Erstellen von Analysen mit Filtern und Rechnern
Überblick
mindzie studio bietet einen leistungsstarken Low-Code/No-Code-Ansatz zur Erstellung von Prozessanalysen anhand eines grundlegenden Paradigmas: Analyse, Filter und Rechner. Dieses Tutorial führt Sie durch die Erstellung aussagekräftiger Kennzahlen und Erkenntnisse mithilfe der umfangreichen Bibliothek vorgefertigter Filter und Rechner von mindzie, wodurch komplexe Programmierung oder manuelle Berechnungen entfallen.
Durch die Kombination von Filtern zur Isolierung bestimmter Datenabschnitte mit Rechnern zur Visualisierung von Erkenntnissen können Sie schnell anspruchsvolle Prozesskennzahlen erstellen, die kritische Geschäftsfragen zu Leistung, Effizienz und Einhaltung beantworten.
Voraussetzungen
Bevor Sie eine Analyse mit Filtern und Rechnern erstellen, sollten Sie Folgendes haben:
- Ein aktives mindzie studio Projekt mit geladenen Daten
- Abgeschlossene Log-Anreicherung zur Erstellung erweiterter Attribute (siehe „Mastering the Log Enrichment Engine“)
- Eine Untersuchung und ein Analyse-Notebook erstellt (siehe „Working with Investigations and Analysis Notebooks“)
- Verständnis der Attribute und Struktur Ihres Datensatzes
Verständnis des Analyse-Filter-Rechner-Paradigmas
mindzie studio organisiert die analytische Arbeit um drei Kernbausteine:
Analyse (Der Arbeitsbereich)
Analyse-Notebooks sind ähnlich wie Jupyter-Notebooks – sie dienen als Ihr Arbeitsbuch oder Arbeitsblatt, in dem Sie Kennzahlen entdecken und erstellen. Jede Analyse bietet einen dedizierten Raum zur Erforschung spezifischer Aspekte Ihres Prozesses.
Filter (Datenisolierung)
Filter ermöglichen es Ihnen, bestimmte Datenabschnitte für gezielte Analysen zu isolieren. Sie beantworten die Frage: „Mit welchen Daten möchte ich arbeiten?“ Beispiele sind:
- Filterung nach Division, Abteilung oder Region
- Isolierung von Fällen aus bestimmten Zeiträumen
- Auswahl von Fällen mit bestimmten Attributen
- Trennung der Daten nach Prozessvariante oder Ergebnis
Rechner (Visualisierungen und Kennzahlen)
Rechner sind Visualisierungen, die die Frage beantworten: „Was möchte ich mit diesen Daten tun?“ Sie verwandeln Ihre gefilterten Daten in verwertbare Erkenntnisse durch Diagramme, Statistiken, Prozesskarten und andere visuelle Darstellungen.
Die Kraft der Kombination
Die wahre Stärke liegt in der Kombination dieser Bausteine. Sie können mehrere Filter und mehrere Rechner stapeln, um anspruchsvolle Analysen zu erstellen, die komplexe Geschäftsfragen beantworten – ohne eine einzige Codezeile zu schreiben.
Erstellen Ihrer ersten Analyse: Durchschnittliche Prozessdauer
Dieser Leitfaden zeigt, wie Sie mit dem Filter- und Rechneransatz eine einfache, aber aussagekräftige Kennzahl erstellen – die durchschnittliche Dauer von Kunden-Onboarding-Fällen.
Schritt 1: Öffnen Sie Ihr Analyse-Notebook
- Navigieren Sie in der linken Seitenleiste zu Ihrer Untersuchung
- Klicken Sie auf das Analyse-Notebook, in dem Sie arbeiten möchten
- Stellen Sie sicher, dass Sie die Registerkarte „Notebook“ in der Analyseoberfläche anzeigen
Sie sehen den Haupt-Arbeitsbereich der Analyse mit Schaltflächen oben zum Hinzufügen verschiedener Blocktypen.
Die Symbolleiste enthält:
- Filter hinzufügen – Datenfilterblöcke hinzufügen
- Rechner hinzufügen – Visualisierungs- und Kennzahlblöcke hinzufügen
- Alarm hinzufügen – Automatisierte Warnungen basierend auf Schwellenwerten erstellen
- Block einfügen – Zuvor kopierte Analyseblöcke einfügen
- Erweitern/Reduzieren – Sichtbarkeit der Copilot-Seitenleiste steuern
Schritt 2: Wann Filter verwenden
Für diese erste Kennzahl konzentrieren wir uns auf Rechner ohne Filter anzuwenden. So erhalten wir einen Gesamtdurchschnitt über alle Fälle im Datensatz.
Filter werden dann wichtig, wenn Sie Folgendes brauchen:
- Vergleich der Leistung über verschiedene Divisionen oder Regionen (z.B. USA vs. Europa)
- Analyse bestimmter Zeiträume (z.B. Q1 vs. Q2)
- Isolierung problematischer Fälle (z.B. nur Fälle, die Compliance-Regeln verletzt haben)
- Segmentierung nach beliebigen Attributen von Fall oder Ereignis
Um verfügbare Filter zu durchsuchen, klicken Sie auf „Filter hinzufügen“.
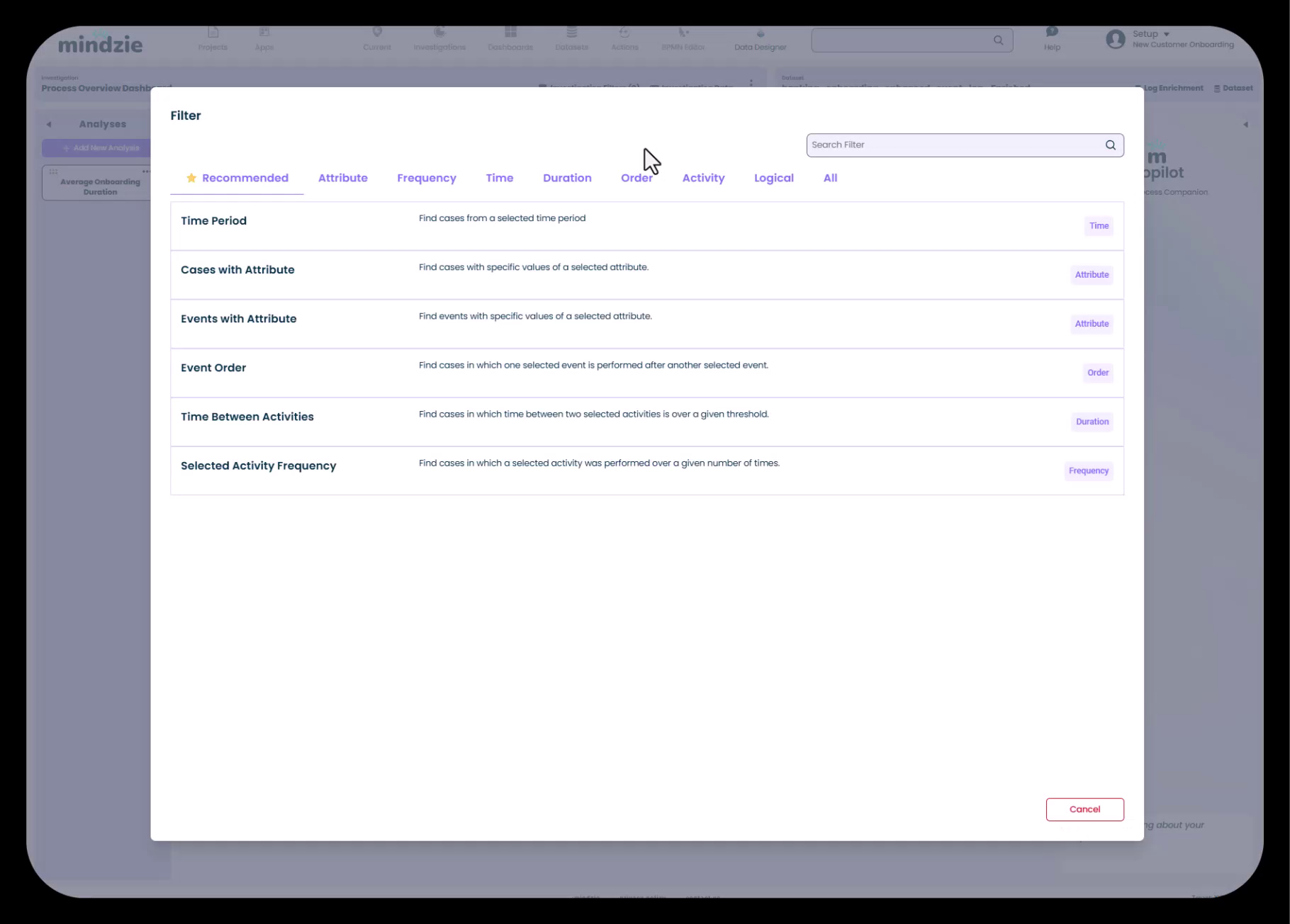
mindzie stellt eine umfangreiche Bibliothek vorgefertigter Filter bereit, organisiert nach Kategorien:
- Empfohlen – Häufig genutzte Filter basierend auf Ihren Daten
- Attribut – Filter nach Fall- oder Ereignisattributwerten
- Häufigkeit – Filter nach Aktivitätszählungen
- Zeit – Filter nach Zeiträumen und Datumsbereichen
- Dauer – Filter nach Prozess- oder Aktivitätsdauer
- Reihenfolge – Filter nach Aktivitätssequenz
- Aktivität – Filter nach bestimmten Aktivitäten
- Logisch – Kombinieren von Filtern mit UND-/ODER-Logik
Jeder Filter enthält eine Beschreibung, die seinen Zweck erklärt, sodass Sie leicht das richtige Werkzeug für Ihre Analysebedürfnisse finden.
Schritt 3: Rechner hinzufügen
Klicken Sie auf die Schaltfläche „Rechner hinzufügen“, um die Rechnerbibliothek zu öffnen.
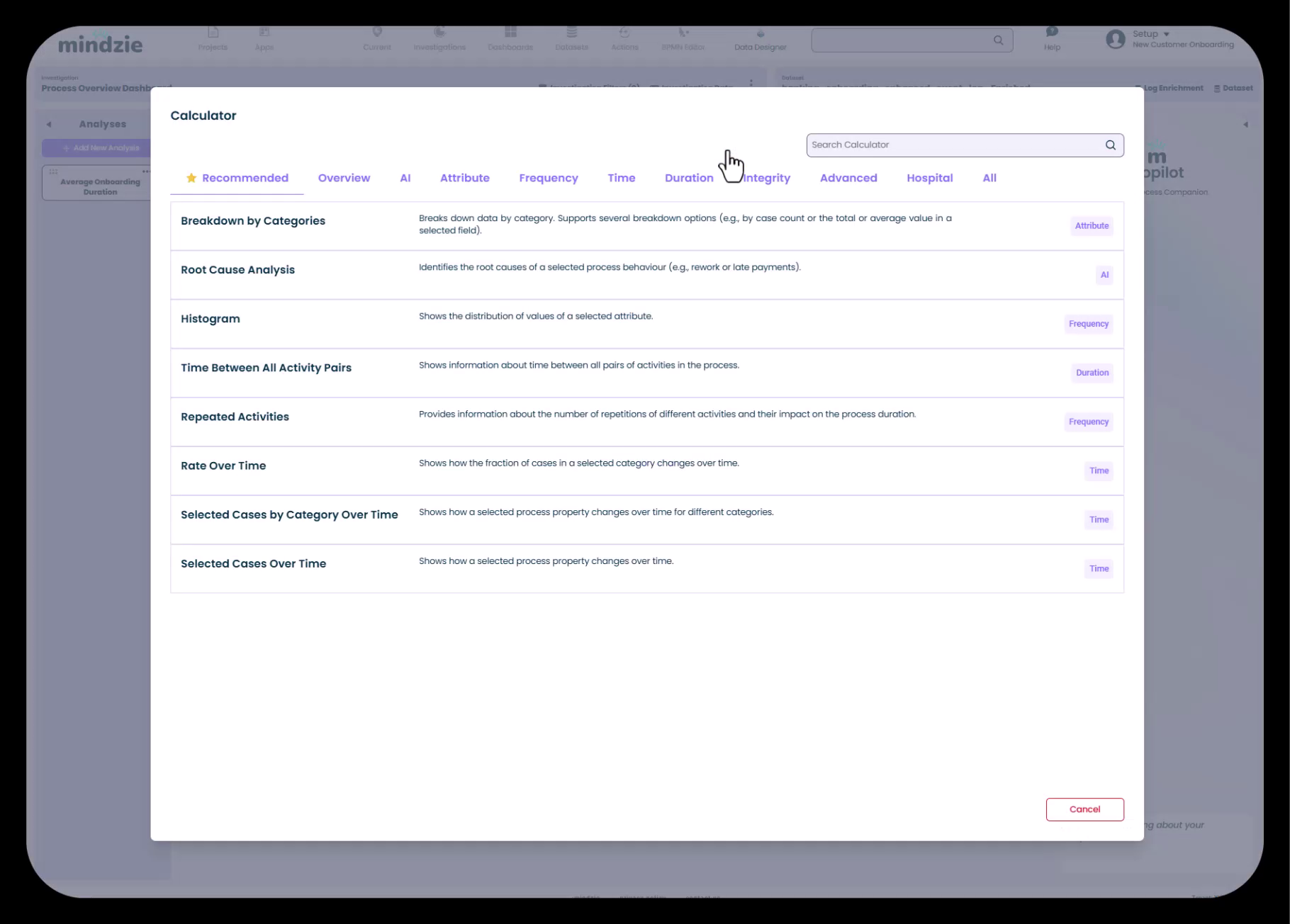
Die Rechnerbibliothek ist in Kategorien organisiert:
- Empfohlen – Rechner, die zu Ihrem aktuellen Kontext passen
- Übersicht – Zusammenfassende Statistiken und KPIs
- KI – KI-gestützte Erkenntnisse
- Attribut – Attributbasierte Analysen und Verteilungen
- Häufigkeit – Analyse der Aktivitätshäufigkeit
- Zeit – Zeitbasierte Trends und Muster
- Dauer – Dauerkennzahlen und Verteilungen
- Integrität – Datenqualitäts- und Konformitätskennzahlen
- Erweitert – Spezialisierte Rechner für komplexe Analysen
- Krankenhaus – Gesundheitswesen-spezifische Kennzahlen (falls zutreffend)
Schritt 4: Suche nach dem Durchschnittsrechner
Verwenden Sie das Suchfeld oben in der Rechnerbibliothek, um schnell zu finden, was Sie benötigen.
- Geben Sie „average“ ein
- Wählen Sie „Average Value“ aus den gefilterten Ergebnissen aus
Die Suchfunktion spart Zeit beim Arbeiten mit mindzies umfangreicher Bibliothek von über 40 Rechnern. Sie können nach Rechnernamen, Kategorie oder Funktion suchen.
Schritt 5: Rechner-Attribut konfigurieren
Nachdem Sie den Rechner „Average Value“ ausgewählt haben, müssen Sie angeben, für welches Attribut der Durchschnitt berechnet werden soll.
- Klicken Sie im Rechner-Konfigurationsfenster auf das Dropdown „Attribute Name“
- Suchen Sie in der Attributliste nach „duration“
- Wählen Sie „Case Duration“
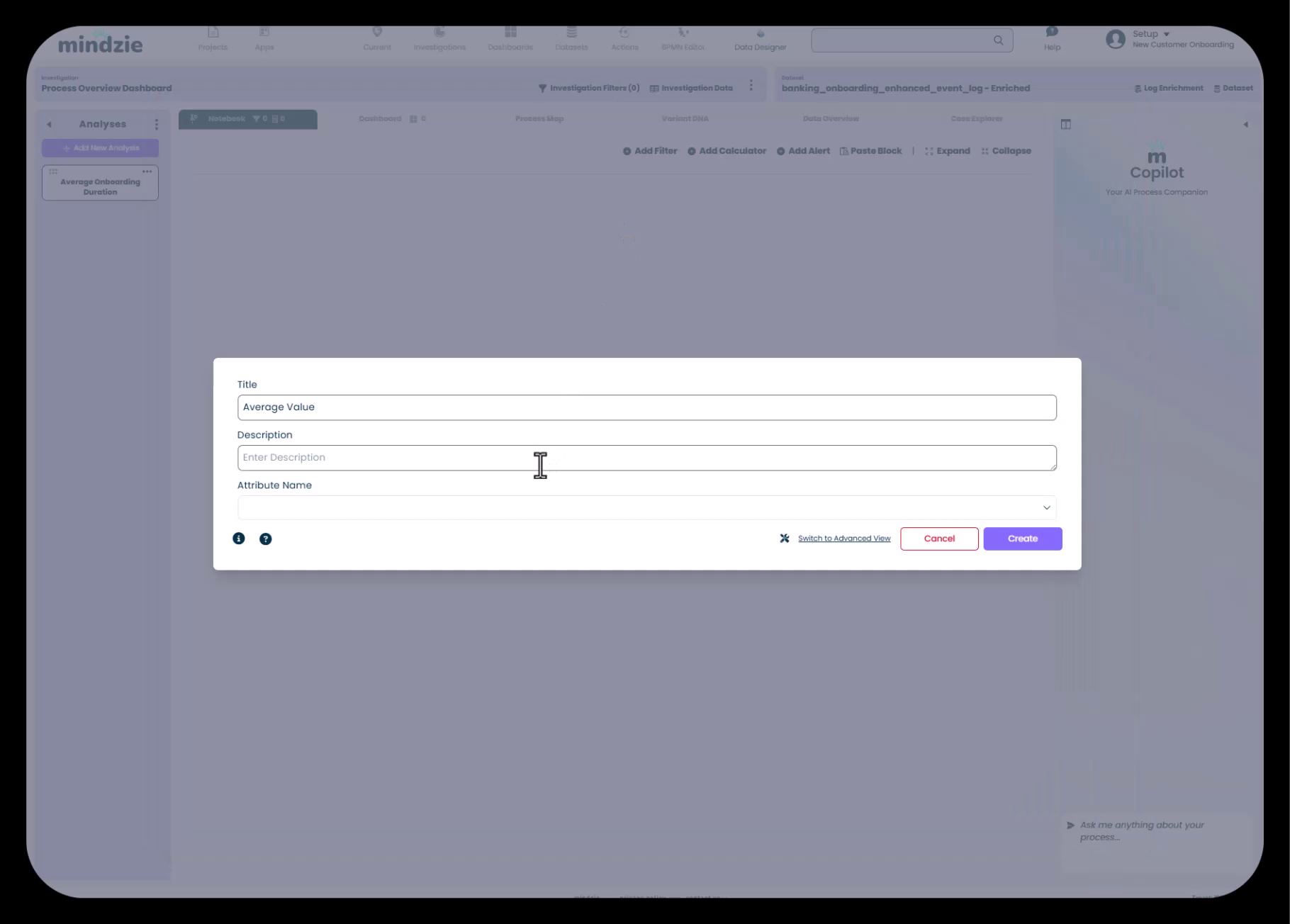
Warum Case Duration verfügbar ist:
Das Attribut Case Duration existiert, weil Sie zuvor die Daten durch die mindzie Log Enrichment Engine verarbeitet haben. Der Performance Wizard oder andere Anreicherungsblöcke berechneten dieses Attribut durch Analyse der Zeitstempelunterschiede zwischen Start- und Abschlussereignissen eines Falls.
Dies unterstreicht die entscheidende Verbindung zwischen Log-Anreicherung und Analyse: Anreicherungen erzeugen die Attribute, die Ihre Rechner antreiben.
Schritt 6: Ergebnis ansehen
Nachdem Sie das Attribut Case Duration ausgewählt und den Rechner hinzugefügt haben, berechnet mindzie das Ergebnis sofort und zeigt es an.
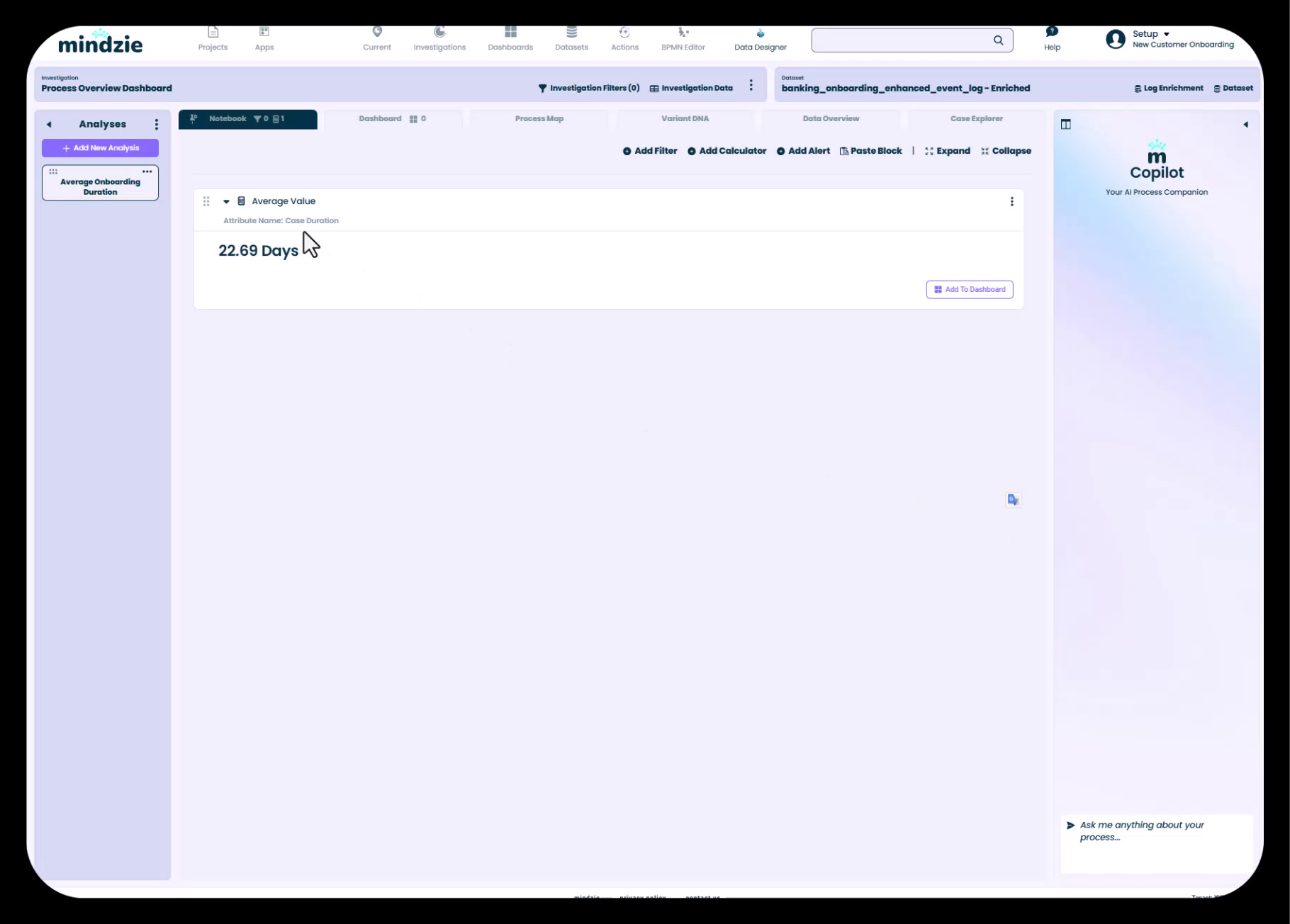
Der Ergebniseblock zeigt:
- Rechnertyp – Überschrift „Average Value“
- Attributname – „Case Duration“ (das gemittelte Attribut)
- Berechnete Kennzahl – „22.69 Days“ (die durchschnittliche Dauer aller Fälle)
- Aktionsschaltflächen – Optionen zum Hinzufügen zum Dashboard, Konfigurieren oder Entfernen
Diese Kennzahl stellt nun einen wichtigen Leistungsindikator (KPI) für Ihren Prozess dar: Im Durchschnitt dauert das Kunden-Onboarding 22,69 Tage von Anfang bis Ende.
Erstellung komplexerer Analysen
Mehrere Filter kombinieren
Um segmentierte Analysen zu erstellen, können Sie mehrere Filter im selben Analyseblock hinzufügen:
- Klicken Sie auf „Filter hinzufügen“, um den ersten Filter hinzuzufügen (z.B. Filter nach Division = „North America“)
- Klicken Sie erneut auf „Filter hinzufügen“, um weitere Filter hinzuzufügen (z.B. Filter nach Jahr = „2024“)
- Fügen Sie Ihren Rechner hinzu (z.B. Average Value für Case Duration)
Die Filter wirken zusammen (typischerweise mit UND-Logik), um Ihre Daten auf genau den gewünschten Abschnitt zu beschränken.
Mehrere Rechner hinzufügen
Sie können mehrere Rechner auf den gleichen gefilterten Datensatz anwenden, um verschiedene Perspektiven anzuzeigen:
- Fügen Sie Filter ein, um Ihren Datenabschnitt zu bestimmen
- Fügen Sie mehrere Rechner hinzu (z.B. Average Value, Verteilungsdiagramm, Trend über die Zeit)
- Jeder Rechner arbeitet auf denselben gefilterten Daten und liefert ergänzende Erkenntnisse
Vergleichende Analyse erstellen
Um die Leistung verschiedener Segmente zu vergleichen:
- Erstellen Sie separate Analyseblöcke für jedes Segment
- Verwenden Sie Filter, um jedes Segment zu isolieren (z.B. ein Block für die Region USA, ein anderer für Europa)
- Verwenden Sie in jedem Block dieselbe Rechnerkonfiguration
- Vergleichen Sie die Ergebnisse nebeneinander oder veröffentlichen Sie sie auf demselben Dashboard
Erweiterte Rechnerkonfiguration
Viele Rechner bieten zusätzliche Konfigurationsoptionen über die Attributauswahl hinaus:
- Aggregationsmethoden – Auswahl zwischen Durchschnitt, Median, Summe, Minimum, Maximum
- Gruppierung – Gruppieren der Ergebnisse nach einem anderen Attribut (z.B. Durchschnittliche Dauer nach Abteilung)
- Zeitliche Aufteilung – Darstellung von Trends über Tage, Wochen, Monate oder Jahre
- Visuelle Gestaltung – Anpassung von Farben, Beschriftungen und Anzeigeformaten
- Schwellenwerte – Festlegen von Leistungszielen oder Warnstufen
Entdecken Sie das Konfigurationsfenster jedes Rechners über das Drei-Punkte-Menü im Rechnerblock.
Nutzung angereicherter Attribute
Die Wirksamkeit von Filtern und Rechnern hängt stark davon ab, bedeutungsvolle Attribute zu analysieren. Häufig verwendete angereicherte Attribute, die leistungsstarke Analysen ermöglichen, sind:
Leistungsattribute (vom Performance Wizard):
- Case Duration
- Activity Duration
- Time Between Activities
- Performance Buckets (Schnell, Normal, Langsam)
Konformitätsattribute (von Conformance Rules):
- Conformance Status (Konform/Nicht konform)
- Anzahl der Regelverstöße
- Schweregrade
Kostenattribute (vom Activity Info Wizard):
- Gesamtkosten pro Fall
- Aktivitätskosten
- Ressourcenkosten
KI-Vorhersagen (aus KI-Anreicherungen):
- Voraussichtliche Abschlusszeit
- Risikobewertungen
- Empfohlene Maßnahmen
Ohne Anreicherung sind Sie auf die Analyse der ursprünglichen Datenattribute (Case ID, Activity Name, Timestamp, Resource) beschränkt. Anreicherung entfesselt das volle analytische Potenzial von mindzie studio.
Best Practices
Einfach anfangen, dann verfeinern
Beginnen Sie mit grundlegenden Kennzahlen wie Gesamtdurchschnitten oder Zählungen, bevor Sie komplexe Filter hinzufügen. Dies hilft Ihnen:
- Die Basisleistung zu verstehen
- Zu überprüfen, ob Ihre Daten korrekt geladen sind
- Sicher mit der Oberfläche umzugehen, bevor Sie komplexe Szenarien angehen
Beschreibende Analysenamen verwenden
Verwenden Sie beim Erstellen von Analyse-Notebooks klare Namen, die beschreiben, was Sie untersuchen:
- „Durchschnittliche Onboarding-Dauer“ (klar)
- „Analyse 1“ (unklar)
Filter logisch organisieren
Bei Verwendung mehrerer Filter ordnen Sie diese in logischer Reihenfolge:
- Zeitbasierte Filter zuerst (Jahr, Quartal, Monat)
- Strukturale Filter zweitens (Division, Abteilung, Region)
- Ergebnisbasierte Filter zuletzt (Konformitätsstatus, Leistungsbucket)
Erfolgreiche Muster wiederverwenden
Nachdem Sie eine effektive Analyse erstellt haben, können Sie:
- Den gesamten Analyseblock kopieren und die Filter anpassen
- Sie in andere Untersuchungen im gleichen Projekt kopieren
- Sie in andere Projekte kopieren (siehe „Reusing Analysis: Copying and Adapting Notebooks“)
Dokumentieren Sie Ihre Analyse
Verwenden Sie die Notizfunktion in Analyse-Notebooks, um festzuhalten:
- Welche Frage die Analyse beantwortet
- Welche Filter und Rechner Sie warum verwenden
- Etwaige Annahmen oder Datenbeschränkungen
- Wie die Ergebnisse zu interpretieren sind
Häufige Anwendungsfälle
Leistungsbenchmarking
Ziel: Durchschnittliche Prozessdauer über Regionen vergleichen
- Erstellen Sie für jede Region einen Analyseblock
- Fügen Sie für jede Region einen „Cases with Attribute“-Filter hinzu (z.B. Region = „North America“)
- Fügen Sie den Average Value Rechner mit Case Duration Attribut hinzu
- Veröffentlichen Sie alle Kennzahlen auf demselben Dashboard zum Vergleich nebeneinander
Trendanalyse
Ziel: Verfolgen, wie sich die Leistung über die Zeit verändert
- Fügen Sie einen Zeitbereichsfilter hinzu, um Ihren Datumsbereich auszuwählen
- Fügen Sie einen Trend-Rechner hinzu, der Case Duration im Zeitverlauf zeigt
- Stellen Sie die Zeitaufteilung auf Monat oder Quartal ein
- Suchen Sie nach saisonalen Mustern oder Verbesserungen
Ursachenuntersuchung
Ziel: Verstehen, warum manche Fälle länger dauern als andere
- Fügen Sie einen Performance Bucket Filter hinzu, um „Langsame“ Fälle zu isolieren
- Fügen Sie mehrere Rechner hinzu, um verschiedene Dimensionen zu erkunden:
- Variant DNA, um zu sehen, welche Prozesswege langsam sind
- Attributverteilung, um zu sehen, welche Abteilungen langsame Fälle haben
- Root Cause Analysis, um statistisch signifikante Faktoren zu identifizieren
Konformitätsüberwachung
Ziel: Verstöße gegen Compliance-Regeln messen
- Fügen Sie einen Conformance Status Filter hinzu, um „Nicht konforme“ Fälle auszuwählen
- Fügen Sie Rechner hinzu, um das Problem zu quantifizieren:
- Anzahl nicht konformer Fälle
- Prozentsatz an allen Fällen
- Aufschlüsselung nach Verstoßtypen
- Trend über die Zeit
Fehlerbehebung
Rechner zeigt „Keine Daten“ an
Ursachen:
- Filter sind zu restriktiv und schließen alle Fälle aus
- Das ausgewählte Attribut existiert nicht im Datensatz
- Die Daten sind noch nicht vollständig geladen
Lösungen:
- Entfernen Sie Filter einzeln, um den zu restriktiven zu identifizieren
- Vergewissern Sie sich, dass das Attribut im Datenübersichts-Tab existiert
- Prüfen Sie, ob die Anreicherungen erfolgreich berechnet wurden
Attribut nicht in Dropdown-Liste
Ursachen:
- Anreicherung wurde noch nicht berechnet
- Anreicherung schlug aufgrund eines Konfigurationsfehlers fehl
- Nutzung des Originaldatensatzes statt des angereicherten Datensatzes
Lösungen:
- Navigieren Sie zur Log Enrichment und berechnen Sie die Anreicherung
- Prüfen Sie die Anreicherungskonfiguration auf Fehler
- Vergewissern Sie sich, dass Ihre Untersuchung den angereicherten Datensatz verwendet
Rechnerergebnis scheint falsch
Ursachen:
- Filter sind nicht wie beabsichtigt konfiguriert
- Falsches Attribut ausgewählt
- Datenqualitätsprobleme in den Quelldaten
Lösungen:
- Überprüfen Sie die Filterkonfiguration sorgfältig
- Prüfen Sie die Attributauswahl auf Übereinstimmung mit Ihren Absichten
- Nutzen Sie die Datenübersicht, um Attributwerte manuell zu prüfen
- Verwenden Sie den Case Explorer, um einzelne Fälle zu untersuchen
Zusammenfassung
Das Analyse-Filter-Rechner-Paradigma ist die Grundlage aller Arbeit in mindzie studio. Durch das Beherrschen dieser Bausteine können Sie:
- Anspruchsvolle Kennzahlen ohne Programmierung erstellen
- Komplexe Geschäftsfragen durch visuelle Analyse beantworten
- Ihre Untersuchungen schnell iterieren und verfeinern
- Wiederverwendbare Analyse-Muster erstellen, die projektübergreifend angepasst werden können
Merken Sie sich: Filter definieren, „welche Daten“ Sie analysieren, und Rechner definieren, „was Sie über diese Daten wissen möchten“. Die Kombination dieser beiden einfachen Konzepte ermöglicht unbegrenzte analytische Möglichkeiten.