenan como un Conjunto de Datos. Los conjuntos de datos son:
- Comprimidos: Formato binario eficiente para almacenamiento
- Validados: Verificados para columnas requeridas y tipos de datos
- Versionados: Se pueden conservar cargas previas para comparación
Cada conjunto de datos debe incluir las tres columnas principales del registro de eventos:
- Case ID (identificador para cada instancia del proceso)
- Activity (nombre de cada paso)
- Timestamp (cuándo ocurrió cada paso)
Las columnas de atributos adicionales pueden incluir cualquier dato relevante para el negocio.
Enriquecimiento con Python
La capa de enriquecimiento transforma conjuntos de datos sin procesar en datos listos para análisis. Los enriquecimientos pueden incluir:
- Operadores de transformación integrados
- Scripts personalizados en Python para lógica avanzada
- Cálculos de reglas de negocio
- Correcciones de calidad de datos
La Integración con Python te permite:
- Escribir lógica de transformación personalizada
- Aprovechar librerías de ciencia de datos de Python
- Crear scripts de transformación reutilizables
- Manejar escenarios complejos de manipulación de datos
Los enriquecimientos se ejecutan en segundo plano y almacenan en caché sus resultados para acceso rápido durante el análisis.
Investigación y Análisis
La capa de Investigación es donde ocurre el análisis. Dentro de las investigaciones, puedes:
- Aplicar filtros de investigación para enfocarte en subconjuntos específicos de datos
- Crear notebooks de análisis con bloques ordenados
- Generar insights mediante calculadoras
- Construir visualizaciones
Los resultados del análisis se almacenan en caché y pueden actualizarse cuando los datos fuente cambian.
Salida e Integración
mindzieStudio ofrece múltiples formas para exportar datos e integrarse con sistemas externos:
Acciones
Las Acciones son flujos de trabajo automatizados que se ejecutan según horarios o disparadores. Las acciones pueden:
- Ejecutar scripts Python para procesamiento personalizado
- Llamar APIs HTTP externas
- Exportar datos a sistemas externos
- Encadenar múltiples pasos consecutivos
- Manejar errores con acciones de respaldo
Las acciones permiten integración operativa, donde los insights de procesos desencadenan respuestas en el mundo real.
Exportación por API
Los sistemas externos pueden consultar mindzieStudio vía API para:
- Recuperar resultados de análisis programáticamente
- Extraer datos de dashboards hacia otras aplicaciones
- Integrar métricas de procesos en sistemas de reportes
- Alimentar dashboards operacionales en herramientas externas
Exportación CSV
Para exportaciones sencillas, puedes descargar resultados de análisis en archivos CSV. Esto es útil para:
- Compartir datos con interesados que no tienen acceso a mindzieStudio
- Cargar datos en herramientas de hojas de cálculo
- Crear copias de seguridad de resultados de análisis
Resumen del Flujo de Datos
El flujo completo de datos a través de mindzieStudio:
- Entrada: Los datos ingresan vía Carga Manual, Data Designer, herramientas ETL, API o Mulesoft
- Puerta de Entrada: La API valida, autentica y enruta los datos
- Almacenamiento: Los datos se almacenan como Conjuntos de Datos comprimidos
- Transformación: Los enriquecimientos (con Python opcional) preparan los datos
- Análisis: Investigaciones y notebooks generan insights
- Salida: Los resultados fluyen hacia Acciones, consumidores de API o exportaciones CSV
Esta arquitectura soporta tanto análisis interactivo como flujos de trabajo operativos automatizados, haciendo a mindzieStudio adecuado para exploración ad hoc y monitoreo de procesos en producción.