Datenarchitektur
Die Datenarchitektur zeigt, wie Prozessdaten in mindzieStudio fließen, durch Anreicherung transformiert werden und exportiert oder zur Auslösung automatisierter Aktionen verwendet werden können. Das Verständnis dieser Datenwege hilft Ihnen, effektive Datenintegrationsstrategien zu entwerfen.
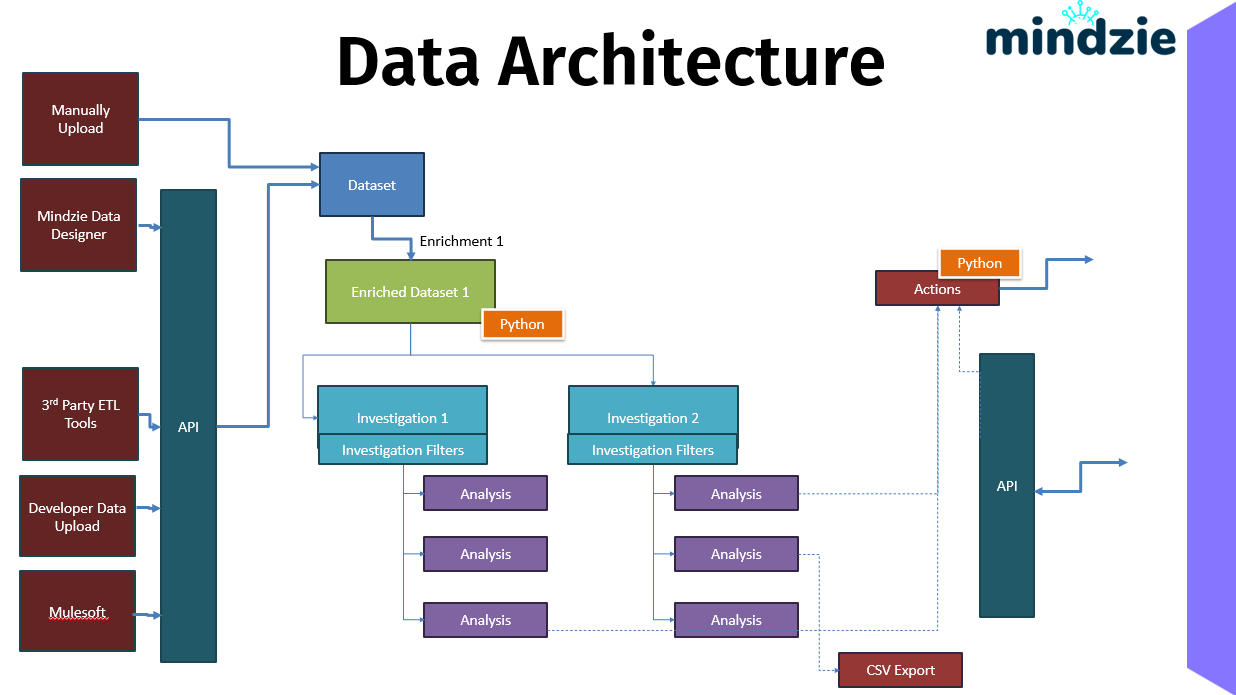
Überblick
mindzieStudio unterstützt mehrere Methoden zur Dateneingabe, eine zentrale API-Schicht und verschiedene Ausgabeoptionen. Diese flexible Architektur ermöglicht es Ihnen, Process Mining in Ihr bestehendes Datenökosystem zu integrieren.
Datenquellen
Es gibt mehrere Möglichkeiten, Prozessdaten in mindzieStudio einzubringen:
Manueller Upload
Der einfachste Ansatz ist das direkte Hochladen von Dateien über die mindzieStudio-Oberfläche. Unterstützte Formate sind:
- CSV-Dateien: Standardmäßig durch Kommas getrennte Werte
- Excel-Dateien: .xlsx-Tabellen
- Parquet-Dateien: Spaltenorientiertes Speicherformat für große Datensätze
- ZIP-Archive: Komprimierte Pakete mit mehreren Dateien
Der manuelle Upload eignet sich ideal für Ad-hoc-Analysen, Proof-of-Concept-Projekte oder wenn Daten bereits aus Quellsystemen exportiert wurden.
mindzie Data Designer
mindzie Data Designer ist ein visuelles Tool, das direkt an Ihre Quell-Datenbanken und Systeme angeschlossen wird. Es ermöglicht Ihnen:
- Visuelle Definition von Datenschemata
- Zuordnung von Quellspalten zum Event-Log-Format
- Planung automatisierter Datenaktualisierungen
- Transformation der Daten während der Extraktion
Data Designer unterstützt Verbindungen zu wichtigen Datenbanken wie SQL Server, Oracle, PostgreSQL, MySQL, SAP HANA und vielen weiteren.
ETL-Tools von Drittanbietern
Wenn Ihre Organisation bereits über ETL-Infrastruktur (Extract, Transform, Load) verfügt, können Sie mindzieStudio über standardisierte Datenpipelines integrieren. Dieser Ansatz nutzt Ihre bestehenden Data-Engineering-Fähigkeiten und Governance-Prozesse.
Entwickler-Daten-Upload
Für den programmgesteuerten Zugriff erlaubt die mindzieStudio API Entwicklern:
- Datensätze über HTTP-Endpunkte hochzuladen
- Datenaktualisierungen aus benutzerdefinierten Anwendungen zu automatisieren
- Integration in CI/CD-Pipelines
- Erstellung benutzerdefinierter Datenkonnektoren
Dies ist ideal für Organisationen, die automatisierte Datenpipelines aufbauen oder Process Mining in größere Systeme integrieren.
Mulesoft-Integration
Unternehmen, die Mulesoft für die Integration verwenden, können mindzieStudio als API-Endpunkt in ihre Integrationsabläufe einbinden. Dies ermöglicht den Fluss von Prozessdaten als Teil Ihrer umfassenderen Unternehmensintegrationsstrategie.
API
Die API dient als zentraler Zugangspunkt für alle Datenbewegungen in mindzieStudio. Alle Daten – egal ob manuell hochgeladen oder automatisiert – fließen durch die API-Schicht.
Die API bietet:
- Authentifizierung: Sicherer Zugriff über Bearer-Tokens
- Validierung: Überprüfung von Datenformat und Schema
- Routing: Weiterleitung der Daten an die passenden Verarbeitungskomponenten
- Zugriffskontrolle: Mandanten- und Projektebene-Berechtigungen
Die API ist in den Enterprise Server- und SaaS-Editionen von mindzieStudio verfügbar.
Datensatz
Sobald Daten in mindzieStudio gelangen, werden sie als Datensatz gespeichert. Datensätze sind:
- Komprimiert: Effizientes binäres Speicherformat
- Validiert: Überprüfung auf erforderliche Spalten und Datentypen
- Versioniert: Vorherige Uploads können zum Vergleich vorgehalten werden
Jeder Datensatz muss die drei Kernspalten des Event-Logs enthalten:
- Case ID (Bezeichner für jede Prozessinstanz)
- Aktivität (Name jedes Schritts)
- Zeitstempel (Zeitpunkt, zu dem jeder Schritt erfolgte)
Weitere Attributspalten können beliebige geschäftsrelevante Daten enthalten.
Anreicherung mit Python
Die Anreicherungsschicht transformiert rohe Datensätze in analysebereite Daten. Anreicherungen können beinhalten:
- Eingebaute Transformationsoperatoren
- Benutzerdefinierte Python-Skripte für fortgeschrittene Logik
- Berechnung von Geschäftsregeln
- Korrekturen der Datenqualität
Python-Integration ermöglicht es Ihnen:
- Benutzerdefinierte Transformationslogik zu schreiben
- Python-Datenwissenschaftsbibliotheken zu nutzen
- Wiederverwendbare Transformationsskripte zu erstellen
- Komplexe Datenmanipulationsszenarien zu bewältigen
Anreicherungen laufen im Hintergrund und cachen ihre Ergebnisse für schnellen Zugriff während der Analyse.
Untersuchung und Analyse
Die Untersuchungsschicht ist der Ort der Analyse. Innerhalb von Untersuchungen können Sie:
- Untersuchungsfilter anwenden, um sich auf bestimmte Datensubsets zu konzentrieren
- Analyse-Notebooks mit geordneten Blöcken erstellen
- Erkenntnisse mit Kalkulatoren generieren
- Visualisierungen erstellen
Analyseergebnisse werden zwischengespeichert und können bei Aktualisierung der Quelldaten erneuert werden.
Ausgabe und Integration
mindzieStudio bietet mehrere Möglichkeiten, Daten zu exportieren und in externe Systeme zu integrieren:
Aktionen
Aktionen sind automatisierte Workflows, die zeit- oder ereignisgesteuert ausgeführt werden. Aktionen können:
- Python-Skripte für benutzerdefinierte Verarbeitung ausführen
- Externe HTTP-APIs aufrufen
- Daten an externe Systeme exportieren
- Mehrere Schritte miteinander verketten
- Fehler mit Fallback-Aktionen behandeln
Aktionen ermöglichen die operative Integration, bei der Prozesskennzahlen reale Reaktionen auslösen.
API-Export
Externe Systeme können mindzieStudio über die API abfragen, um:
- Analyseergebnisse programmgesteuert abzurufen
- Dashboard-Daten in andere Anwendungen zu ziehen
- Prozesskennzahlen in Berichtssysteme zu integrieren
- Operative Dashboards in externen Tools zu betreiben
CSV-Export
Für einfachen Datenaustausch können Analyseergebnisse als CSV-Dateien heruntergeladen werden. Das ist nützlich, um:
- Daten mit Stakeholdern zu teilen, die keinen Zugang zu mindzieStudio haben
- Daten in Tabellenkalkulationstools zu laden
- Sicherungskopien von Analyseergebnissen zu erstellen
Zusammenfassung des Datenflusses
Der vollständige Datenfluss durch mindzieStudio:
- Eingabe: Daten gelangen über manuellen Upload, Data Designer, ETL-Tools, API oder Mulesoft hinein
- Gateway: Die API validiert, authentifiziert und leitet die Daten weiter
- Speicherung: Daten werden als komprimierte Datensätze gespeichert
- Transformation: Anreicherungen (optional mit Python) bereiten die Daten auf
- Analyse: Untersuchungen und Notebooks erzeugen Erkenntnisse
- Ausgabe: Ergebnisse fließen zu Aktionen, API-Verbrauchern oder CSV-Exporten
Diese Architektur unterstützt sowohl interaktive Analysen als auch automatisierte betriebliche Workflows und macht mindzieStudio sowohl für Ad-hoc-Erkundungen als auch für die Produktion von Prozessmonitoring geeignet.