Generierung synthetischer Daten
Die Funktion Generate Synthetic Data erstellt vollständig neue, erfundene Datensätze, die die statistischen Eigenschaften Ihrer Originaldaten bewahren, jedoch keine tatsächlichen Werte aus Ihrer Quelle enthalten. Dies ist nützlich für:
- Demos – Erstellen Sie realistisch aussehende Daten, um Ihre Process-Mining-Fähigkeiten zu präsentieren
- Tests – Generieren Sie Testdatensätze mit bekannten Eigenschaften
- Freigabe – Teilen Sie Datenmuster extern, ohne sensible Informationen preiszugeben
- Training – Erstellen Sie Trainingsdatensätze für Machine-Learning-Modelle
Wichtig: Dies ist KEINE Anonymisierung. Synthetische Daten sind vollständig erfunden – keine Originaldatenwerte existieren in der Ausgabe. Der synthetische Datensatz kann bedenkenlos extern geteilt werden.
Zugriff
- Navigieren Sie zur Datasets-Seite
- Klicken Sie auf das Drei-Punkte-Menü bei einem beliebigen Datensatz
- Wählen Sie Generate Synthetic Data
Konfigurationsoptionen
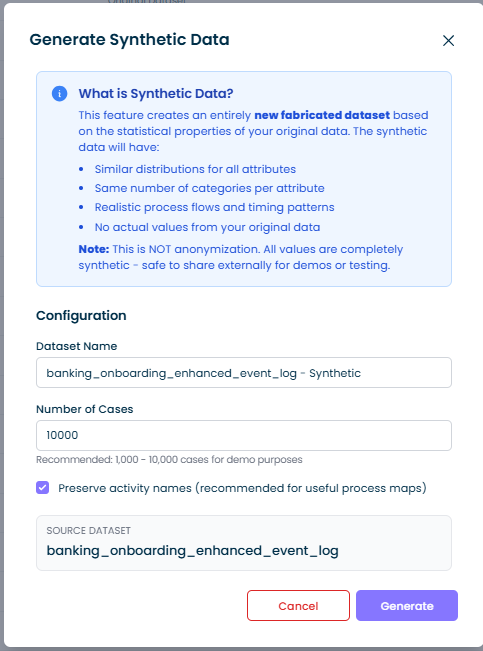
Dataset-Name
Der Name Ihres synthetischen Datensatzes. Standardmäßig wird der Name Ihres Quelldatensatzes übernommen und mit „ - Synthetic“ ergänzt.
Anzahl der Fälle
Geben Sie an, wie viele Fälle im synthetischen Datensatz generiert werden sollen:
- Minimum: 100 Fälle
- Maximum: 100.000 Fälle
- Empfohlen: 1.000 – 10.000 Fälle für Demo-Zwecke
Größere Datensätze benötigen länger zur Generierung und führen zu größeren Download-Dateien.
Activity-Namen beibehalten
Wenn aktiviert (empfohlen), behält der synthetische Datensatz Ihre ursprünglichen Aktivitätsnamen wie „Submit Order“, „Review Application“ usw. bei. Dies erzeugt hilfreiche Prozesskarten, die Ihren tatsächlichen Prozessfluss widerspiegeln.
Wenn deaktiviert, werden Aktivitätsnamen durch generische Bezeichnungen wie „Activity_1“, „Activity_2“ usw. ersetzt. Verwenden Sie diese Option, wenn selbst Ihre Activity-Namen sensible Informationen enthalten.
Was generiert wird
Der synthetische Datengenerator analysiert Ihren Quelldatensatz und erstellt neue Daten mit:
| Element | Wie es generiert wird |
|---|---|
| Case-IDs | Neue sequentielle IDs: Case_1, Case_2 usw. |
| Activity-Namen | Aus der Quelle übernommen (oder anonymisiert, wenn Option deaktiviert) |
| Zeitstempel | Realistische Daten mit ähnlichen Dauer-Mustern zwischen Aktivitäten |
| Textattribute | Ersetzt durch generische Werte wie Customer_1, Region_2 usw. unter Erhaltung der Verteilung (wenn 60 % der Fälle „High Priority“ waren, haben ca. 60 % der synthetischen Fälle Priority_1) |
| Numerische Attribute | Generiert mit ähnlichen statistischen Eigenschaften (Mittelwert, Streuung, min/max Bereich) |
| Prozessfluss | Aktivitätssequenzen basierend auf Ihren tatsächlichen Prozessvarianten |
Was NICHT enthalten ist
Berechnete Spalten sind im synthetischen Output ausgeschlossen, da sie beim Import in mindzieStudio neu berechnet würden.
Ausgabe
Wenn Sie auf Generate klicken, führt mindzieStudio folgende Schritte aus:
- Analysiert Ihre Quelldaten, um statistische Muster zu extrahieren
- Generiert die angegebene Anzahl synthetischer Fälle
- Lädt das Ergebnis automatisch als CSV-Datei herunter
Der Download-Dateiname entspricht Ihrem Dataset-Namen mit der Endung .csv.
Beispiel
Quelldaten:
CaseId,Activity,Timestamp,Customer,Amount
C001,Submit,2024-01-01 09:00,Acme Corp,1500.00
C001,Review,2024-01-01 11:00,Acme Corp,1500.00
C002,Submit,2024-01-02 10:00,Beta Inc,2300.00
Synthetische Ausgabe (bei aktiviertem Activity-Namen beibehalten):
CaseId,Activity,Timestamp,Customer,Amount
Case_1,Submit,2020-03-15 14:23,Customer_1,1842.37
Case_1,Review,2020-03-15 16:45,Customer_1,1842.37
Case_2,Submit,2020-07-22 09:12,Customer_2,1523.89
Beachten Sie:
- Aktivitätsnamen werden beibehalten
- Kundennamen werden durch generische
Customer_1,Customer_2ersetzt - Beträge sind ähnlich im Bereich, aber erfunden
- Zeitstempel sind realistisch, aber komplett neu
Anwendungsfälle
Erstellung von Demo-Datensätzen
Generieren Sie synthetische Daten aus Ihrem Produktionsprozess, um sichere Demo-Datensätze zu erstellen, die reale Prozessmuster zeigen, ohne echte Geschäftsdaten preiszugeben.
Teilen mit externen Beratern
Bei Zusammenarbeit mit externen Process-Mining-Beratern oder Anbietern teilen Sie synthetische Datensätze, die Ihre Prozessmerkmale bewahren, ohne sensible Informationen zu offenbaren.
Leistungstests
Generieren Sie große synthetische Datensätze (50.000+ Fälle), um zu testen, wie Ihre Notebooks und Dashboards mit größeren Datenmengen umgehen.
Schulung und Ausbildung
Erstellen Sie synthetische Datensätze, um neue Teammitglieder im Process Mining mit realistischen, aber sicheren Daten zu trainieren.