AI Causal Analysis (Alpha)
Der Rechner AI Causal Analysis nutzt Machine Learning, um zu entdecken, welche Fallattribute ein Zielergebnis am stärksten beeinflussen. Anstatt nur Korrelation anzuzeigen, isoliert er die Merkmale mit dem größten statistischen Einfluss darauf, ob ein Fall dem von Ihnen definierten Ergebnis entspricht – so können Sie von "Was geschieht" zu "Warum es geschieht" übergehen.
Alpha-Funktion: Dieser Rechner ist Teil des mindzie Alpha-Programms. Es erfordert, dass PreRelease für Ihren Mandanten aktiviert ist. Weitere Informationen finden Sie unter Alpha Features.
Übersicht
AI Causal Analysis beantwortet Fragen wie:
- Warum dauern manche Fälle länger als 7 Tage bis zum Abschluss?
- Welche Attribute machen es wahrscheinlicher, dass eine Rechnung verspätet bezahlt wird?
- Was unterscheidet Fälle, die einen SLA verletzen, von denen, die ihn einhalten?
- Welche Einrichtungen, Teams oder Produktkategorien beeinflussen ein bestimmtes Ergebnis am stärksten?
Sie definieren das Ergebnis (die Fälle, die Sie erklären möchten), zeigen dem Rechner eine Auswahl von Eingabespalten, und er liefert eine Rangliste der Faktoren, die am stärksten dafür verantwortlich sind, dass diese Fälle in die Ergebnisgruppe fallen.
Vergleich mit Root Cause Analysis
AI Causal Analysis verfolgt dasselbe Ziel wie der bestehende Rechner Root Cause Analysis, verfolgt jedoch einen deutlich strengeren Ansatz:
| Fähigkeit | Root Cause Analysis | AI Causal Analysis |
|---|---|---|
| Findet Einzel-Attribut-Treiber | Ja | Ja |
| Findet Mehr-Attribut-Konjunktionen (bis zu 3 Attribute pro Regel) | Nein | Ja |
| Unterscheidet Korrelation von Kausalität | Nein | Ja (Kausalgraph + Propensity-Anpassung) |
| Liefert Konfidenzintervalle | Nein | Ja (95 % Wilson CI für jede Regel) |
| Kontrolliert Mehrfachtests | Nein | Ja (Benjamini-Hochberg FDR) |
| Verarbeitet numerische / Datums- / Zeitattribute | Nein (nur Strings) | Ja (ergebnisbewusstes Binning) |
| Verständliche Erzählung je Treiber | Nein | Ja |
Verwenden Sie Root Cause Analysis für einen schnellen Einzel-Attribut-Scan und AI Causal Analysis für jede ernsthafte Untersuchung – insbesondere wenn jemand auf Basis der Ergebnisse handeln wird.
So fügen Sie den Rechner hinzu
- Öffnen Sie ein Notebook in mindzieStudio
- Klicken Sie auf Add Calculator und wählen Sie AI Causal Analysis (Alpha)
- Konfigurieren Sie das Ergebnis und die Eingabespalten (siehe unten)
- Klicken Sie auf Create
Konfiguration
Titel
Der Anzeigename des Rechners. Standard ist AI Causal Analysis (Alpha) – ändern Sie ihn in etwas, das zur konkreten Frage passt, die Sie beantworten, zum Beispiel Warum sind ICU-Aufenthalte lang? oder Treiber verspäteter Zahlungen.
Beschreibung
Optionale Freitext-Notizen. Nützlich, um die Geschäftsfrage, den analysierten Zeitraum oder den anfragenden Stakeholder zu dokumentieren.
Ergebnis-Definition
Das Ergebnis ist die Gruppe von Fällen, die Sie erklären möchten. Der Rechner vergleicht diese Fälle mit dem Rest des Datensatzes und identifiziert, welche Eingabespalten die beiden Gruppen am besten voneinander trennen.
Es stehen drei Modi zur Definition des Ergebnisses zur Verfügung:
Filter-Modus
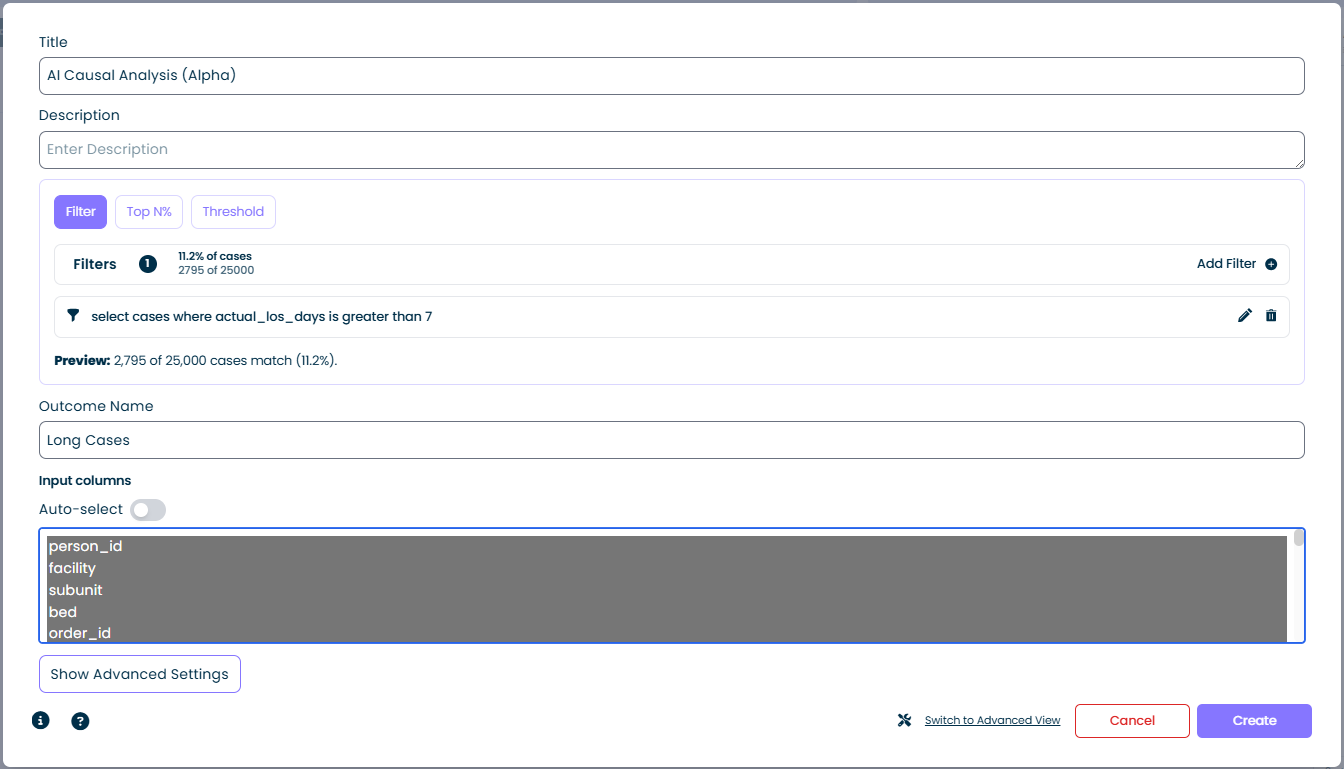
Wählen Sie den Tab Filter und fügen Sie einen oder mehrere Filterausdrücke hinzu. Der Rechner betrachtet Fälle, die zum Filter passen, als "Ergebnis"-Gruppe.
- Cases matching: angezeigt als Prozentsatz und absolute Anzahl, z. B.
11,2 % der Fälle / 2.795 von 25.000 - Add Filter: öffnet den Standard-Filter-Builder – kombinieren Sie beliebig viele Bedingungen
- Preview: wird beim Aufbau des Filters live aktualisiert, sodass Sie die Auswahl vor dem Ausführen des Rechners validieren können
Der Filter-Modus ist die flexibelste Option. Jede Bedingung, die Sie als mindzie-Filter ausdrücken können (Dauerschwellen, Attributübereinstimmungen, Aktivitätspräsenz usw.), kann zu einem Ergebnis werden. Im obigen Screenshot definiert der Filter select cases where actual_los_days is greater than 7 "Long Cases" als Ergebnis.
Top N %-Modus
Wählen Sie den Tab Top N%, um die höchsten (oder niedrigsten) Werte eines numerischen Attributs als Ergebnis zu verwenden. Das ist nützlich, wenn Sie "die schlechtesten Fälle" oder "die Top-Performer" erklären möchten, ohne einen festen Schwellenwert wählen zu müssen. Beispiel: die obersten 10 % der Fälle nach Durchlaufzeit.
Schwellen-Modus
Wählen Sie den Tab Threshold, um das Ergebnis mit einer einzigen numerischen Grenze für ein Attribut zu definieren. Jeder Fall oberhalb (oder unterhalb) des Wertes wird Teil der Ergebnisgruppe. Beispiel: Fälle, bei denen invoice_amount 50.000 übersteigt.
Ergebnis-Name
Eine kurze Bezeichnung, die die Ergebnisgruppe in den Resultaten identifiziert, zum Beispiel Long Cases, Late Payments oder SLA Breach. Dieser Name erscheint in der gesamten Analyseausgabe überall dort, wo auf die Ergebnisgruppe verwiesen wird.
Eingabespalten
Die Spalten, die das Modell bei der Suche nach Treibern des Ergebnisses nutzen darf.
- Spaltenliste: Jedes Fallattribut im Datensatz wird angezeigt. Wählen Sie ein oder mehrere aus, um sie in die Analyse einzubeziehen. Ausgewählte Spalten werden hervorgehoben.
- Auto-select-Umschalter: Bei aktivierter Option wählt mindzie automatisch eine sinnvolle Standardmenge von Eingabespalten basierend auf dem Datensatzschema aus. Schalten Sie dies aus, wenn Sie volle manuelle Kontrolle möchten – zum Beispiel, um eine Spalte auszuschließen, die trivial mit dem Ergebnis korreliert (etwa eine ID, die die Antwort verrät).
Tipps zur Auswahl der Eingabespalten:
- Schließen Sie Spalten aus, die nachgelagert zum Ergebnis sind. Wenn
discharge_datezur Berechnung vonactual_los_daysverwendet wird, wird sie die Ergebnisse dominieren, ohne Einsichten hinzuzufügen. - Schließen Sie Bezeichner mit hoher Kardinalität (
person_id,order_id) aus, es sei denn, Sie möchten gezielt Effekte pro Entität untersuchen. - Nehmen Sie kontextuelle Attribute (Einrichtung, Produktkategorie, Priorität, Region) auf – dort liegen typischerweise die interessanten Treiber.
Show Advanced Settings
Öffnet zusätzliche Feinabstimmungsoptionen für die Suche. Die Standardwerte funktionieren für die meisten Analysen gut – überschreiben Sie sie nur, wenn Sie einen konkreten Grund haben.
| Einstellung | Standard | Zweck |
|---|---|---|
| Beam width | 50 | Wie viele Kandidatenregeln bei jeder Suchtiefe behalten werden. Höher = erschöpfender, langsamer. |
| Max rule depth | 3 | Längste erlaubte Regel. 3 bedeutet Regeln der Form A AND B AND C. |
| Min cases per rule | 30 | Regeln, die weniger Fälle betreffen, werden als zu klein zum Handeln verworfen. |
| Min lift | 1.2 | Die Ergebnisquote innerhalb der Regel muss den Basiswert um mindestens diesen Faktor übersteigen (1,2 = mindestens 20 % höher als die Baseline). |
| FDR alpha | 0.05 | Benjamini-Hochberg-Signifikanzschwelle zur Kontrolle falscher Entdeckungen in der Regelsuche. |
| Max drivers returned | 20 | Obergrenze für die Anzahl der in der Tabellenansicht angezeigten Regeln. |
| Redundancy Jaccard | 0.9 | Regeln, deren Fallmengen sich um mehr als diesen Anteil überlappen, werden als Duplikate behandelt und gefiltert. |
| Sampling threshold | 2.000.000 Fälle | Datensätze oberhalb dieser Größe werden mit Floyds Kombinationsalgorithmus deterministisch heruntergesampelt. Die Ausgabe meldet WasSampled = true und die tatsächliche Stichprobengröße. |
Switch to Advanced View
Wechselt den Editor in den erweiterten Modus für feinkörnige Kontrolle über jeden Modellparameter. Die hier gezeigte geführte Ansicht reicht für die große Mehrheit der Anwendungsfälle aus.
Typischer Arbeitsablauf
- Frage formulieren – entscheiden Sie, welches Ergebnis Sie erklären möchten. "Was macht Fälle langsam?" wird zu einem Filter-Ergebnis
case_duration > 7 days. - Ergebnis definieren – nutzen Sie den Filter-, Top-N-%- oder Schwellen-Modus. Prüfen Sie, ob der Preview-Prozentsatz sinnvoll aussieht (zu wenige Fälle erzeugen instabile Ergebnisse; zu viele bedeuten, dass das Ergebnis nicht wirklich unterscheidend ist).
- Ergebnis benennen – wählen Sie eine knappe Bezeichnung, die in Ergebnissen und Berichten gut lesbar ist.
- Eingabespalten auswählen – starten Sie mit Auto-select und entfernen Sie anschließend alle Spalten, die die Antwort verraten oder nur Rauschen hinzufügen.
- Create – führen Sie den Rechner aus. Das Ergebnis zeigt die nach Rang sortierten Treiber des Ergebnisses.
- Interpretieren – prüfen Sie die obersten Treiber, verfeinern Sie Ergebnis oder Eingabemenge bei Bedarf und führen Sie den Rechner erneut aus.
Beispiel
Ein Krankenhaus-Betriebsteam möchte verstehen, warum manche stationäre Aufenthalte länger als 7 Tage dauern.
| Einstellung | Wert |
|---|---|
| Titel | AI Causal Analysis (Alpha) |
| Filter-Modus | select cases where actual_los_days is greater than 7 |
| Preview | 2.795 von 25.000 Fällen entsprechen (11,2 %) |
| Ergebnis-Name | Long Cases |
| Eingabespalten | facility, subunit, bed, order_id, ... (automatisch ausgewählt) |
Nach der Ausführung meldet der Rechner, welche Kombinationen von Einrichtung, Sub-Unit und Pflegeattributen Fälle mit langem Aufenthalt am stärksten von Fällen mit normalem Aufenthalt unterscheiden. Das verweist das Team auf konkrete Einheiten und Arbeitsabläufe, die untersucht werden sollten, anstatt alle Attribute manuell durchsuchen zu müssen.
Interpretation der Ergebnisse
Für jeden Top-Treiber erzeugt der Rechner einen verständlichen Erzählabsatz und ein Evidenz-Badge, das die Stärke des Befundes beschreibt:
| Badge | Bedeutung | Handlungsempfehlung |
|---|---|---|
| Causal | Sowohl das Kausalgraph-Signal als auch der um Confounder bereinigte Effekt sind positiv. | Stärkster handlungsfähiger Beleg – sicher für Interventionen zu priorisieren. |
| Likely Causal | Der Kausalgraph verbindet die Regel mit dem Ergebnis, aber der Effekt schwächt sich nach Bereinigung um Confounder ab. | Vielversprechend – vor dem Handeln weiter untersuchen. |
| Associated | Der Effekt übersteht die Anpassung, aber der Graph ordnet die Regel nicht auf einem direkten Pfad zum Ergebnis an. | Reale Assoziation, aber wahrscheinlich indirekt – kann ein Stellvertreter für den eigentlichen Treiber sein. |
| Correlational | Es gibt eine Assoziation, aber wir können keinen kausalen Zusammenhang bestätigen. | Nur diagnostisches Signal – nicht allein danach handeln. |
Beispiel-Erzählung für eine Causal-Regel:
Channel = Online ist ein wahrscheinlicher Treiber für Non-First Contact Resolution. Fälle, die dieser Regel entsprechen, zeigen eine Ergebnisquote von 46,1 % gegenüber der Baseline von 29,0 % (1,59x, 95 % CI 1,51x – 1,68x, p < 0,001). Sie umfasst 2.518 Fälle und macht 34,7 % aller Vorkommen von Non-First Contact Resolution aus. Der Effekt hielt der Anpassung um andere Top-Treiber stand und liegt im gelernten Kausalgraphen auf einem direkten Pfad zum Ergebnis.
Die Ansicht Full Table ergänzt die vollständige Rangliste mit Abdeckung, Lift, Konfidenzintervall, bereinigtem Effekt, p-Wert und Badge für jede Regel, die die Suche und den Signifikanzfilter überstanden hat.
So funktioniert der Algorithmus
AI Causal Analysis führt eine fünfstufige Pipeline aus. Jede Stufe hat eine spezifische Aufgabe und ist so konzipiert, dass das Gesamtergebnis auch bei Datensätzen mit Millionen von Fällen in Sekunden vorliegt.
1. Vorbereitung und Binning
- Der Rechner kennzeichnet die Fälle in Ihrer Ergebnisgruppe mit
1; alle anderen werden mit0beschriftet. Das ist die Baseline-Rate, die Sie in der Ausgabe sehen. - Kategoriale Attribute (Strings, Booleans, Ganzzahlen mit niedriger Kardinalität) werden direkt verwendet. Jeder eindeutige Wert wird zu einem Kandidaten-Literal (z. B.
facility = Memorial). - Numerische und Datums-/Zeit-Attribute werden mit einem MDL-optimalen, ergebnisbewussten Binner in Bins eingeteilt. Statt gleich breiter oder gleich häufiger Bins wählt der Binner Schnittpunkte, die Ergebnis- und Nicht-Ergebnisfälle am besten trennen, und nutzt anschließend das Prinzip der Minimum Description Length (MDL), um die Anzahl der Bins automatisch zu bestimmen. Dadurch wird eine numerische Spalte wie
actual_los_daysin eine kleine Menge sinnvoller Buckets überführt (z. B.<= 3 Tage,4 – 7 Tage,> 7 Tage).
2. Bitmap-Indexierung
Jedes Literal wird als bitset gespeichert – ein Bit pro Fall, 1, wenn der Fall dem Literal entspricht. Die Kombination von Literalen mit AND wird zu einer schnellen bitweisen Schnittmenge:
facility = Memorial AND priority = Highwird alsbitset_A & bitset_Bberechnet.- Abdeckung, Ergebniszählung und Lift für eine Kandidatenregel können unabhängig von der Regeltiefe in Mikrosekunden ausgewertet werden.
Literale, die weniger als Min cases per rule abdecken, werden vor Beginn der Suche verworfen.
3. Beam-Search-Subgroup-Discovery
Der Rechner durchläuft den Raum der Regeln in Breitensuche:
- Tiefe 1: Bewerten Sie jedes einzelne Literal. Bewerten Sie es mit einem Qualitätsmaß (Lift und Weighted Relative Accuracy) und behalten Sie die besten
Beam width(Standard 50). - Tiefe 2: Erweitern Sie jede behaltene Regel mit jedem anderen kompatiblen Literal, um Konjunktionen wie
A AND Bzu bilden. Bewerten Sie alle und behalten Sie erneut die bestenBeam width. - Tiefe 3: Einmal mehr wiederholen. Stopp bei
Max rule depth.
Regeln, die unter Min lift oder Min cases per rule fallen, werden auf jeder Ebene beschnitten.
Nach der Suche entfernt ein Jaccard-Redundanzfilter nahezu identische Regeln: Wenn zwei Regeln im Wesentlichen dieselben Fälle abdecken (Überlappung über Redundancy Jaccard, Standard 0,9), wird nur die bessere behalten.
4. Statistische Signifikanz
Für jede überlebende Regel berechnet der Rechner:
- Das Risikoverhältnis (Ergebnisquote innerhalb der Regel geteilt durch Baseline-Rate) und dessen 95 % Wilson-Konfidenzintervall, das sich bei kleinen und extremen Wahrscheinlichkeiten gut verhält, bei denen die Normalapproximation versagt.
- Einen p-Wert unter der Nullhypothese, dass die Regel keinen Effekt hat.
- Eine Benjamini-Hochberg FDR-Korrektur über alle getesteten Regeln.
FDR alpha(Standard 0,05) legt die erwartete False-Discovery-Rate fest. Regeln, die die FDR nicht überstehen, werden nicht gemeldet – genau das verhindert, dass die Suche Sie in unechten Befunden ertränkt.
5. Kausale Beurteilung
Signifikanz allein sagt Ihnen nur, dass eine Assoziation besteht. Zwei zusätzliche Signale entscheiden, ob eine Regel ein Causal-Badge erhält:
- Kausalgraph-Signal – ein leichtgewichtiger bayes'scher Strukturscore, der aus den Attributen und dem Ergebnis gelernt wird. Er fragt: Liegt diese Regel im gelernten Graphen auf einem direkten Pfad zum Ergebnis oder nur auf einem indirekten Pfad über einen Confounder?
- Propensity-Score-Anpassung – eine ridge-regularisierte logistische Regression modelliert die Wahrscheinlichkeit, dass jeder Fall der Regel entspricht, gegeben alle anderen Top-Treiber. Der Effekt der Regel wird anschließend nach Gewichtung mit dieser Propensity neu geschätzt. Schrumpft der Effekt auf null, war die Regel nur ein Stellvertreter für andere Treiber; bleibt er bestehen, hat sie eigenständige Erklärungskraft.
Der Beurteiler kombiniert beide Signale zu den vier oben definierten Evidenz-Badges.
6. Erzählungsgenerierung
Der letzte Schritt komponiert den verständlichen Absatz, der in der Kartenansicht erscheint. Er verwebt die Regeldefinition, die Ergebnisquoten innerhalb der Regel und der Baseline, das Risikoverhältnis und das Konfidenzintervall, den p-Wert, die Abdeckung und das Evidenz-Badge zu einer Satzstruktur, die sich für einen nicht-statistischen Leser natürlich liest.
Performance
Gemessen auf einer Entwicklungsmaschine:
| Datensatz | Zeit |
|---|---|
| 100.000 Fälle x 4 Spalten | unter 1 Sekunde |
| 200.000 Fälle x 20 Spalten | unter 2 Sekunden |
| 1.000.000 Fälle x 50 Spalten | etwa 3 Sekunden |
Datensätze oberhalb der Sampling-Schwelle (Standard 2.000.000 Fälle) werden mit Floyds Kombinationsalgorithmus deterministisch gesampelt. Wenn dies geschieht, markiert die Ausgabe WasSampled = true und meldet die tatsächliche Stichprobengröße, sodass das Ergebnis reproduzierbar und das Sampling sichtbar ist.
Bekannte Einschränkungen (v1)
- Nur binäre Ergebnisse. Mehrklassige Ergebnisse (z. B. schnell / mittel / langsam) werden in dieser Version nicht unterstützt. Definieren Sie Zwei-Wege-Aufteilungen als separate Analysen.
- Noch keine Erklärungen pro Fall. v1 beantwortet "Was treibt dieses Ergebnis über den gesamten Datensatz hinweg?" Eine zukünftige Version wird Panels mit "Warum ging dieser spezifische Fall schief?" ergänzen.
- Keine Analyse zeitlicher Drifts. Wenn sich Treiber zwischen Quartalen ändern, wird v1 sie nicht über die Zeit aufspalten. Führen Sie den Rechner in diesem Fall für jede Zeitscheibe separat aus.
- Numerisches Binning ist ergebnisbewusst. Wenn Sie feste, manuell gewählte Bins möchten, bucketisieren Sie die Spalte vor dem Ausführen des Rechners mit einer Anreicherung vor.
Anwendungsfälle
Performance-Treiber
Identifizieren Sie die Attribute, die am stärksten mit Fällen verbunden sind, die einen SLA verletzen, das Budget überschreiten oder ihre erwartete Dauer überschreiten. Funktioniert gut mit einem Filter-Ergebnis auf Basis einer Dauer- oder KPI-Anreicherung.
Ergebnisanalyse
Vergleichen Sie erfolgreiche Fälle mit fehlgeschlagenen oder abgebrochenen. Verwenden Sie ein Filter-Ergebnis auf einem Status- oder Ergebnisattribut, um zu sehen, welche vorgelagerten Attribute welches Ergebnis vorhersagen.
Risiko und Compliance
Richten Sie den Rechner auf Fälle aus, die von einer Konformitäts- oder Kontrollanreicherung markiert wurden, um zu erfahren, welche Kontextfaktoren mit Compliance-Fehlern korrelieren.
Top-Performer-Analyse
Nutzen Sie den Top-N-%-Modus, um zu erklären, was Ihre besten Fälle, Teams oder Kunden vom Rest unterscheidet. Fließen Sie die Erkenntnisse in die Prozessgestaltung oder Schulung zurück.
Tipps
- Einfach beginnen. Ein gut gewählter Filter mit zwei oder drei Bedingungen plus automatisch ausgewählten Eingaben erzeugt meist die klarsten Ergebnisse.
- Beobachten Sie den Preview-Prozentsatz. Wenn die Ergebnisgruppe weniger als ~2 % oder mehr als ~50 % des Datensatzes umfasst, wird die Analyse schwerer zu interpretieren. Passen Sie den Filter an, bis die Gruppe eine sinnvolle Minderheit ist.
- Iterieren Sie über Eingabespalten. Entfernen Sie Spalten, deren Präsenz die Ergebnisse ohne Einsicht dominiert (IDs, Zeitstempel, die das Ergebnis verraten), und führen Sie den Rechner erneut aus.
- Benennen Sie Ergebnisse konkret.
Long CasesschlägtOutcome 1, wenn Sie Ergebnisse mit Stakeholdern teilen oder in Berichte einfließen lassen. - Kombinieren Sie mit dem Entscheidungsbaum-Rechner für eine zweite Sicht auf dieselbe Frage. Der Entscheidungsbaum zeigt die Verzweigungsstruktur; AI Causal Analysis bewertet den Gesamteinfluss der Merkmale.
Verwandte Rechner
- Decision Tree – ergänzende Sicht, die zeigt, wie Attribute Fälle in Ergebnisgruppen aufteilen
- Root Cause Analysis – deterministische statistische Ursachenforschung für KPI-Abweichungen
- Case Outcome By Category – Vergleich von Ergebnisraten über ein gewähltes kategoriales Attribut
Verwandte Funktionen
- AI Studio (Alpha) – der umfassendere Arbeitsbereich für prädiktive Analytik, inklusive Feature Impact und Root Cause
- Alpha Features Overview – vollständige Liste der Funktionen im mindzie Alpha-Programm
Feedback geben
AI Causal Analysis ist eine Alpha-Funktion und Ihr Input beeinflusst direkt, wie sie sich entwickelt:
- E-Mail: support@mindzie.com
- Betreff: Einschließen
Alpha Feedback: AI Causal Analysis - Inhalt: die verwendete Ergebnis-Definition, die Eingabespalten, was Sie erwartet haben und was Sie bekommen haben