Verständnis der Dual-Dataset-Architektur von mindzie
Übersicht
Wenn Sie Daten in mindzie Studio hochladen, erstellt die Plattform automatisch zwei separate Datensätze, die zusammenarbeiten, um Ihre Process Mining-Analyse zu ermöglichen. Das Verständnis der Unterschiede zwischen diesen Datensätzen und wann welcher verwendet werden sollte, ist grundlegend für eine effektive Arbeit mit mindzie Studio.
Diese Anleitung erklärt die Dual-Dataset-Architektur, wie die mindzie-Datenpipeline Ihre Daten transformiert und was automatisch passiert, wenn Sie Daten zum ersten Mal importieren.
Die beiden Datensätze
Originaldatensatz
Der Originaldatensatz ist das rohe Ereignisprotokoll, das Sie zunächst in mindzie Studio hochladen. Dieser Datensatz enthält Ihre Prozessdaten genau so, wie sie bereitgestellt wurden, unabhängig davon, ob sie per CSV-Datei hochgeladen oder über mindzie Data Designer aus Quellsystemen eingelesen wurden.
Eigenschaften:
- Enthält die Rohdaten in ihrer ursprünglichen Form
- Beinhaltet nur die importierten Spalten und Attribute (Case ID, Aktivität, Zeitstempel, Ressource und weitere Attribute)
- Bleibt während Ihrer Analyse unverändert
- Bildet die Grundlage für alle weiteren Datenverarbeitungen
Wann der Originaldatensatz verwendet wird:
- Wenn Sie die Quelldaten verifizieren müssen
- Für Datenqualitätsprüfungen und Validierungen
- Um zu verstehen, was ursprünglich bereitgestellt wurde, bevor Transformationen erfolgen
Angereicherter Datensatz
Der Angereicherte Datensatz wird automatisch von mindzie Studio nach Ausführung der Datenpipeline erstellt. Dies ist die erweiterte Version Ihrer Daten, die alle berechneten Attribute, Performance-Kennzahlen, Konformitätskennzeichen und weitere Anreicherungen enthält, die durch die Log-Enrichment-Engine hinzugefügt wurden.
Eigenschaften:
- Wird automatisch beim Datenimport erstellt
- Beinhaltet alle Originalattribute plus neue berechnete Attribute
- Wird aktualisiert, wann immer Sie Anreicherungsberechnungen durchführen
- Steuert alle Analysen, Untersuchungen und Dashboards
Wann der angereicherte Datensatz verwendet wird:
- Für alle Analyse- und Untersuchungsarbeiten (dies ist der primäre Datensatz für die Analyse)
- Beim Erstellen von Dashboards und KPIs
- Bei der Arbeit mit Leistungskennzahlen, Konformitätsregeln oder benutzerdefinierten Anreicherungen
- Für die tägliche Process Mining-Arbeit
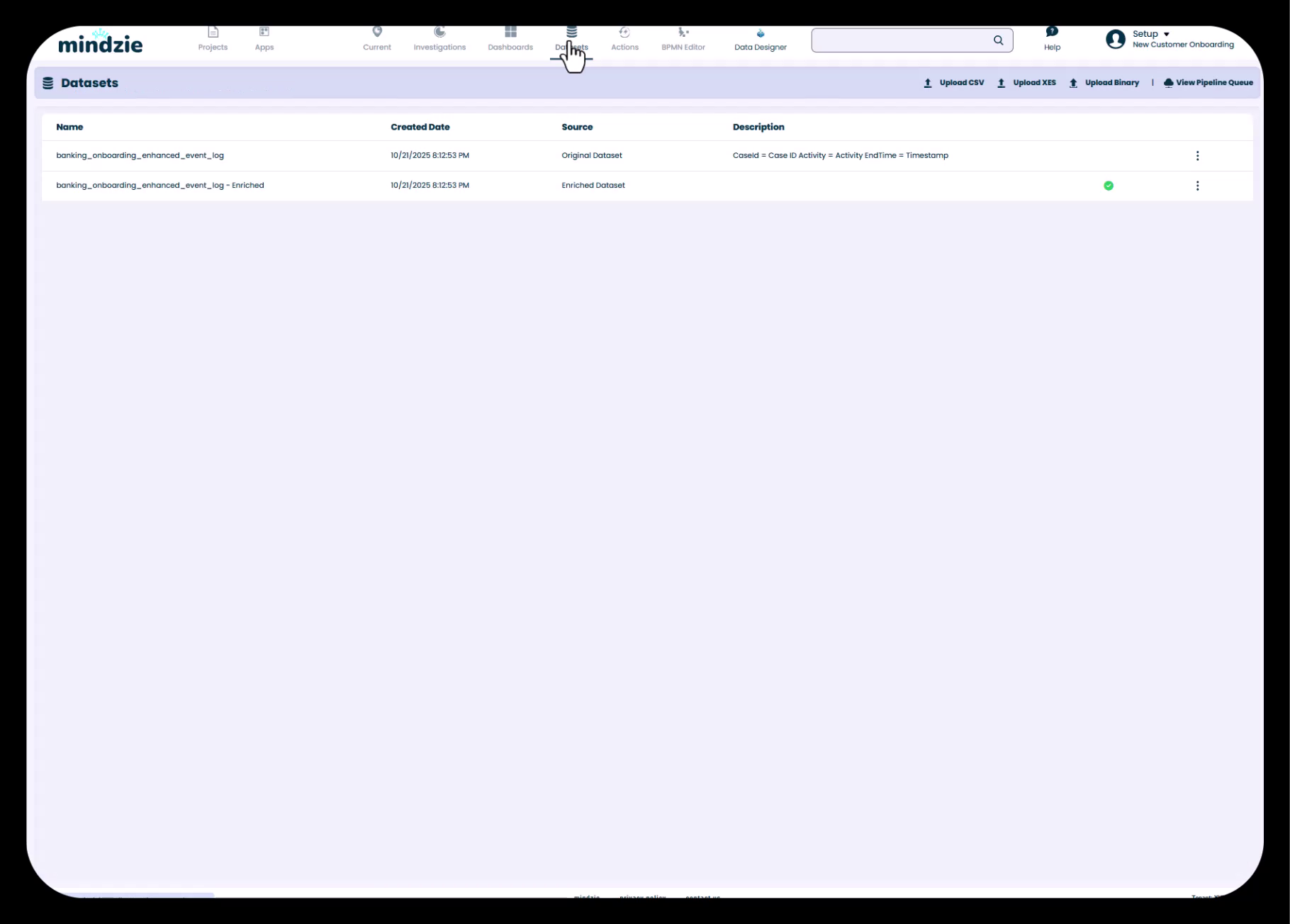 Die Datensatzansicht zeigt sowohl den Originaldatensatz als auch den angereicherten Datensatz
Die Datensatzansicht zeigt sowohl den Originaldatensatz als auch den angereicherten Datensatz
Wie die Datenpipeline funktioniert
Wenn Sie Daten in mindzie Studio hochladen, passiert automatisch Folgendes:
Schritt 1: Datenimport und Validierung
Ihre CSV-Datei oder Daten aus mindzie Data Designer werden in mindzie Studio geladen. Das System:
- Validiert das Datenformat und die Struktur
- Ordnet Schlüsselspalten zu (Case ID, Aktivität, Zeitstempel, Ressource)
- Weist Spaltentypen und Datentypen zu
- Erstellt den Originaldatensatz
Schritt 2: Automatische Pipeline-Ausführung
Sobald Sie nach dem Hochladen der Daten auf „Speichern“ klicken, führt mindzie Studio automatisch aus:
- Die Datenpipeline
- Erstellt den angereicherten Datensatz
- Fügt grundlegende Attribute hinzu, die Ihre Analysefähigkeiten erweitern
Schritt 3: Standard-Analyseerstellung
Um Ihnen einen schnellen Einstieg zu ermöglichen, generiert mindzie Studio automatisch hilfreiche Standardanalysen, darunter:
- Prozessübersicht
- Lange Falldauern
- Dauern zwischen wichtigen Prozessschritten
- Weitere zentrale Einblicke
Diese vorgefertigten Analysen helfen Ihnen, Ihren Prozess sofort zu erkunden, ohne alles von Grund auf neu erstellen zu müssen.
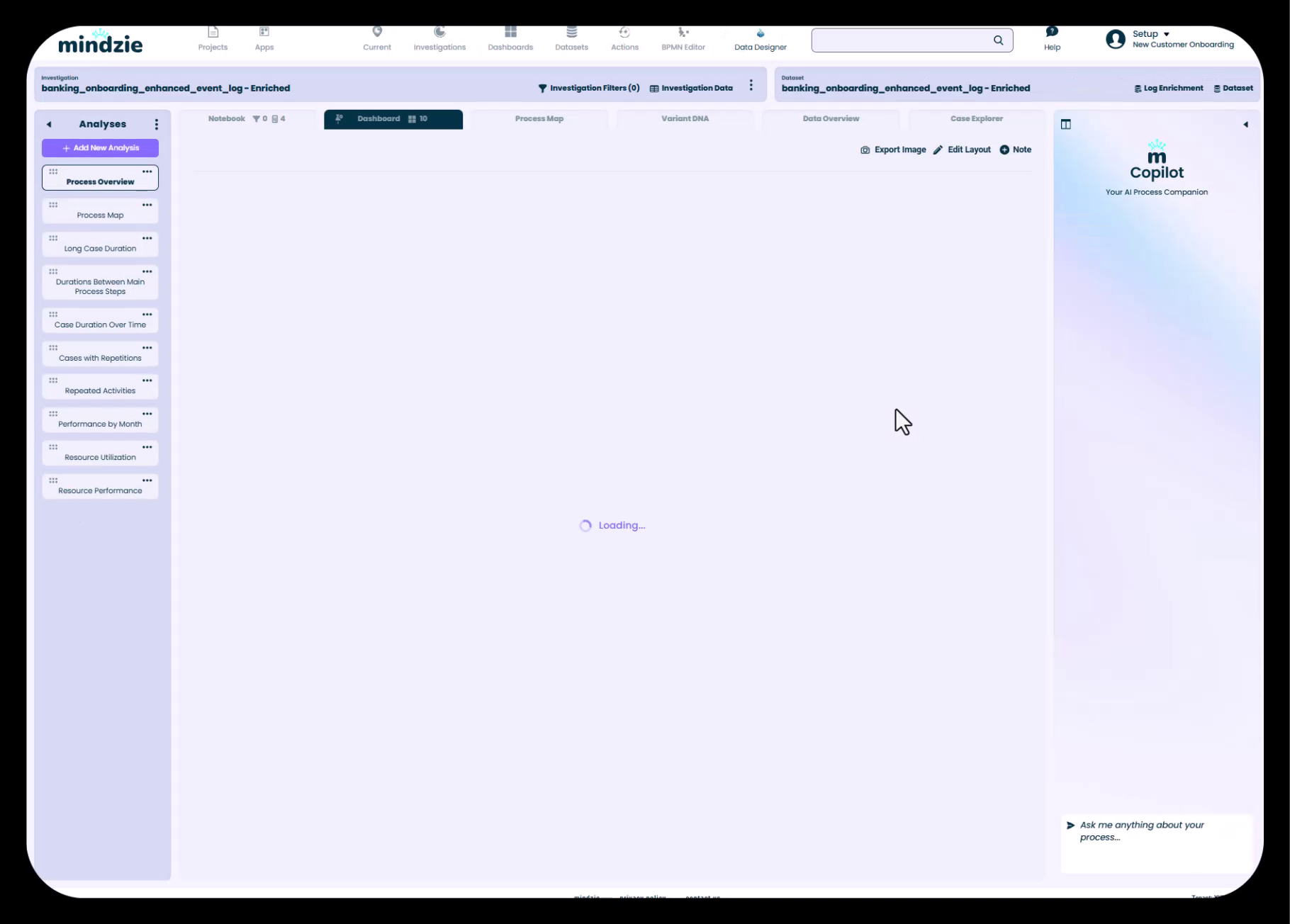 Automatisch erstellte Standarduntersuchung nach Datenimport
Automatisch erstellte Standarduntersuchung nach Datenimport
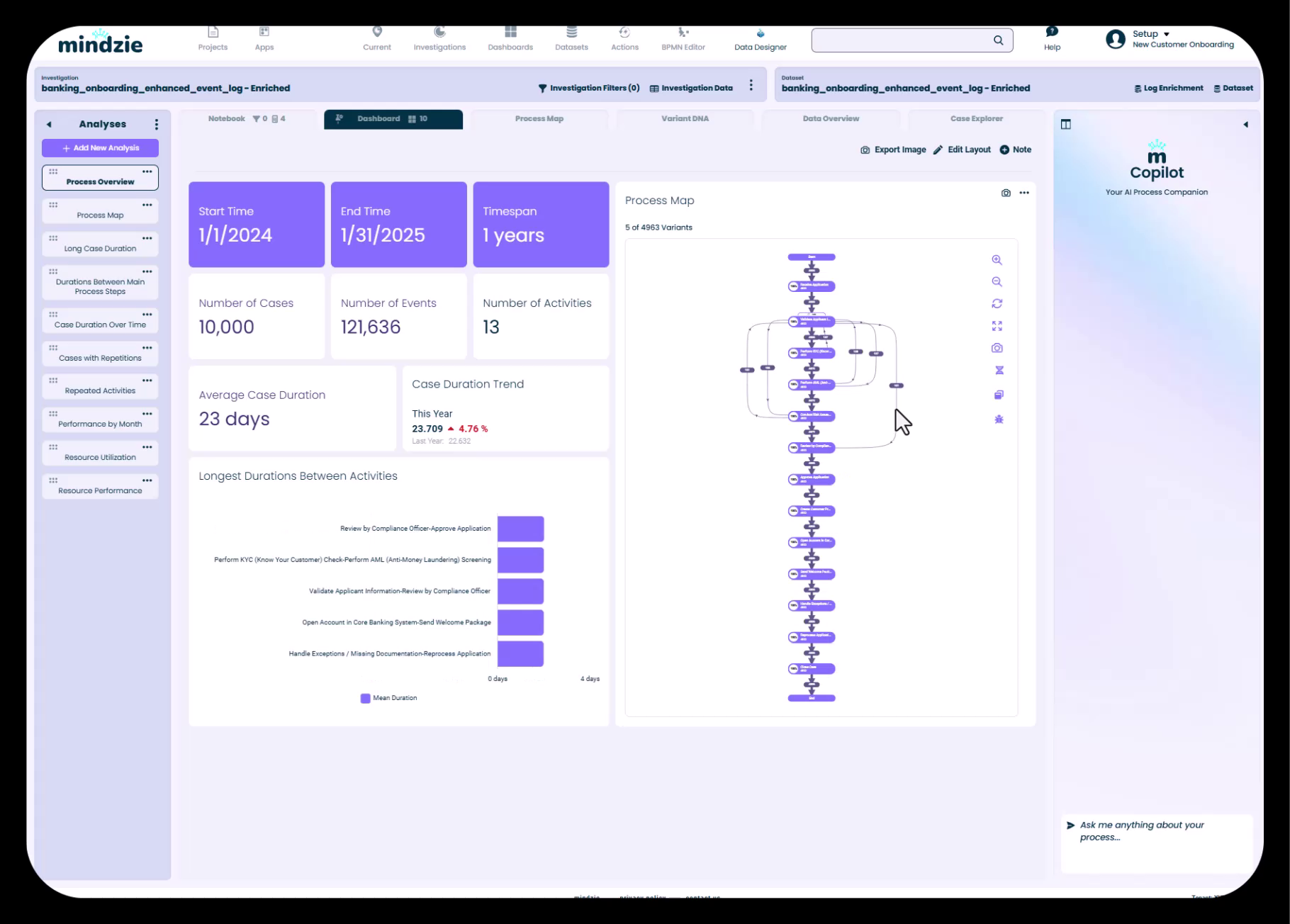 Standardanalyse mit 10.000 Fällen und 121.000 Ereignissen mit wichtigen Prozesseinblicken
Standardanalyse mit 10.000 Fällen und 121.000 Ereignissen mit wichtigen Prozesseinblicken
Verständnis der Datensatzgröße: Das Beispiel
Im Demo-Datensatz zur Bankkunden-Onboarding enthält:
- 10.000 Fälle – Jeder Fall repräsentiert eine Kunden-Onboarding-Reise
- 121.000 Ereignisse – Die Gesamtzahl der Prozessschritte über alle Fälle hinweg
Das bedeutet, dass jeder Kunden-Onboarding-Fall im Durchschnitt ungefähr 12 Aktivitäten oder Prozessschritte umfasst. Diese Art von Informationen wird sofort sichtbar, sobald Ihre Daten in mindzie Studio geladen sind.
Die Rolle der Log-Enrichment
Die Stärke der Dual-Dataset-Architektur wird deutlich, wenn Sie die Log-Enrichment-Engine nutzen. Hier differenziert sich der angereicherte Datensatz wirklich vom Originaldatensatz.
Was Log-Enrichment bewirkt
Log-Enrichment ermöglicht es Ihnen, Ihre Daten zu erweitern mit:
Leistungskennzahlen:
- Dauerberechnungen zwischen Aktivitätspaaren
- Falldauer von Anfang bis Ende
- Performance-Einteilung (schnell, normal, langsam)
- Benutzerdefinierte SLA-Compliance-Verfolgung
Konformitätsregeln:
- Kennzeichen für unerwünschte Aktivitäten
- Fehlende Pflichtschritte
- Falsche Aktivitätsreihenfolge
- Wiederholte Aktivitäten und Nacharbeitsschleifen
Benutzerdefinierte Attribute:
- Aktivitätsbasierte Kostenrechnung
- KI-Vorhersagen
- Benutzerdefinierte Kategorisierungen
- Mathematische Transformationen
- Zeitbasierte Berechnungen
Wie Anreicherungen den Datensatz aktualisieren
Jedes Mal, wenn Sie neue Anreicherungen erstellen und berechnen:
- Wird die Datenpipeline ausgeführt
- Neue Attribute werden dem angereicherten Datensatz hinzugefügt
- Diese neuen Attribute stehen für Filter und Berechnungen zur Verfügung
- Ihre Analyse wird mit jeder Anreicherung leistungsfähiger
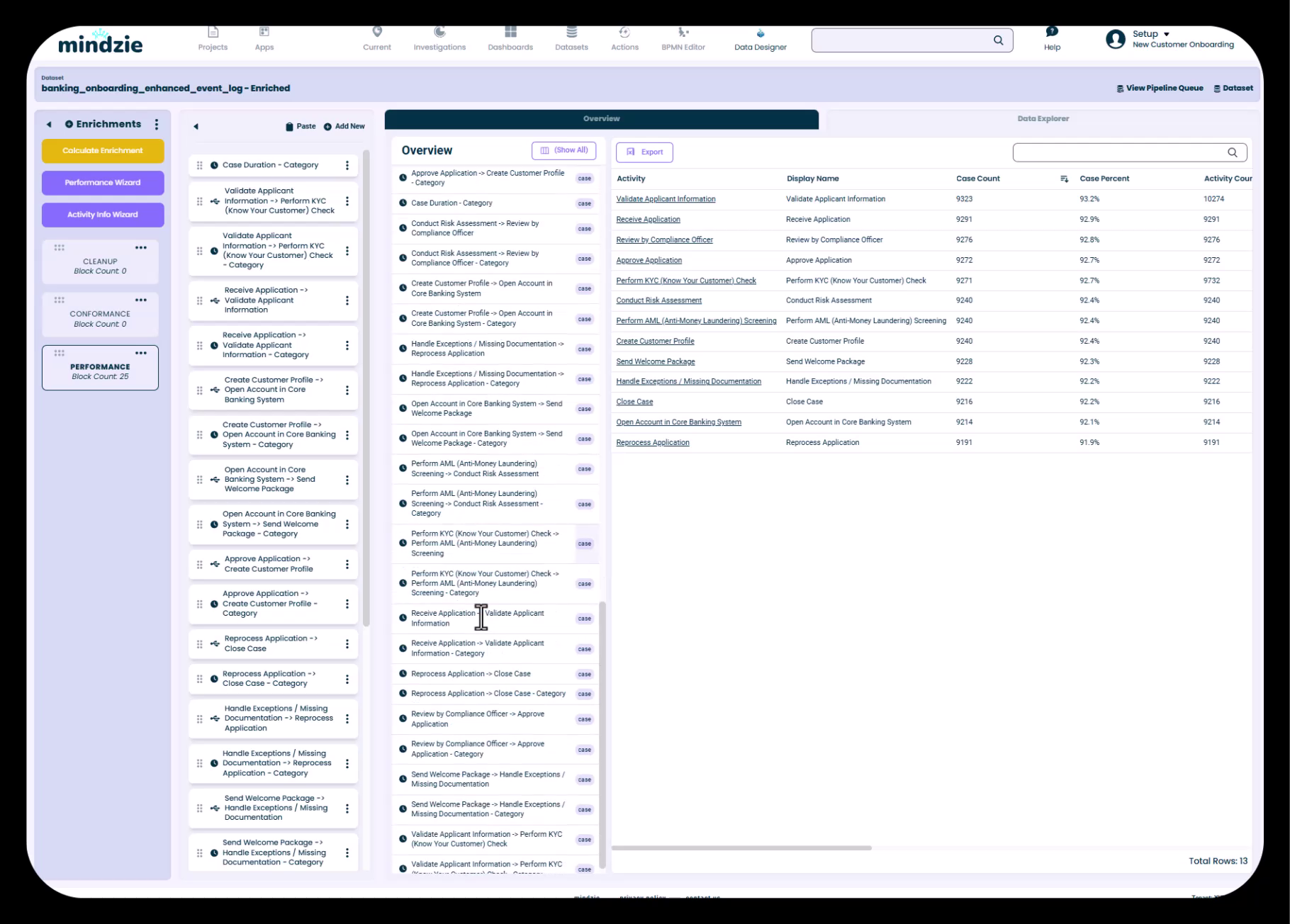 Datenübersicht zeigt sowohl Originalattribute als auch angereicherte Attribute mit Symbolen, die systemgenerierte Erweiterungen anzeigen
Datenübersicht zeigt sowohl Originalattribute als auch angereicherte Attribute mit Symbolen, die systemgenerierte Erweiterungen anzeigen
Automatisch von mindzie hinzugefügte Attribute
Auch ohne manuelle Anreicherungen fügt mindzie Studio automatisch mehrere nützliche Attribute zu Ihrem angereicherten Datensatz hinzu, darunter:
- Tageszeit – Wann Aktivitäten stattgefunden haben
- Fallbeginn – Wann jeder Fall gestartet wurde
- Fallende – Wann jeder Fall beendet wurde
- Falldauer – Gesamtzeit von Anfang bis Ende
- Erste Ressource – Wer den Fall initiiert hat
- Aktivitätsfrequenz – Wie oft Aktivitäten vorkommen
- Und viele mehr...
Diese automatischen Anreicherungen bieten Ihnen sofortige analytische Möglichkeiten ohne zusätzliche Konfiguration.
Den richtigen Datensatz für die Analyse auswählen
Beim Erstellen von Untersuchungen und Analyse-Notebooks in mindzie Studio müssen Sie auswählen, welchen Datensatz Sie analysieren möchten.
Beste Praxis: Wählen Sie stets den angereicherten Datensatz für Ihre Untersuchungen und Analysen. Dieser Datensatz enthält alle erweiterten Attribute und berechneten Kennzahlen, die Ihre Analyse aussagekräftig und leistungsfähig machen.
Der Originaldatensatz sollte primär verwendet werden für:
- Referenz- und Validierungszwecke
- Datenqualitätsprüfungen
- Verständnis der Struktur der Quelldaten
Der kontinuierliche Verbesserungszyklus
Die Dual-Dataset-Architektur unterstützt einen iterativen Workflow:
- Hochladen – Importieren Sie Ihre Daten, um den Originaldatensatz zu erstellen
- Anreichern – Fügen Sie Leistungskennzahlen, Konformitätsregeln und benutzerdefinierte Attribute hinzu
- Berechnen – Führen Sie die Pipeline aus, um den angereicherten Datensatz zu aktualisieren
- Analysieren – Erstellen Sie Untersuchungen und Analysen mit den angereicherten Attributen
- Wiederholen – Fügen Sie je nach Bedarf weitere Anreicherungen hinzu, um Ihre Erkenntnisse zu vertiefen
Jeder Zyklus macht Ihren angereicherten Datensatz wertvoller und Ihre Analyse anspruchsvoller.
Wichtigste Erkenntnisse
- Zwei Datensätze werden erstellt: Original (Rohdaten) und Angereichert (erweiterte Daten)
- Automatische Erstellung: Der angereicherte Datensatz wird automatisch beim Hochladen der Daten erstellt
- Verwenden Sie den angereicherten Datensatz: Dies ist Ihr primärer Datensatz für alle Analysen und Untersuchungen
- Pipeline-Ausführung: Die Datenpipeline transformiert Original in Angereichert
- Kontinuierliche Verbesserung: Jede Anreicherungsberechnung fügt neue Attribute zum angereicherten Datensatz hinzu
- Standardanalyse: mindzie Studio stellt automatisch hilfreiche Startanalysen bereit
- Iterativer Prozess: Sie können fortfahren, Anreicherungen hinzuzufügen, um Ihre Analyse leistungsfähiger zu machen